Fixed-width ingestion is supported with structured files. Data in a fixed-width text file is arranged in rows and columns, with one entry per row. Each column has a fixed width, specified in terms of number of characters, which determines the maximum amount of data it can contain. No delimiters are used to separate the fields in the file. Instead, smaller quantities of data are padded with spaces to fill the allotted space.
Fixed width ingestion provides the following features:
- Schema Input
- Data Crawl
- Append Mode
- CDC and Merge
Creating Fixed-width Source
For creating a Fixed-width source, see Creating Source. Ensure that the Source Type selected is Structured Files (CSV, Fixed-width, Mainframe Data Files).
Configuring Fixed-width Source
For configuring a Fixed-width source, see Configuring Source.
Creating Table
- Scroll down the Source Settings page and in the File Mapping section, click Add Entry to add a folder as a table.
- Configure the table details.
Fixed-width Configurations
| Field | Description |
|---|---|
| Table | The name by which the table will be represented in Infoworks User Interface. |
| Source Path | Folder path of the table. This is relative to the source base path. |
| Target HDFS Path | Target HDFS path. This is relative to the target base path. |
| Include/Exclude Files From Directory | A regex pattern to include or skip files. |
| Ingest sub-directories | Specifies whether to crawl the files in the recursive structure of the specified source path. |
| Archive Source Files | This option is used to archive files for which the data has been crawled and inserted into Hive. The files will be archived on the edge node. NOTE: Truncate and Truncate reload of the table will not affect archived files. For every data file the control file will also be archived. |
| Processing Level | For fixed width ingestion, select Record. |
| File Type | For fixed width ingestion, select Fixed-width. |
| Number of Header Rows | Can be 0 or greater than 0. If greater than 0, (for example, n), the first line of the file will be used to get the column names. The next n-1 lines will be skipped. |
| Pad Character | Padding character which is used in the fixed width file. |
| Character Encoding | Character encoding. |
| Control Files | This feature lets the user to specify a control file (a file with data file metadata) against which user can validate the data file. The regular expression fields Data Files pattern and Extract format let the user specify the corresponding control file for every data file as a function of the data file path. In the above example, every file with csv extension will be considered as a data file and the same file path ending with ctl extension will be treated as control file. Make sure that the data directory after applying include and exclude filters only returns data files and control files. While processing, the system first applies include and exclude filters for every file. Assuming that the file path which passes the Data Files pattern regex is a data file, the corresponding control file will be found using the mentioned regex patterns. Also make sure that control files should not pass Data Files pattern regex. Currently, the supported format for control files is java properties file format, which validates checksum , count, and filesize. The validation logic and control file reading logic is pluggable. Hence multiple validation variables and different control file parsing logics can be plugged to extend this feature. |
| Pad Character | Character used to add padding for smaller data columns. |
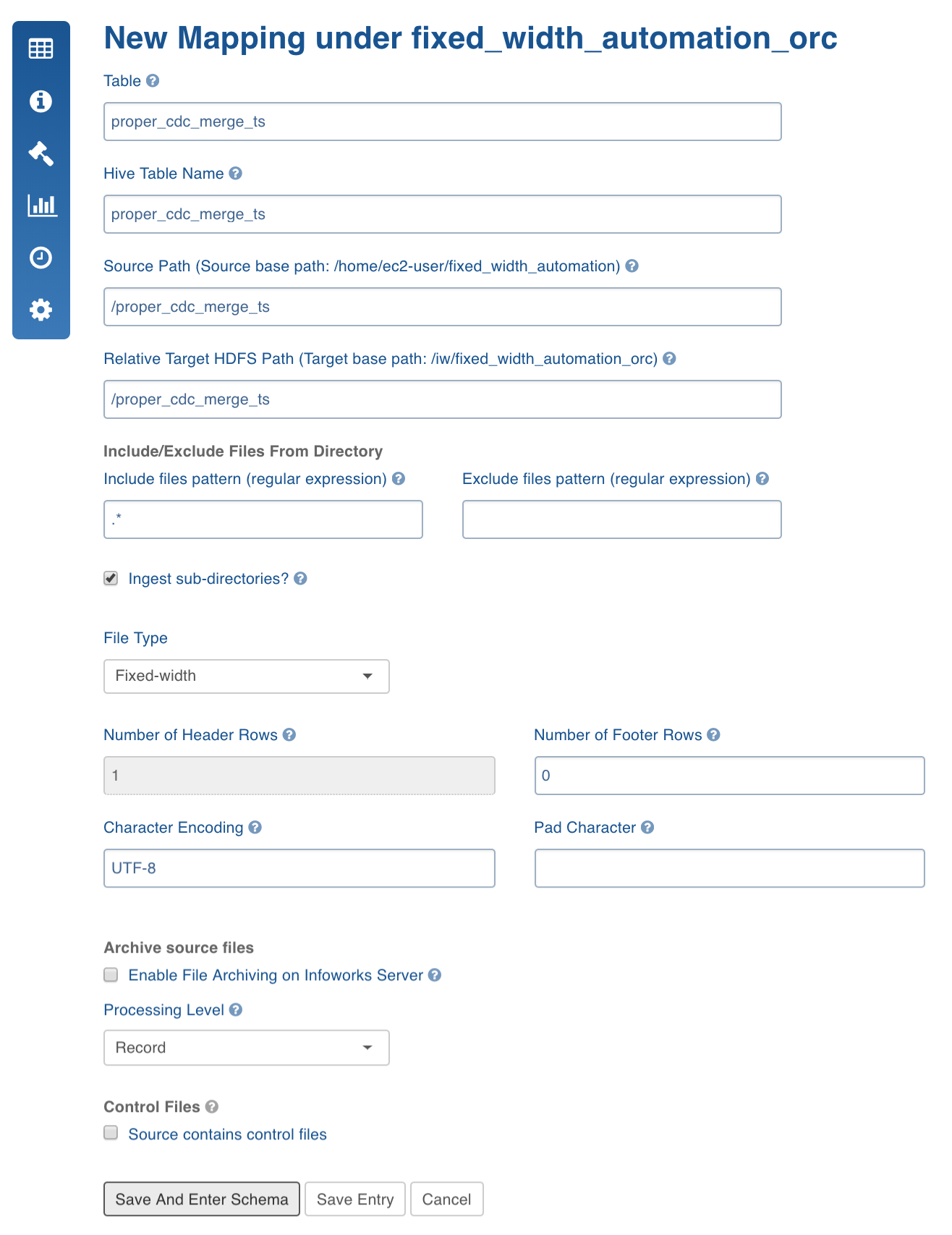
- Click Save and Enter Schema.
Crawling Fixed-width Metadata
For a given folder which contains files with similar structure, the system can detect the types of all columns.
- Navigate to table configuration page and click Edit Schema.
NOTE: Ensure that the columns you specify are in the order that would be in the files.
- Enter the number of columns in the Add field.
- Enter the details for each column added which includes column name, Start Position (any non-negative integer) and width.
Limitation: The Start Position of new columns must be greater than the Start Position of the previous column.
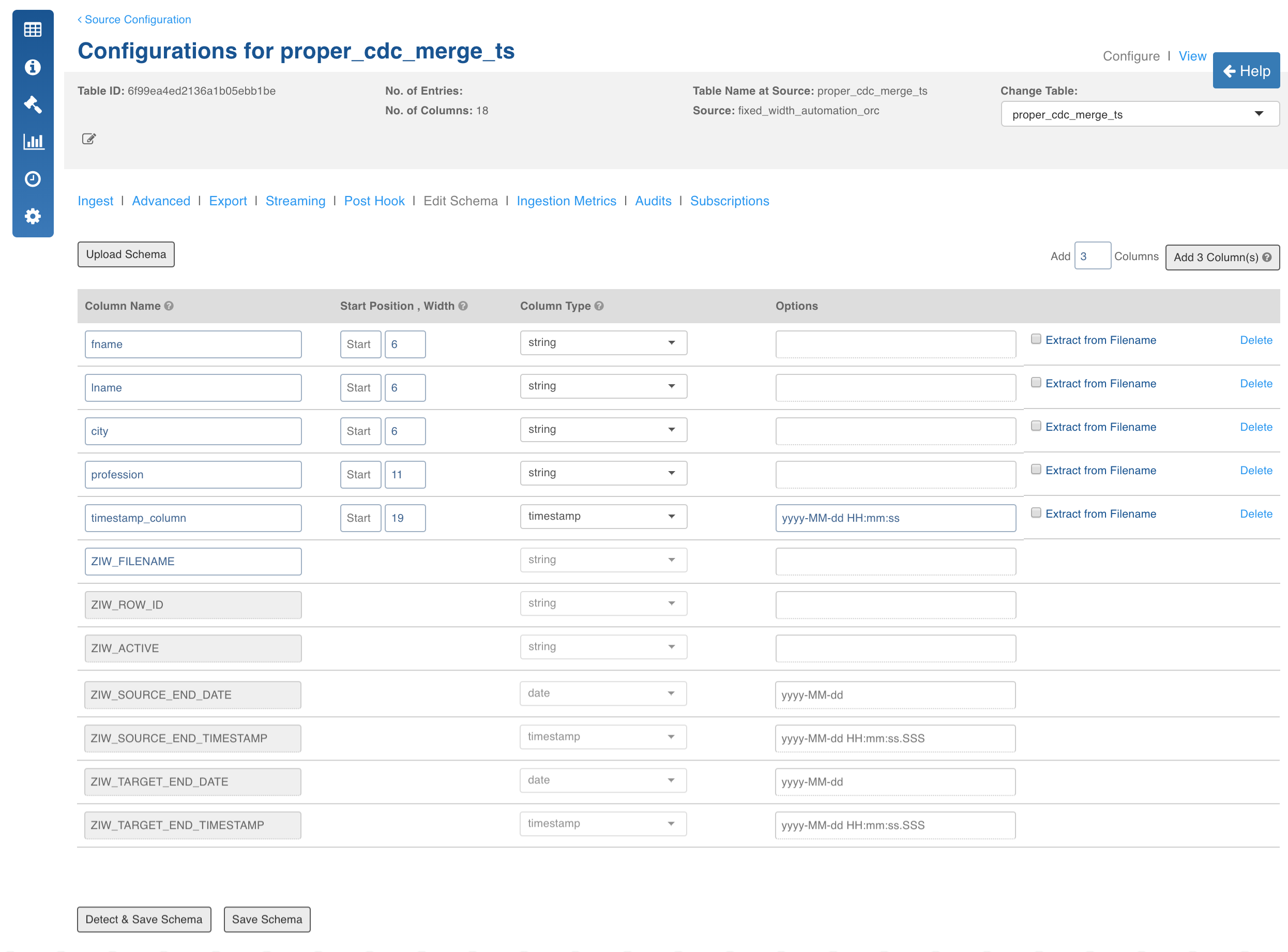
- Click Detect and Save Schema, the recommended datatypes are displayed. You can reconfigure datatypes if required.
- Click Save Schema.
Crawling Fixed-width Data
For crawling a Fixed-width source, see Crawling Data.
Advanced Configurations
- FIXED_WIDTH_ERROR_THRESHHOLD: If the number of error records increases this threshold, the MR job fails. Default is 100.
- FIXED_WIDTH_KEEP_FILES: If the host type is local before the MR job runs, the csv files are copied to the tableId/csv directory. If this config is true, then the files are not deleted after the crawl. Default is true.
- FIXED_WIDTH_SPLIT_SIZE_MB: Split size to be used for MR for every file. Default is 128.
- fixed_width_job_map_mem: Mapper memory for the crawl map reduce. Default is the value of iw_jobs_default_mr_map_mem_mb in properties.
- fixed_width_job_red_mem: Reducer memory for the crawl map reduce. Default is the value of iw_jobs_default_mr_red_mem_mb in properties.
- calc_file_level_ing_metrics: If this is set to true, the file-level ingestion metrics are calculated at the end of the job. Default is true. This holds good for both CSV and Fixed Width.
- modified_time_as_cksum: If this is true, the modified time is used to determine the file has been changed or not. If it is set to false, the actual checksum is calculated. Default is false. This holds good for both CSV and Fixed Width.
- delete_table_query_enabled: By default, Delete Query feature is available at table level . To hide this feature, set IW Constant delete_table_query_enabled to false.
Extract, Transform, and Load Features
This section describes the Extract, Transform, and Load (ETL) features that include:
- File-level ingestion metrics
- Column extraction
- Delete functionality
- Archive Directory
- Control Files
File-Level Ingestion Metrics
This feature provides information on how many correct and error records were contributed by a file. A compulsory string column will be appended to every row in the data. The column will be named ZIW_FILENAME. The name can be changed. This column will be used to run "group by" queries on the crawled data for file-level ingestion metrics.
Column Extraction
This feature includes appending columns to the row which are extracted from a "match regex" and "extract regex" applied from the filename.
Follow these steps to make use of this feature:
- Click Edit Schema tab in the Configuration page.
- Add columns and check Extract from Filename.
You can match and extract the regex. For example, for the file name Infoworks_001_2004-09-28, the column names will extract following values:
- Extracted_Date: 2004-09-28
- Extracted_Int: 1
- Extracted_Str: Infoworks
- Extracted_without_format: 2004-09-28 (If format is not specified, the items matching the regex becomes the value.)
- Click Save Schema.
Delete Functionality
The delete functionality enables you to delete all the rows from the current Hive table.
Follow these steps to make use of this functionality:
- Navigate to the Source Configuration.
- Click the Actions button for the table from which you want to delete the rows.
- Click Delete Records. The record will be deleted from the current table data.
Archive Directory
Refer to Fixed-width Configurations for more details.
Control Files
Refer to Fixed-width Configurations for more details.