Creating Teradata Source
For creating a Teradata source, see Creating Source. Ensure that the Source Type selected is Teradata.
Configuring Teradata Source
For configuring a Teradata source, see Configuring Source.
Teradata Configurations
| Field | Description |
|---|---|
| Fetch Data Using | The mechanism through which Infoworks fetches data from the database. The option includes JDBC and TPT. For details on TPT ingestion, see Teradata TPT Ingestion. |
| Connection URL | The connection URL through which Infoworks connects to the database. Sample format: jdbc:teradata://<ip>/TMODE=<tmode>,database=<databasename> |
| Username | The username for the connection to the database. |
| Password | The password for the username provided. |
| Source Schema | The schema in the database to be crawled. The schema value is case sensitive. |
Once the setting is saved, you can test the connection or navigate to the Source Configuration page to crawl the metadata.
Crawling Teradata Metadata
For crawling the metadata of a Teradata source, see Crawling Metadata.
Configuring Teradata Source for Ingestion
For configuring a Teradata source for ingestion, see Configuring Source for Ingestion.
Ingestion Configurations
| Field | Description |
|---|---|
| Ingest Type | The types of synchronization that can be performed on the table. The options include Full Load, Timestamp-Based Incremental Ingestion, Query Based Incremental Ingestion, Batch ID Based Incremental Ingestion. |
| Segmented Load Status | The option to crawl large tables by breaking into smaller chunks. The smaller chunks can be crawled in parallel. Select the column to Perform Segmented Load On. To derive a column, check the Use substring from field option and select the Extract function. NOTE: New columns can be extracted only for date, datetime, timestamp column types. The possible extraction options are year, month, year-month, month-day and day-num-in-month. After completing the segmented load, ensure to set this value to Completed to submit incremental load or full load jobs. |
| Crawl a subset of data | The option to crawl a subset of data based on the filter configured. For details, see Filter Query for Teradata Sources. |
Source Configuration | |
| Natural Keys | The key to identify the row uniquely. This key is used to identify and merge incremental data with the existing data on the target. Distribution of data into secondary partitions for a table on target will be computed based on the hashcode value of the natural key. This field is mandatory for incremental ingestion tables. NOTE: The value of natural key column cannot be updated when updating a row on source; all the components of the natural key are immutable. |
| Lock row for access | The option to enable lock row for access hint on Teradata select query. |
| Split by | The option to crawl the table in parallel with multiple connections to the database. Split-by column can be an existing column in the data or derived from an existing column. Any column for which minimum and maximum values can be computed can be a split-by key (numbers, date, datetime, timestamp). To derive a column, check the Use substring from field option and select the Extract function. |
Synchronization Configuration | |
| CDC Start Date | The option to fetch a specific portion of the delta, based on the time window. The start date of the time window. |
| CDC End Date | The option to fetch a specific portion of the delta, based on the time window. The end date of the time window. |
| Enable Schema Synchronization | The option to synchronize the Hive table schema, if the source table is modified after the table ingestion is complete. |
| Timestamp-Based Incremental Load | |
| Timestamp Column for Insert | The source column to be used as insert watermark. |
| Timestamp Column for Update | The source column to be used as update watermark. NOTE: It can also be the source column to be used as insert watermark. |
| Query-Based Incremental Load | |
| Slowly Changing Dimension Type | The type of the query based ingestion. The options include SCD Type 1 and SCD Type 2. NOTE: SCD Type 1 always overwrites the existing record in case of updates. |
| Configure Insert Query | The option to input the query which identifies and fetches the incremental insert records from the source table, using the record insertion row from the audit table. |
| Join Column for Insert | The column used to identify the inserts. This column will be joined with audit table column. This field uses source datatype. |
| Configure Update Query | The option to input the query which identifies and fetches the incremental update records from the source table, using the record update row from the audit table. |
| Join Column for Update | The column used to identify the updates. This column will be joined with audit table column. |
| External Audit Schema Name | The schema name of the audit table where the timestamps are being stored. |
| External Audit Table Name | The name of the audit table where the timestamps are being stored. |
| External Audit Join Column | The column by which the data table and the audit table will be joined. |
| External Audit Timestamp Column | The timestamp column in the audit table, which maintains record audit. |
| BatchID-Based Incremental Load | |
| Batch-ID Column | This column used for fetching of delta. This column must be a numeric column. Source datatype and target datatype must be equal. |
| Start Batch Id | The numeric value of Batch ID column (configured by the user during table configurations) starting which the delta is fetched. |
| End Batch Id | Numeric value of Batch ID column (configured by the user during table configurations) till which the delta is fetched. |
Target Configuration | |
| Hive Table Name | The name of the table in Hive which will be used to access the ingested data. |
| Storage Format | The format of the data file to be stored in HDFS. The options include ORC and Parquet. |
| Partition Hive Table | The option to partition the data in target. The partition column also can be derived for date, datetime and timestamp column. This will further partition the data. A hierarchy of partitions are supported with both normal partitions and derived partitions. NOTES: Ensure that the partition columns data is immutable. You can also provide a combination of normal and derived partitions in the hierarchy. |
| Number of Secondary Partitions | The number of secondary partitions to run the MR jobs in parallel. The target data can be distributed among various partitions and each partitions in turn can have various secondary partitions. A table with no primary partition can also have secondary partitions. Secondary partition helps in parallelising the ingestion process. |
| Number of Reducers | The number of reducers for the ingestion map reduce job. Increasing the number of reducers helps reduce the ingestion duration. This will help in processing the MR jobs faster. This will be effective with the combination of partition key and number of secondary partitions. In any data processing using MR job, this will help in bringing the parallelism based on the data distribution across number of primary partitions and secondary partitions on Hadoop. |
| Generate History View | The option to create history view table (along with the current view table) in Hive, which contains the versions of incremental updates and deletes. |
| Number of Secondary Partitions to Merge in Parallel | The number of secondary partitions that can be merged in parallel for a table. |
Filter Query for Teradata Sources
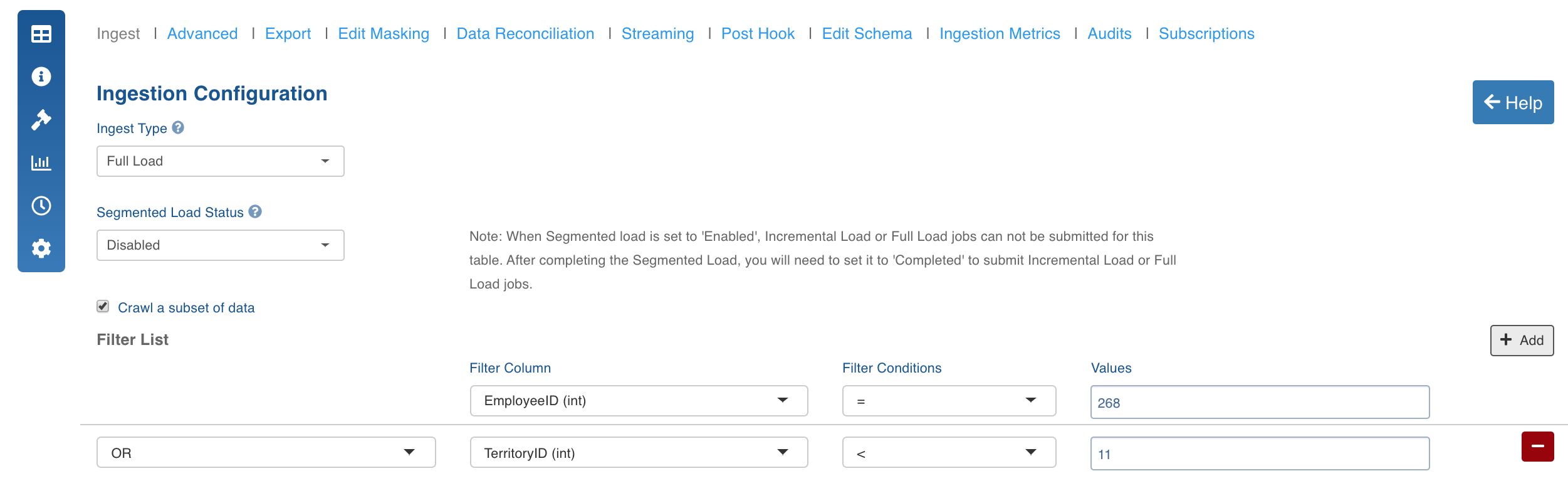
You can specify complex filter conditions to extract a subset of data from Teradata source tables using the Crawl a subset of data option in the Table Configuration page. This option is used to crawl a subset of data based on the filter configured.
The filter options include the following:
- Filter Column: The column to be filtered.
- Filter Conditions: The filter operator.
- Values: The comparison value.
You can click the Add button to add more filter combinations. The combine conditions include AND and OR.
NOTES:
- Once the table is ingested, the filter conditions configured cannot be modified.
- The filter condition must not be defined on the watermark column.
References
Teradata Datatypes
For details, see Teradata Data Types.