Using TD Wallet for Teradata TPT Source
Prerequisite
- Ensure that TD Wallet has been set up for the Infoworks user.
Configuring TPT Source
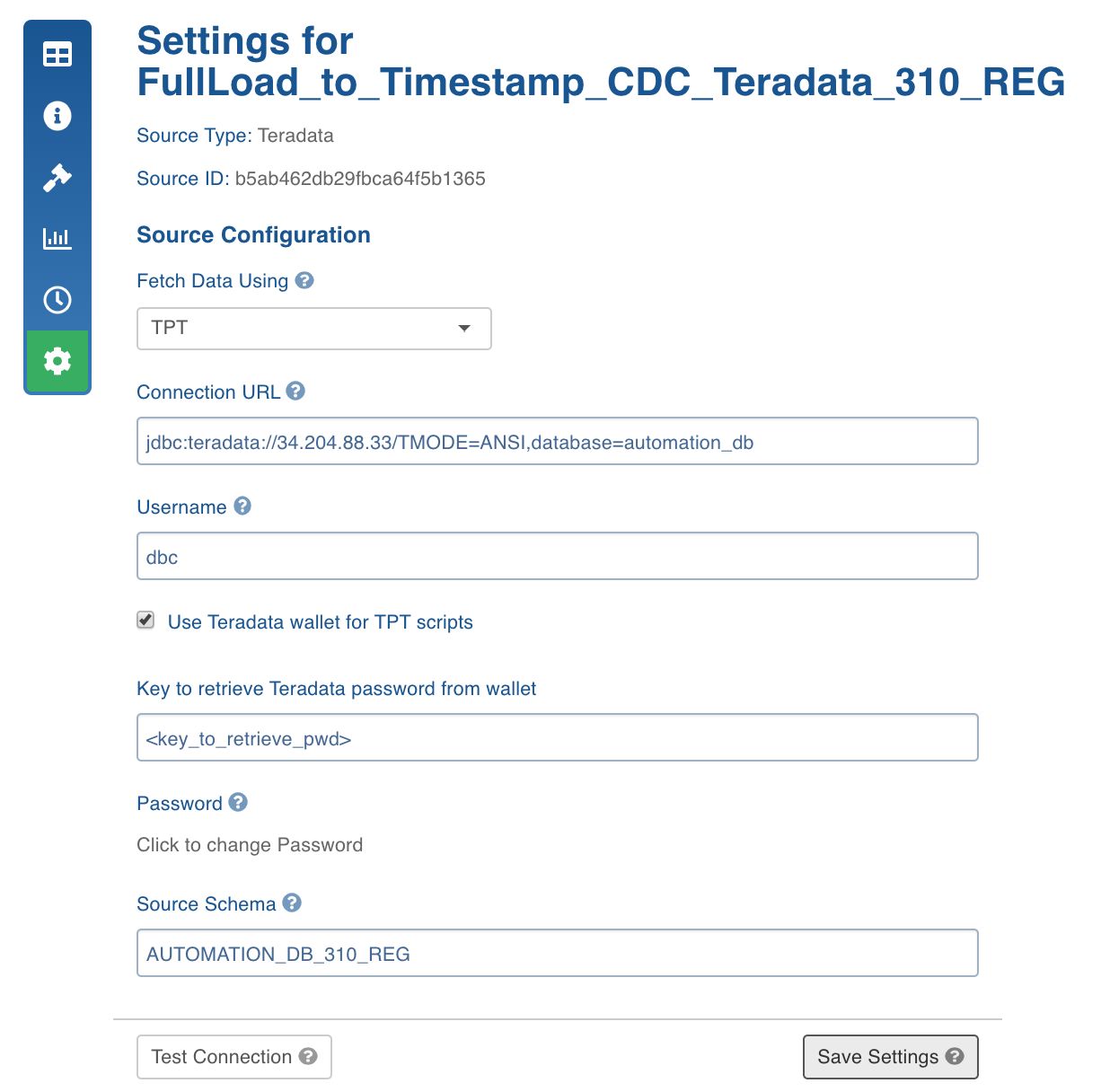
- In the Source Settings page for the teradata source, select the Fetch Data Using as TPT.
- Select the Use Teradata wallet for TPT scripts option.
- Enter the Key to retrieve Teradata password from wallet.
For example, if the TD Wallet is set up and a key, TD_PASSWORD, is added with the database password as the value, when configuring the source for TPT, you can provide TD_PASSWORD as the key to retrieve the password from the Teradata wallet.
Teradata TPT Data Extraction
Following are the steps for data extraction from source for TPT:
- Fetching data from Teradata Using TPT - the data from Teradata will be stored onto Hadoop in CSV format.
- Processing the CSV file - the CSV file data will be processed (and converted) to store in the user-selected format (ORC/Parquet).
Following are the maintenance options:
- Run Delta Stage Job - the incremental delta data from Teradata will be fetched and stored onto Hadoop in CSV format.
- Run Delta Process Job - the delta CSV file data will be processed (and converted) to store in the user-selected format (ORC/Parquet).
- Run Delta Merge - the available incremental delta files will be merged to the existing data on Hadoop.
- Run Full Load - the table will be truncated and reloaded. It works like Initialize and Ingest Now.
- Run Post-Ingestion Hook - the UI hook at the table group level to run the Post-Ingestion Hook scripts externally. Usually, the scripts will be executed as part of the ingestion job (full/incremental).
- Run Full Load Stage Job - the data from Teradata will be stored onto Hadoop in CSV format.
- Run Full Load Process Job - the CSV file data will be processed (and converted) to store in user-selected format (ORC/Parquet).