MongoDB is an open source database management system (DBMS) that uses a document-oriented database model which supports various forms of data.
Creating MongoDB Source
For creating a MongoDB source, see Creating Source. Ensure that the Source Type selected is MongoDB. The target Hive schema is where the Hive tables will be created corresponding to each Mongo DB table.
Configuring MongoDB Source
For configuring an MongoDB source, see Configuring Source.
Field | Description |
|---|---|
Connection URL | The URL for Infoworks DataFoundry to connect to the database. The URL must include the port in the following format: |
Auth Mechanism | The authentication mechanism to connect to the Mongo DB server. The options include MONGODB-CR, SCRAM-SHA-1, SCRAM-SHA-256. |
Username | The username of the target database. |
Password | The password of the target database. |
Database Name | The name of the target database. |
Click Save Settings and perform a test connection. Ensure the test connection is successful and perform the collection crawl.
Collection Crawl
In MongoDB, databases hold collections of documents. MongoDB stores documents in collections. Collections are analogous to tables in relational databases and each document is analogous to record in table. By default, a collection does not require its documents to have the same schema which implies it is not necessary for the documents in a single collection to have the same set of fields and, data type for a field can differ across documents within a collection.

Click the Source Configuration menu (grid icon) and navigate to the Collections tab.
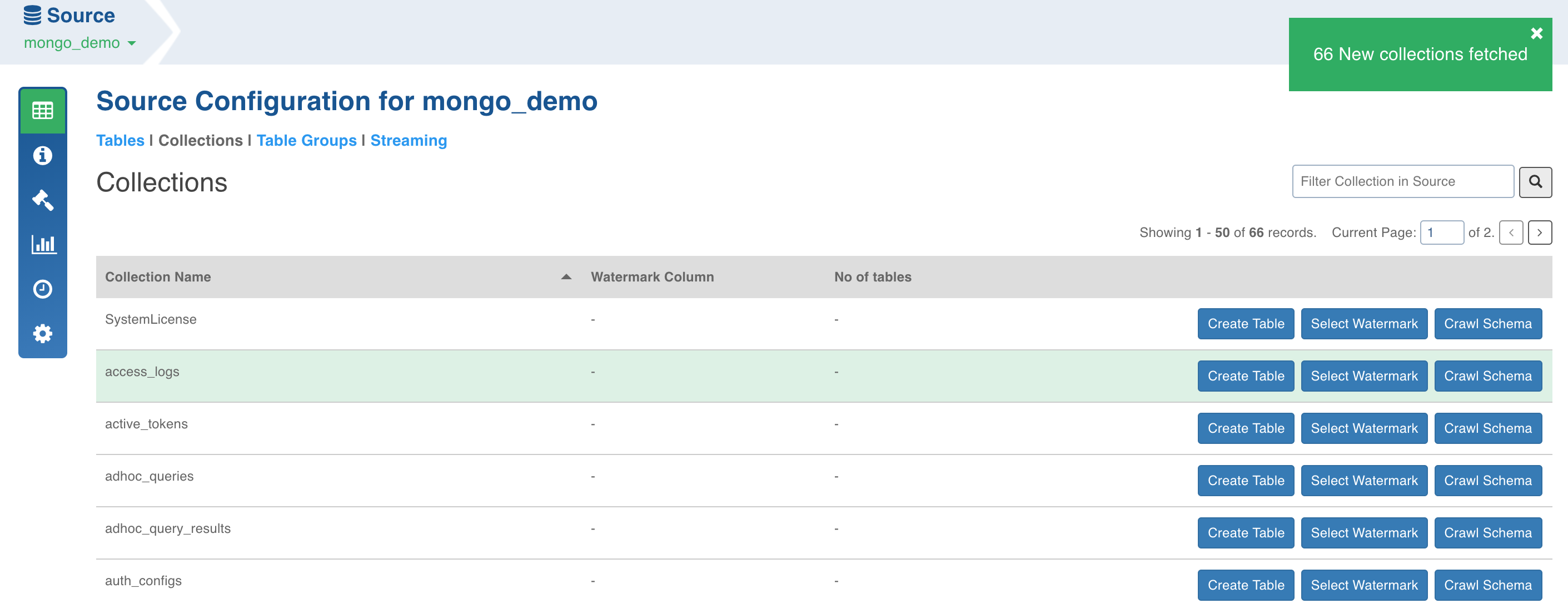
Click the Fetch Collections button. The collections from the database will be fetched.
Schema Crawl for Collection
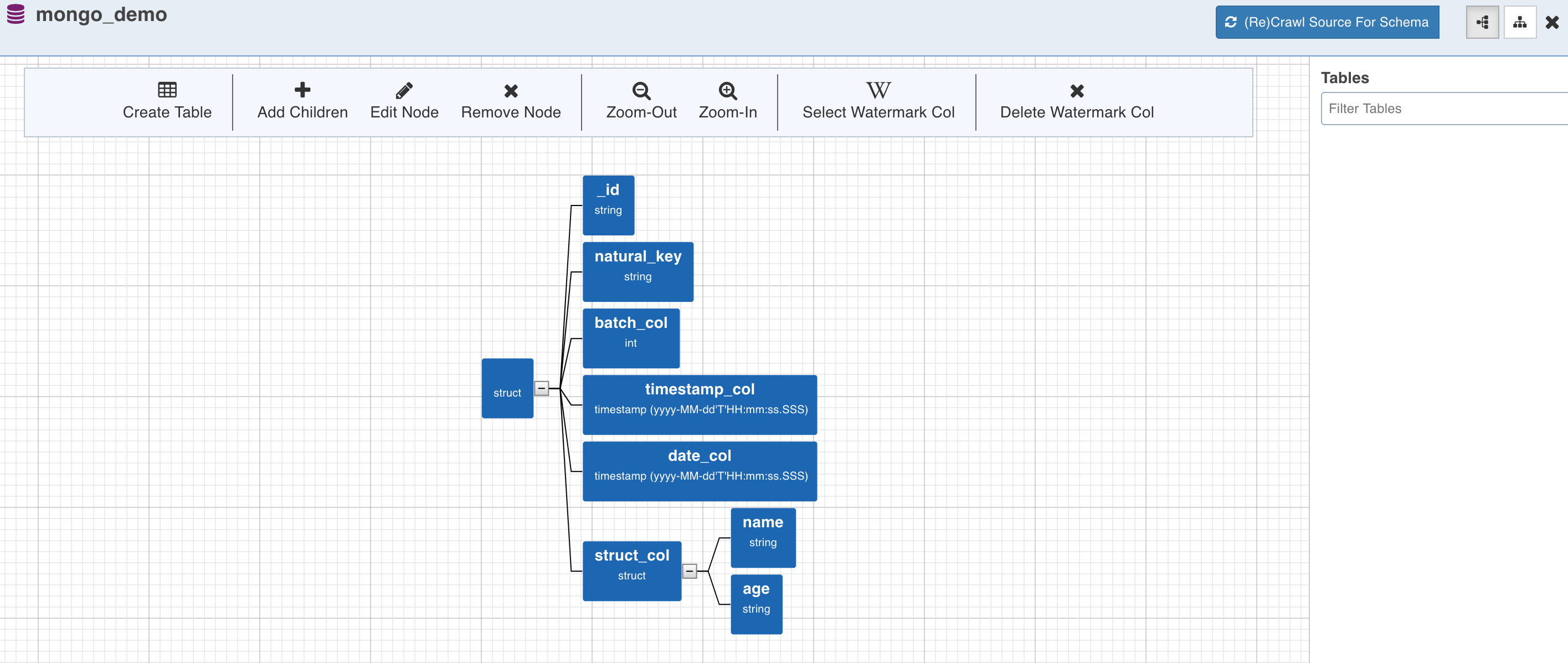
Click the Crawl Schema button for the collection from which the tables must be created. The tree structure will be displayed, which is a unified schema of all the documents present in the specified collection.
Watermark Column Selection
To perform incremental ingestion for the tables created from the collection, select the watermark column by clicking on the required node and click the Select Watermark Col (W) option. Skip this step to perform only full ingestion.
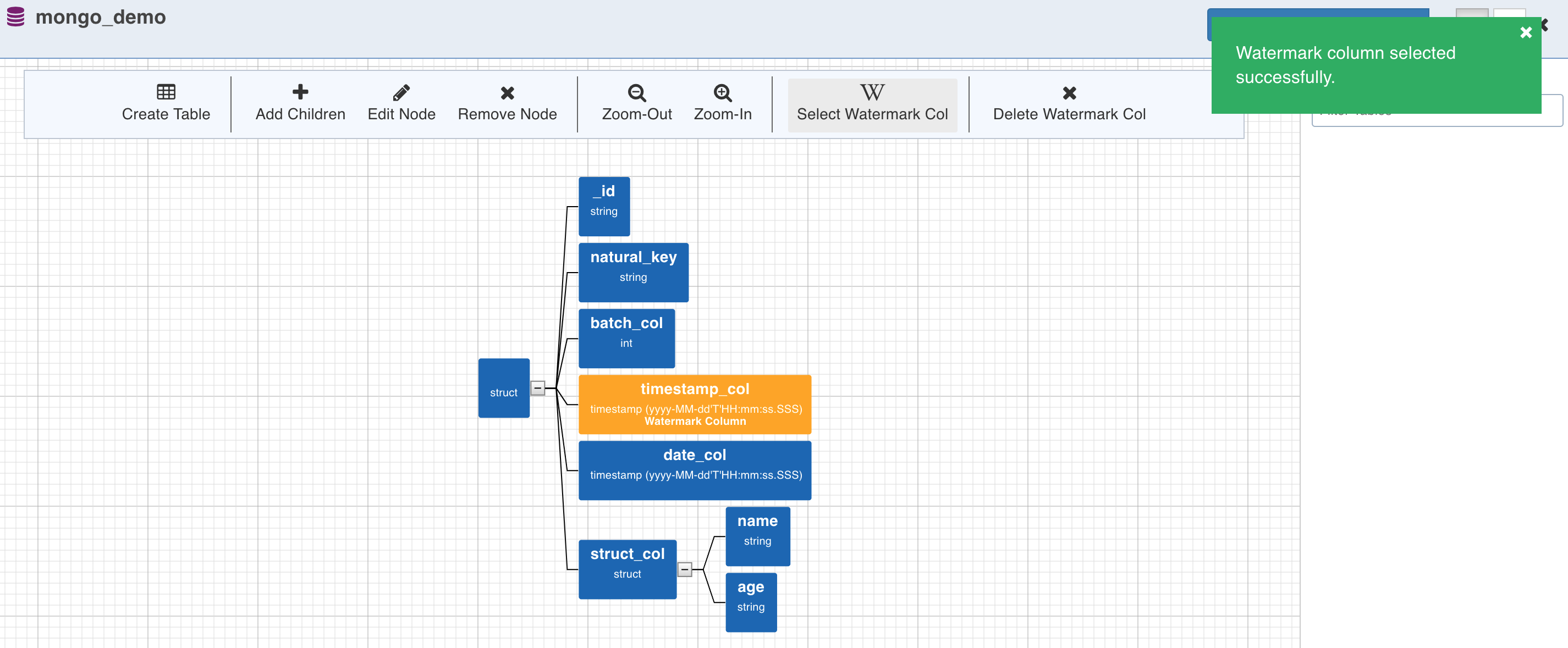
Table Creation
Table can now be created by selecting a path from the tree. The path in this case is a group of single or multiple contiguous nodes without any branches. The path nodes can only be of type array or struct.
Select the path and click Create Table. This creates a table schema out of all the non-path child nodes of the nodes present in the path along with the watermark column selected for the collection.
NOTE: If you create a table without selecting a watermark column for the collection, the following message will be displayed:

To create only full load table (complete refresh every time), click Yes, Create Table Without Watermark Column. Else, click Cancel and select the watermark column for the collection.
Enter the target Hive Table Name, Target HDFS Path (this is relative to the source target base path entered during source creation).
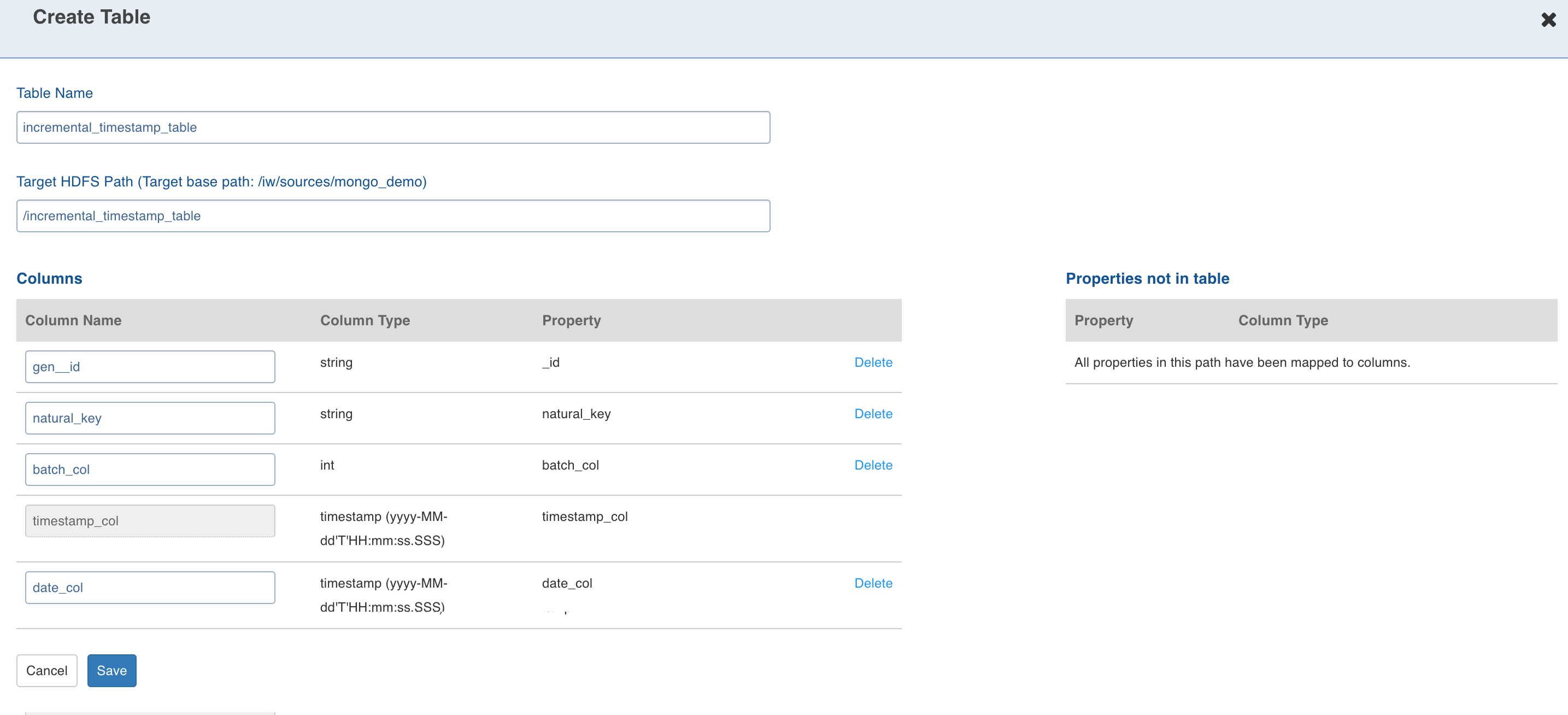
Configuring the columns and click Save.
Data Crawl Full Load
Following are the steps to perform a full load data crawl:
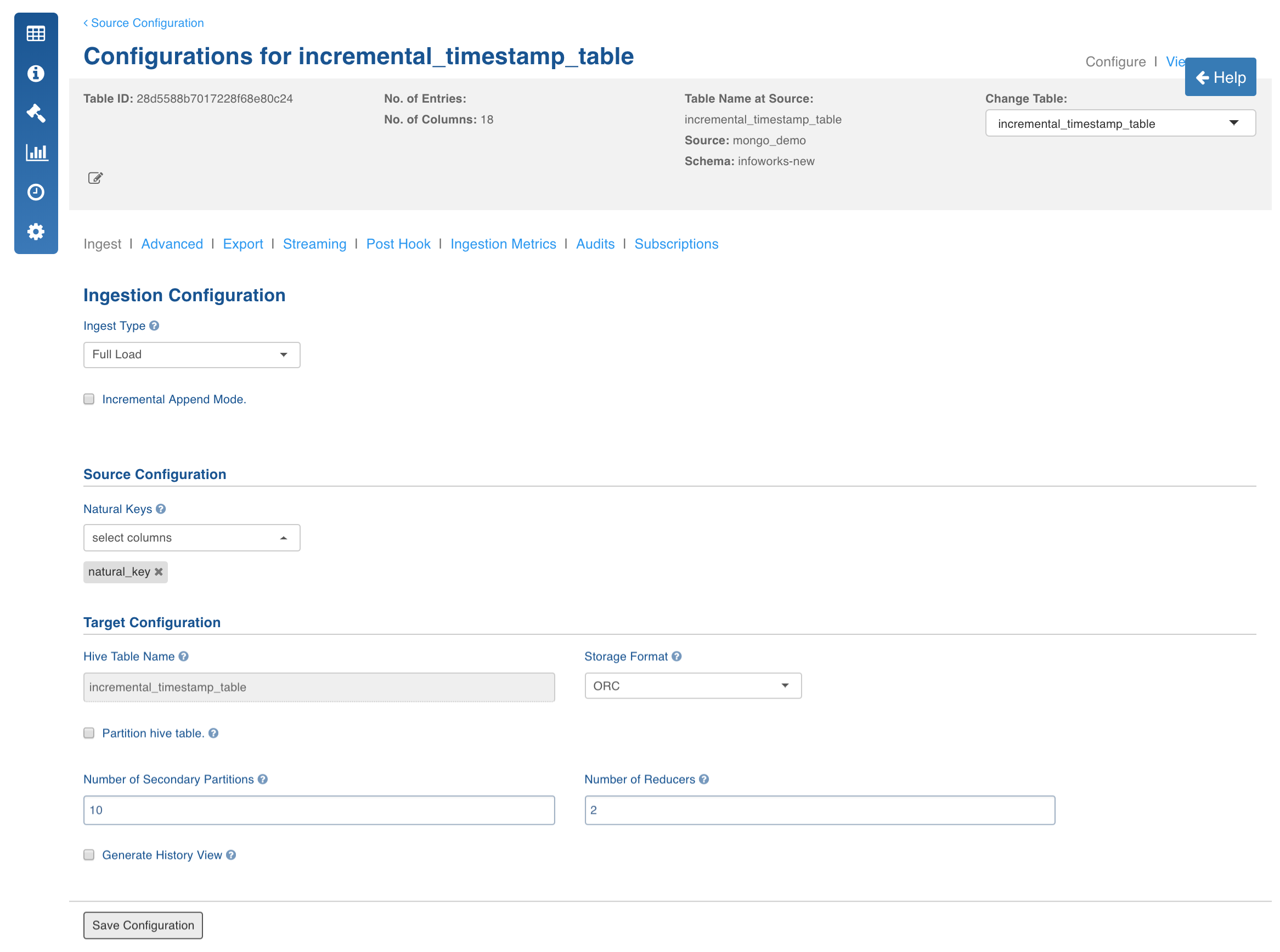
Click the Configure button for the table that requires a full load data crawl.
Select the Ingest Type as Full Load, enter the required values and click Save Configuration. For descriptions of fields, see Source Table Configuration Field Descriptions.
In the Table page, click the Table Group tab.
Click Add Table Group and enter the table group details.
Click Add Tables to add tables to the table group. Click Save Configurations.
Click the View Table Group icon for the required table group.
For first time ingestion, and for a clean crawl, click Initialize and Ingest Now.
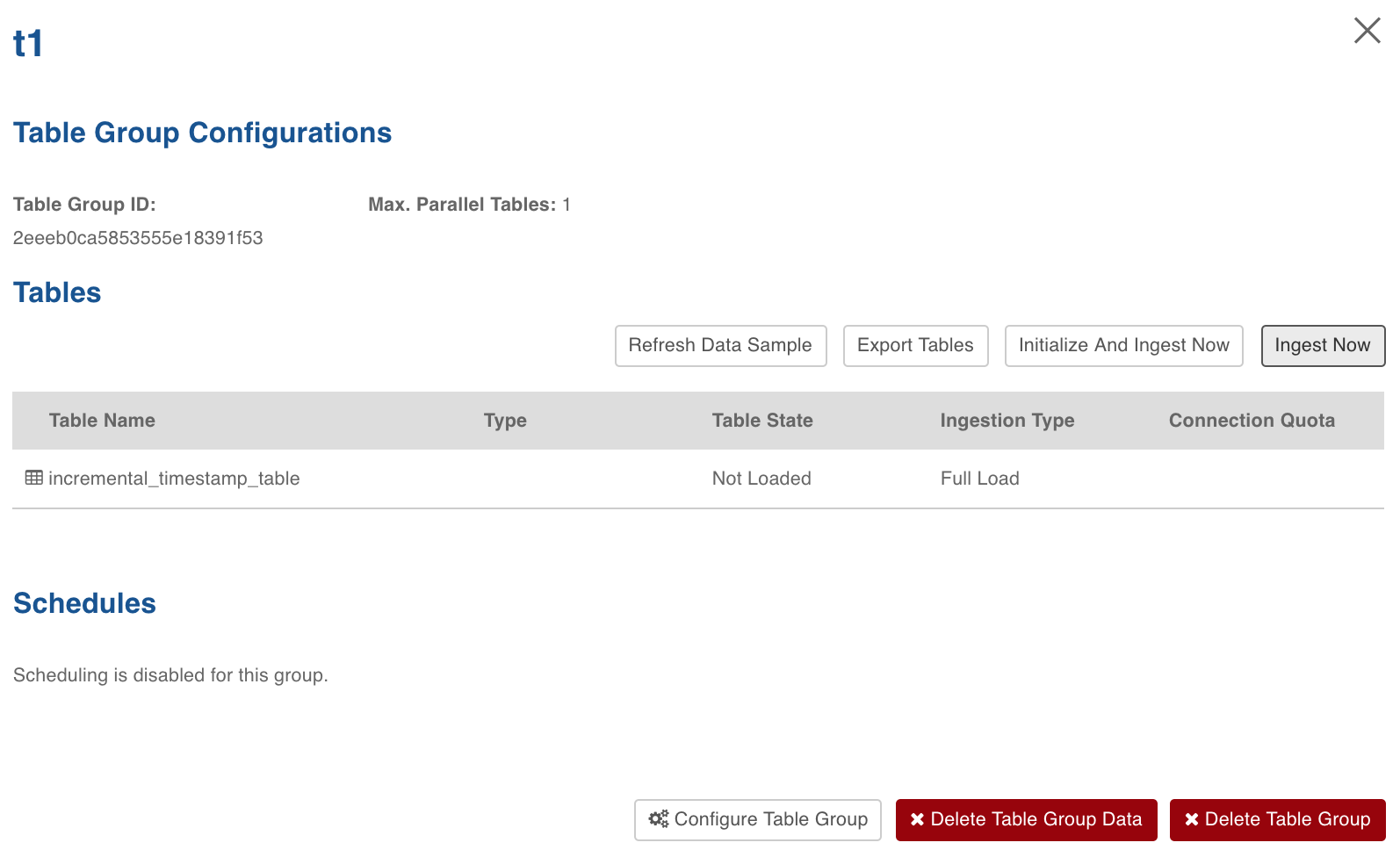
To append new data to the crawled source click Ingest Now from the second crawl onwards. The new data can be placed in the same location. Only new and changed files will be picked. This mode should be used for cases where new inserts come in new files and there are no updates.
Data Crawl Incremental Load
Following are the steps to perform an incremental load data crawl:
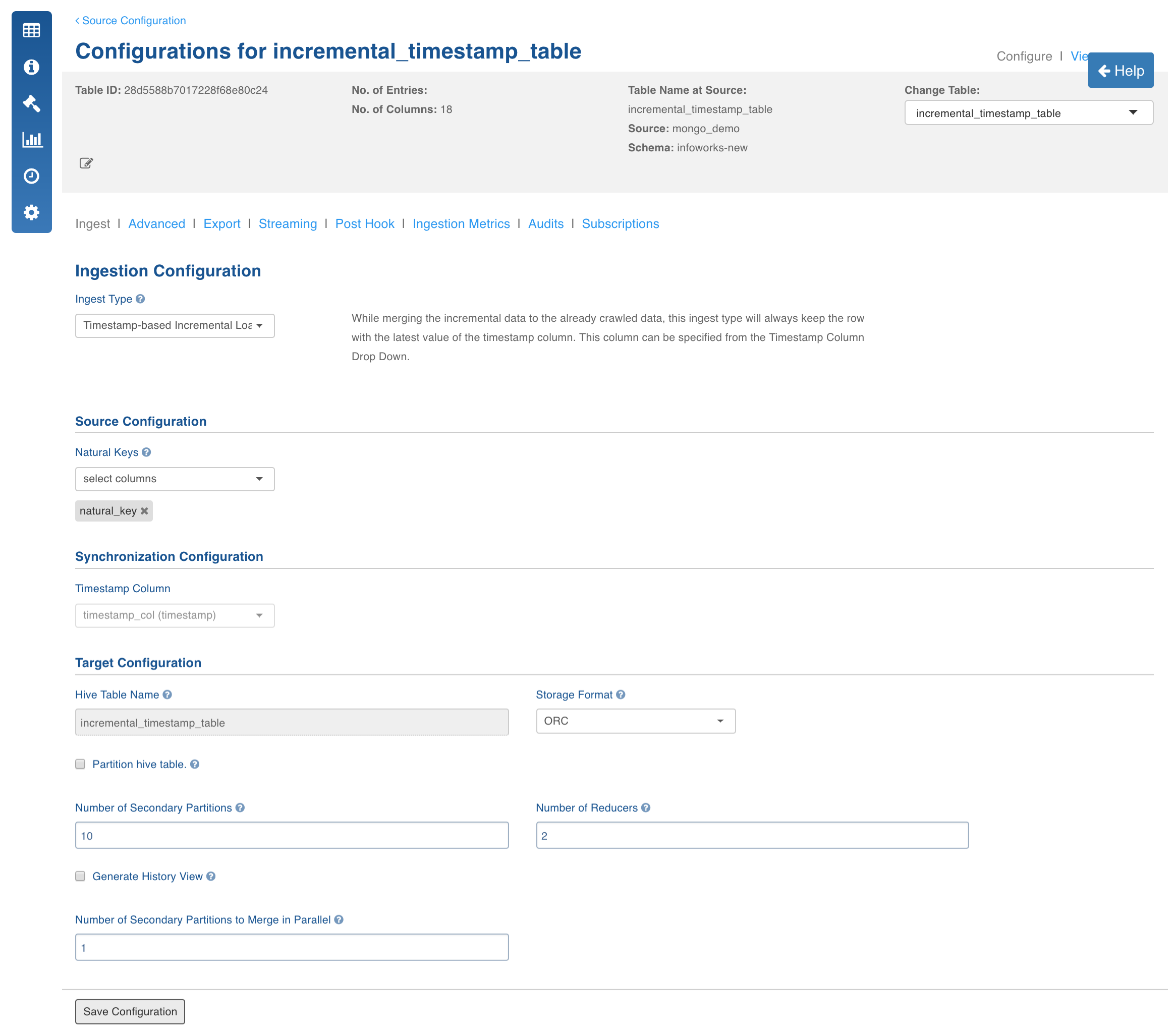
Click the Configure button for the table that requires an incremental load data crawl.
The Ingest Type for the incremental ingestion will be displayed based on the watermark column selected for the collection from which the table has been created. For example, if user selects Timestamp column as watermark column, only the Full Load and Timestamp-based Incremental Load options will be enabled.
Select the required incremental load Ingest Type, enter the other required values corresponding to the ingest type and click Save Configuration. For descriptions of fields, see Source Table Configuration Field Descriptions.
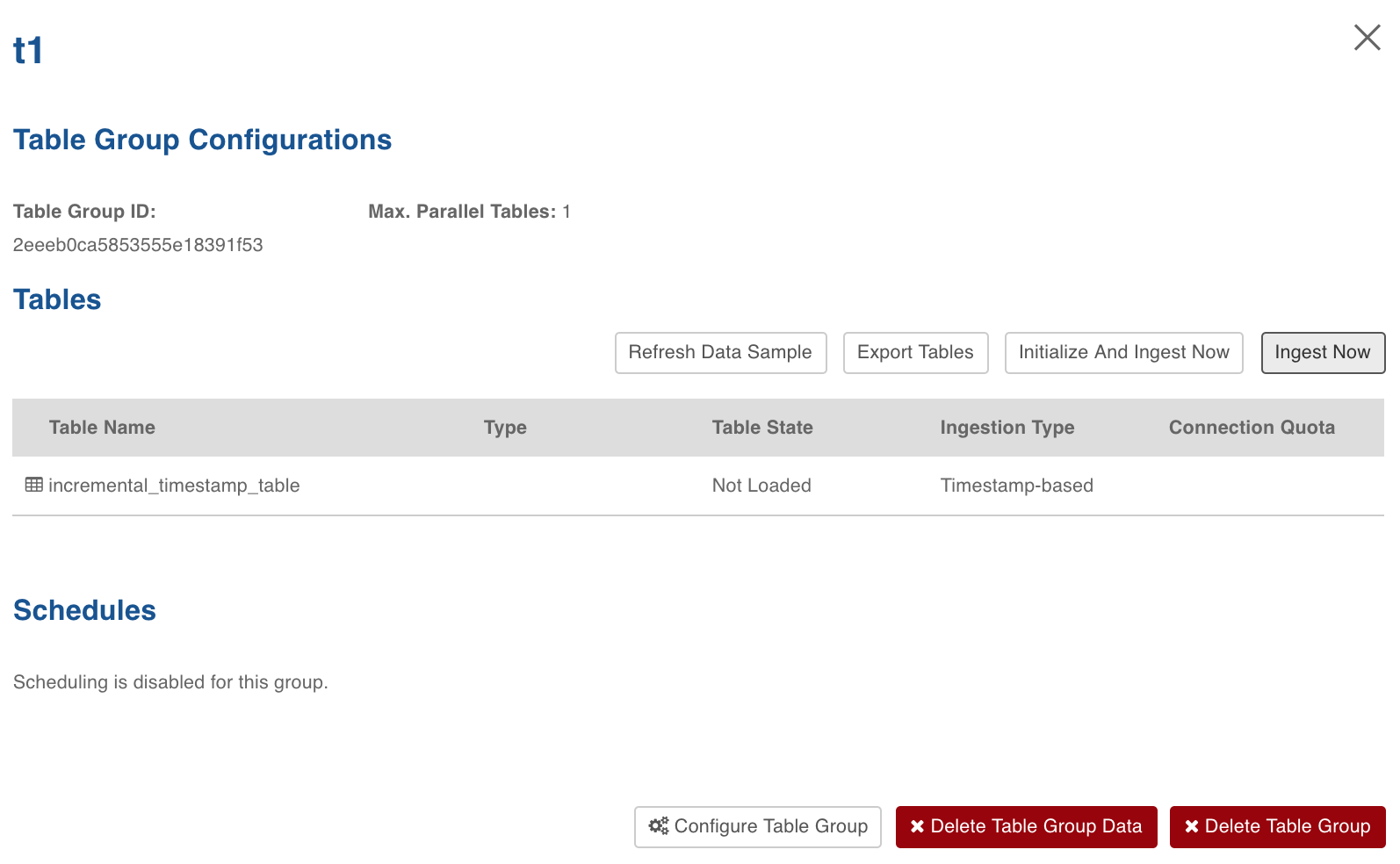
In the Table page, click the Table Group tab.
Click the View Table Group icon for the required table group.
For first time ingestion, and for a clean crawl, click Initialize and Ingest Now. This will crawl data from the collection completely till that point of time.
To get the new CDC data and merge it to the crawled data, click Ingest Now from the second crawl onwards. This will get the newly added and modified documents. This mode should be used for cases where new inserts and new updates are present for every crawl.
Append Mode
This mode must be used only when new inserts are present for every incremental crawl.
Select the watermark column for the collection (mandatory). For details, see Watermark Column Selection.
Select the Ingest Type as Full Load.
Select the Incremental Append Mode check box.
Enter the required fields and click Save Settings.