JSON ingestion supports the following features:
Schema crawl
Data Crawl
Append Mode
CDC and Merge
Reference Video
The demo video of JSON Ingestion is available here.
Creating JSON Source
For creating a JSON source, see Creating Source. Ensure that the Source Type selected is JSON.
Configuring JSON Source
For configuring a JSON source, see Configuring Source.
NOTE: If the source is ECB enabled, the From Filesystem option will be selected by default and the other options will be disabled.
Enter the source base path.
In Record Scope field, select Line if the files have one JSON record per line or select File if all the files are valid JSONs themselves.
To skip processing of some files in the folder, provide a regex in Exclude files containing pattern. File paths having this regex will be skipped.
Check Ingest sub-directories to crawl each file present in the File System tree where the source base path is the root. Character Encoding takes the charset encoding of your JSON files.
Select the ECB Agent, if the source is ECB enabled.
NOTE: If you choose From Cloud Storage select the Cloud Type:
Google cloud service: Select the Service Account Type, copy the Service Account JSON Credentials File to the edge node and provide the path.
S3: Select the Access Type. If you choose Use IAM, ensure that the Edge node runs with the same IAM role and has access to the S3 bucket. If you choose Use Access Credentials, provide the access credentials of S3 bucket.
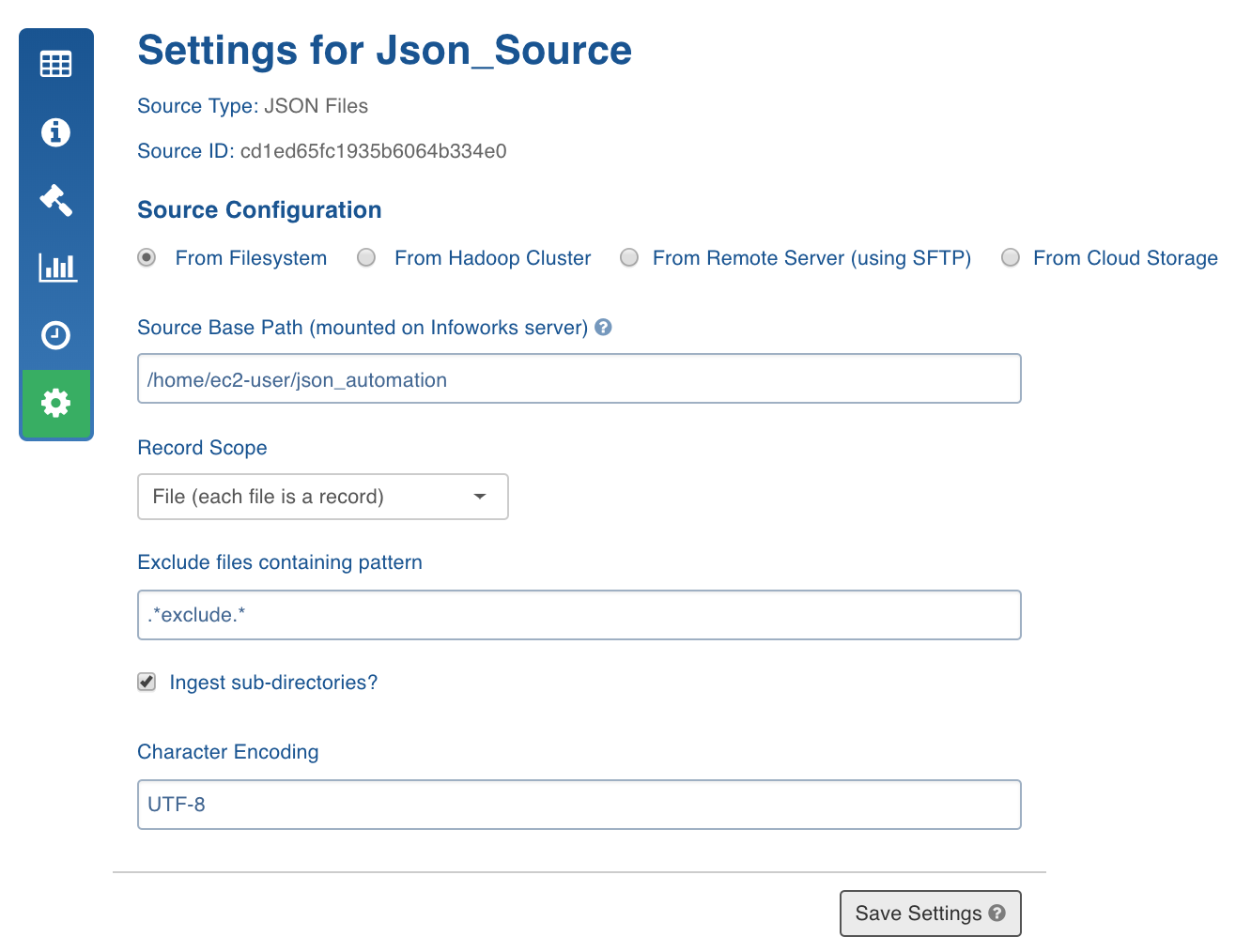
Click Save Settings.
Creating Table and Crawling Schema
Following are the steps to detect the schema of the JSON:
Click the Source Configuration icon.
NOTE: For ECB enabled source, click Fetch Sample Schema button. This copies the sample files from the ECB agent host to the cloud storage which can be accessed by the Infoworks edge node.
Click Configure Mapping.
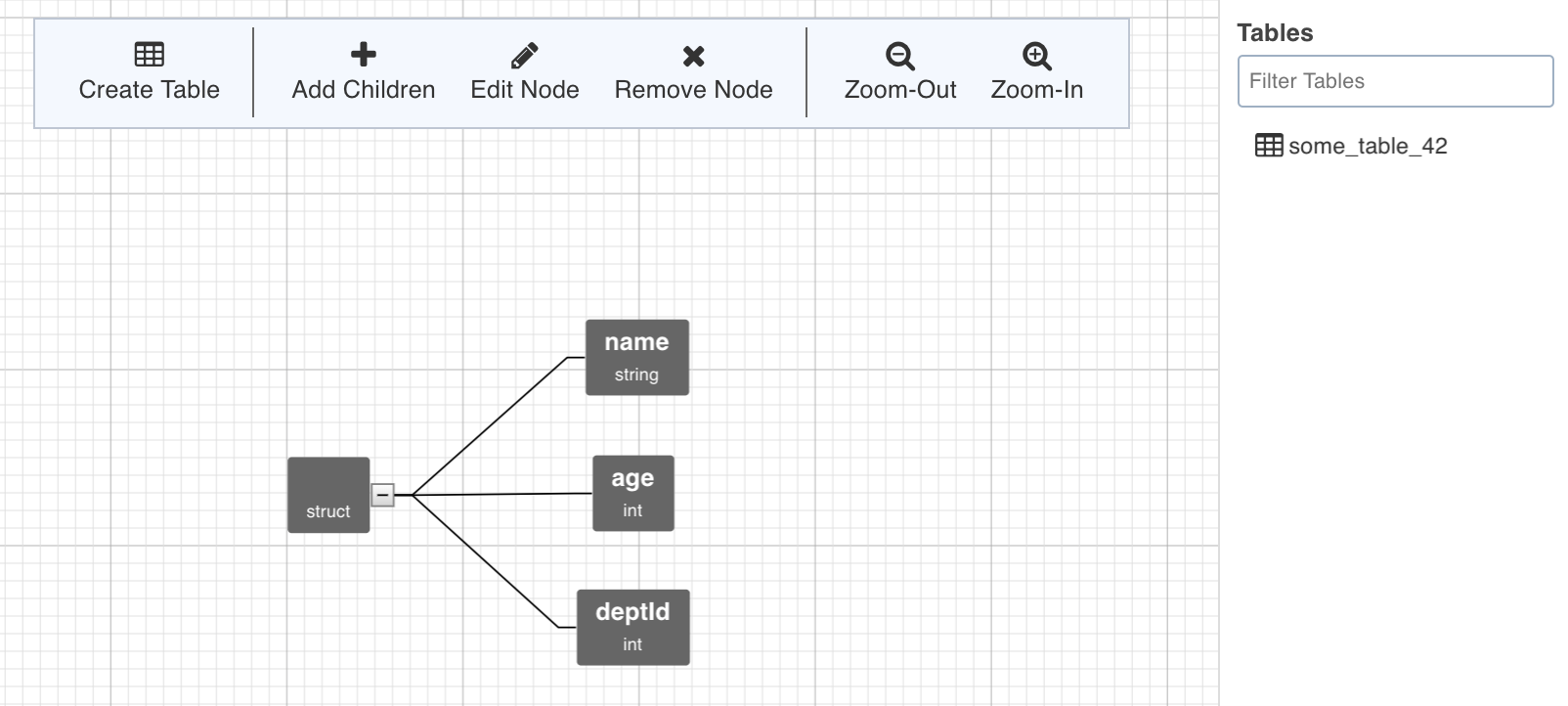
A tree representing the JSON schema created by crawling a configurable number of records is displayed which is an admin configuration with the key JSON_TYPE_DETECTION_ROW_COUNT. For adding children nodes, see Adding Children Nodes.
Click Crawl Source for Schema to crawl the schema from a specific file.
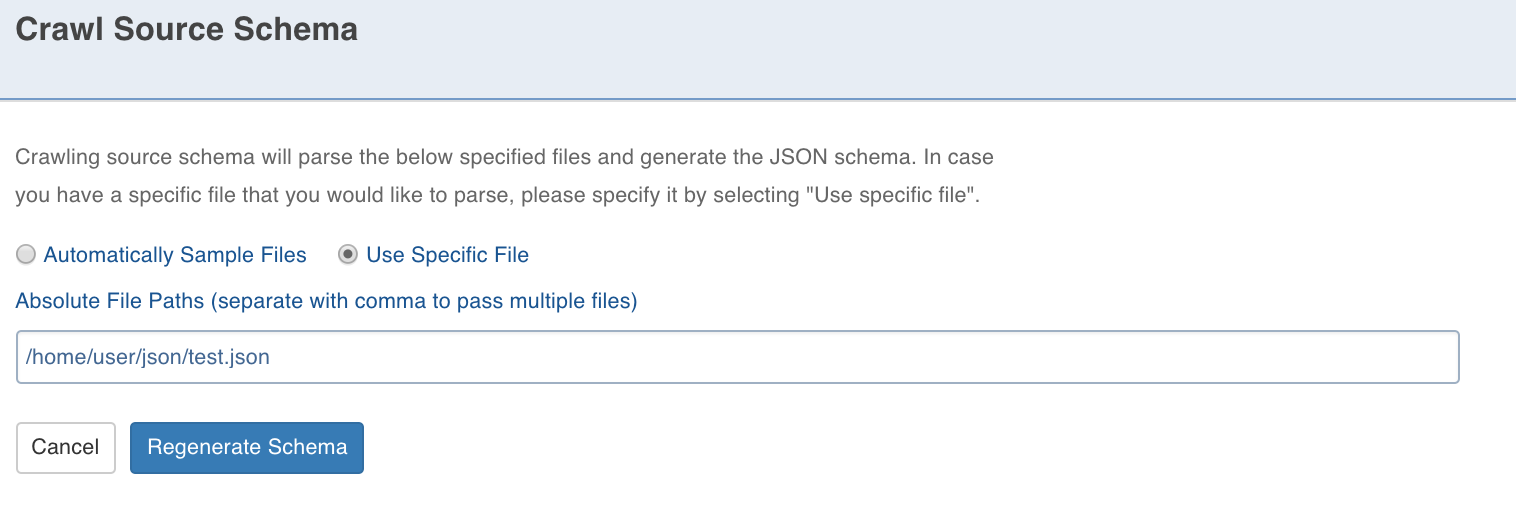
You can provide a comma-separated list of the files you want to use for schema detection. In the Source Schema Editor page, you can add new nodes, edit the current nodes and remove the added nodes (only). After editing the tree, you can move to table creation.
NOTE: Table can be created by selecting a path from the tree. The path in this case is a group of single or multiple contiguous nodes without any branches. The path nodes can only be of type array or struct.
Select the path and click Create Table. This creates a table schema out of all the non-path child nodes of the nodes present in the path.
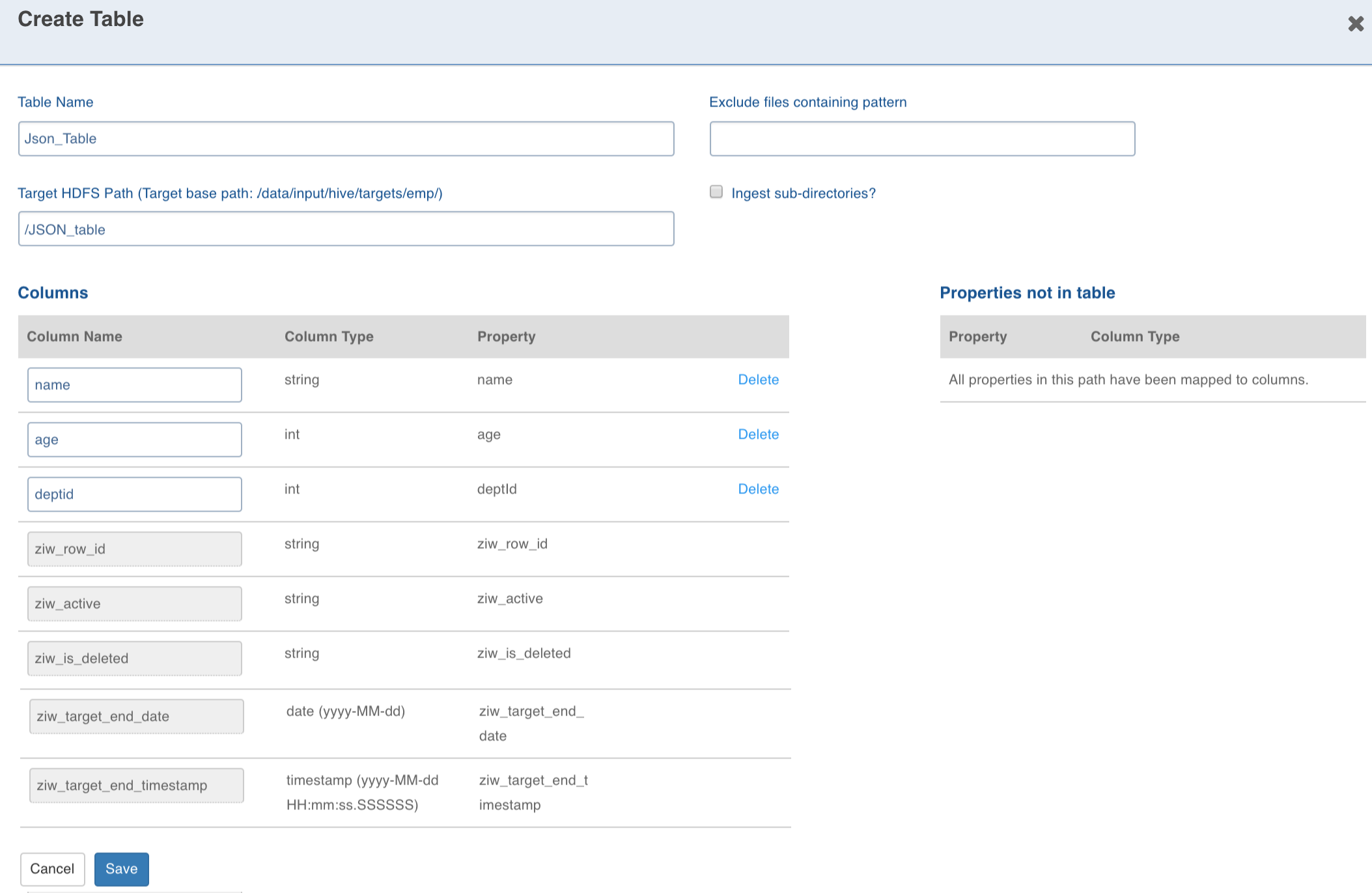
Enter the target Hive Table Name, Target HDFS Path (this is relative to the source target base path entered during source creation).
NOTE: The Exclude files containing pattern and Ingest sub directories options override the source level settings of the same names. The columns can be deleted and added again.
Configuring the columns and click Save.
NOTE: To recrawl ECB enabled source, ensure you click Fetch Sample Data in the Source Configuration page to get the new files from the ECB agent into the cloud storage. And then, click the Configure Mapping button and click the (Re)crawl Source for Schema button to get the new schema from the new files in cloud storage.
Adding Children Nodes
If a crawled schema has a missing Node/JSON field, you can add a child node to the Struct node where the field is missing. You can use this child node in any table that you create.
Following are the steps to create a child node:
Click the required node with type struct and click the Add Children option.
Enter the Property Name and Datatype (also, Format/Scale, Precision if applicable).
Click the Add Children button. The node will be added to the tree.
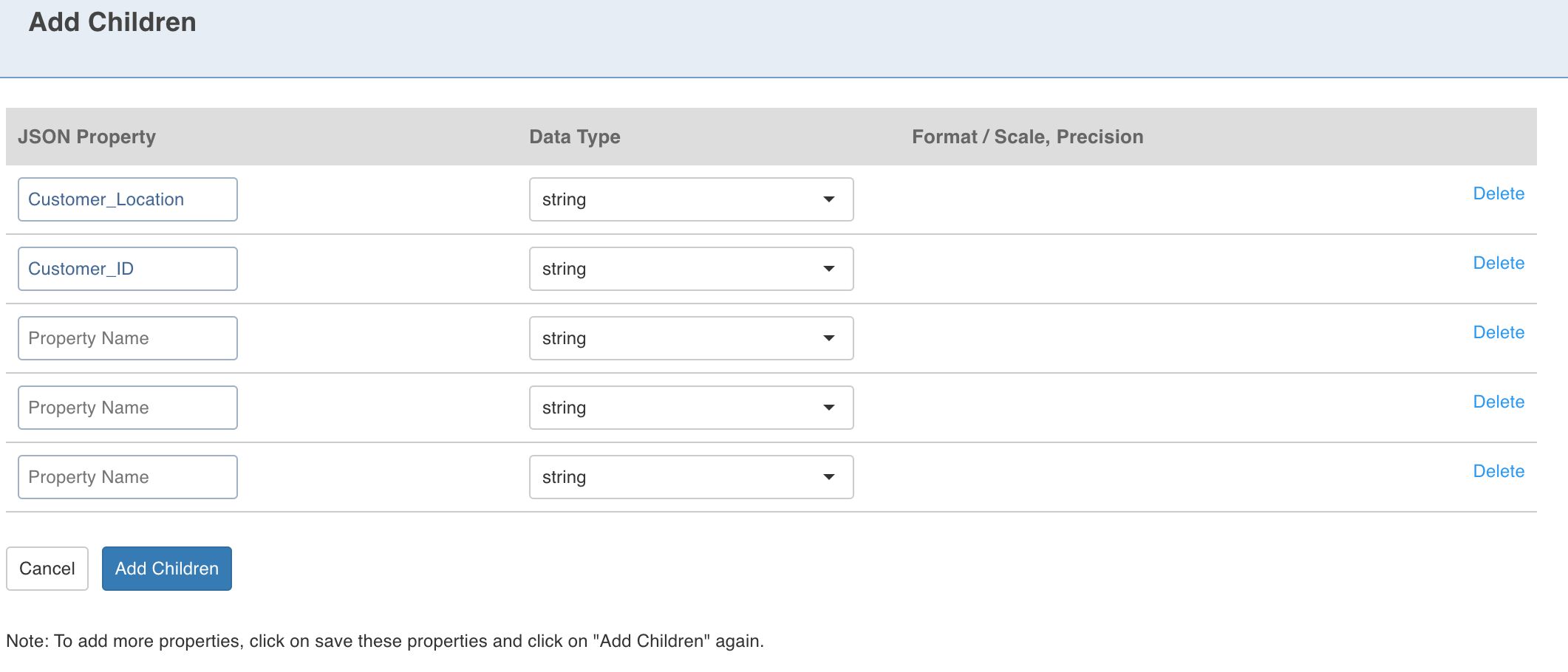
You can also click Edit Node to edit the property details and Remove Node to delete the node.
Configuring JSON for Ingestion
For configuring a JSON source for ingestion, see Configuring Source for Ingestion.
JSON Configurations
JSON_ERROR_THRESHHOLD: If the number of error records increases this threshold, the MR job fails. The default value is 100.
JSON_KEEP_FILES: If the host type is local before the MR job runs, the CSV files are copied to the tableId/CSV directory. If this value is true, the files are not deleted after the crawl. The default value is true.
JSON_TYPE_DETECTION_ROW_COUNT: Number of rows to be read for type detection/metacrawl. The default value is 100.
json_job_map_mem: Mapper memory for the crawl map reduce. The default value is the value of iw_jobs_default_mr_map_mem_mb in properties.
json_job_red_mem: Reducer memory for the crawl map reduce. The default value is the value of iw_jobs_default_mr_red_mem_mb in properties.
Known Issues
The path cannot have branches. Workaround: Create different tables for each branch, if needed.
While extracting table from the JSON, you cannot eliminate the records with duplicate natural keys. Workaround: Ensure that the natural key provided is unique.
While creating table from UI, you cannot inspect and delete the hierarchy of the complex (struct and array) data types.
The supported character encodings are UTF-8, ASCII and ISO-8859-1.
Phoenix export fails for table names starting with special characters.