The following nodes are supported along with other transformations in Data Transformation:
The advanced analytics nodes are used for predictive modelling. Predictive modelling is the process by which a model is created to predict an outcome. If the outcome is categorical, it is called classification and if the outcome is numerical, it is called regression. Descriptive modelling or clustering is the assignment of observations into clusters so that observations in the same cluster are similar.
NOTE: Predictions are generated only for test data sets.
Logistic Regression
Logistic Regression is a classification. It predicts the probability of an outcome that can only have binary values. The prediction is based on the use of one or several predictors. Logistic regression produces a logistic curve, which is limited to values 0 and 1.
Following are the steps to apply Logistic Regression node in pipeline:
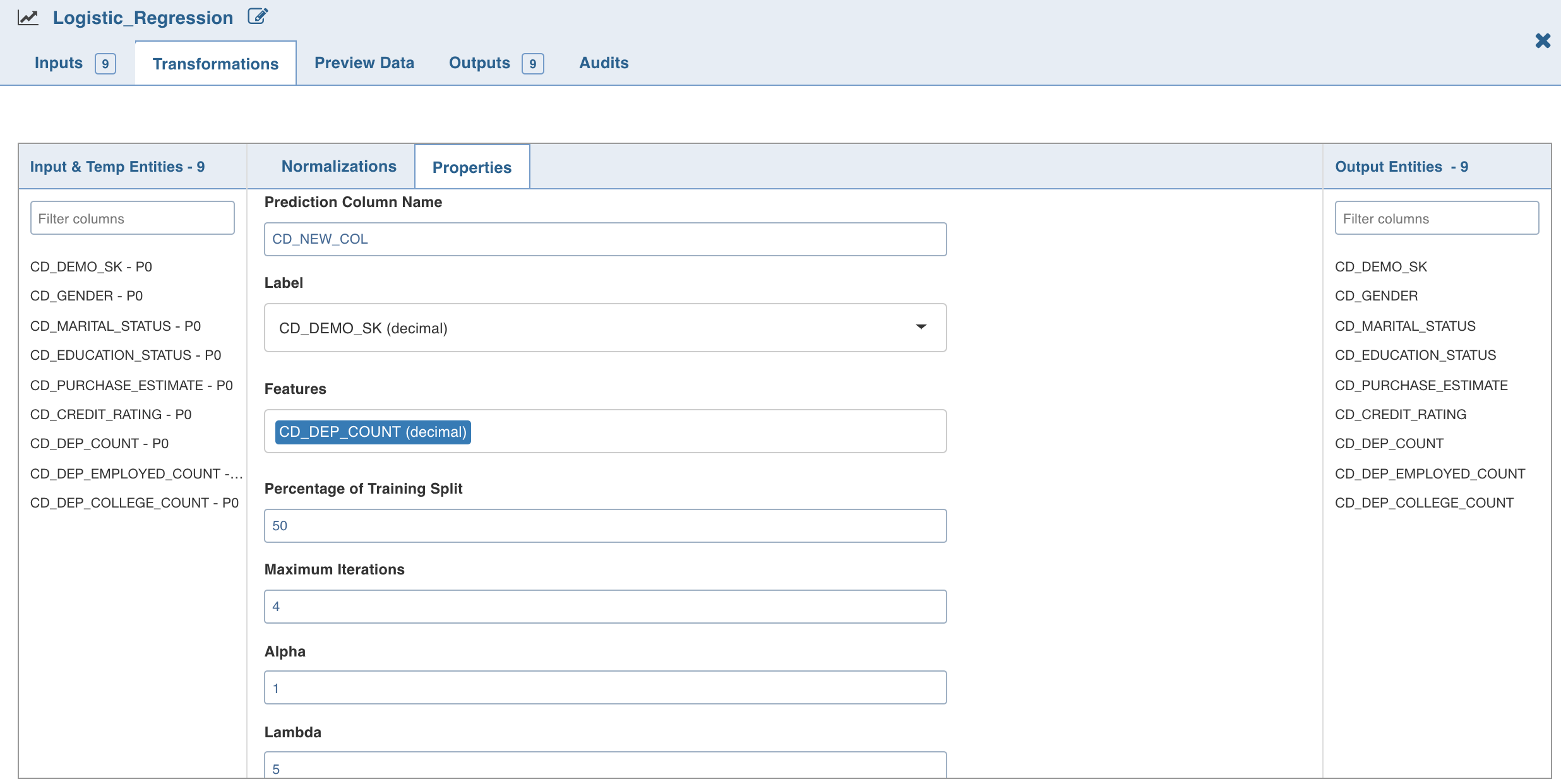
Double-click the Logistic Regression node. The properties page is displayed.
Click Edit Properties to edit the property values and click Save.
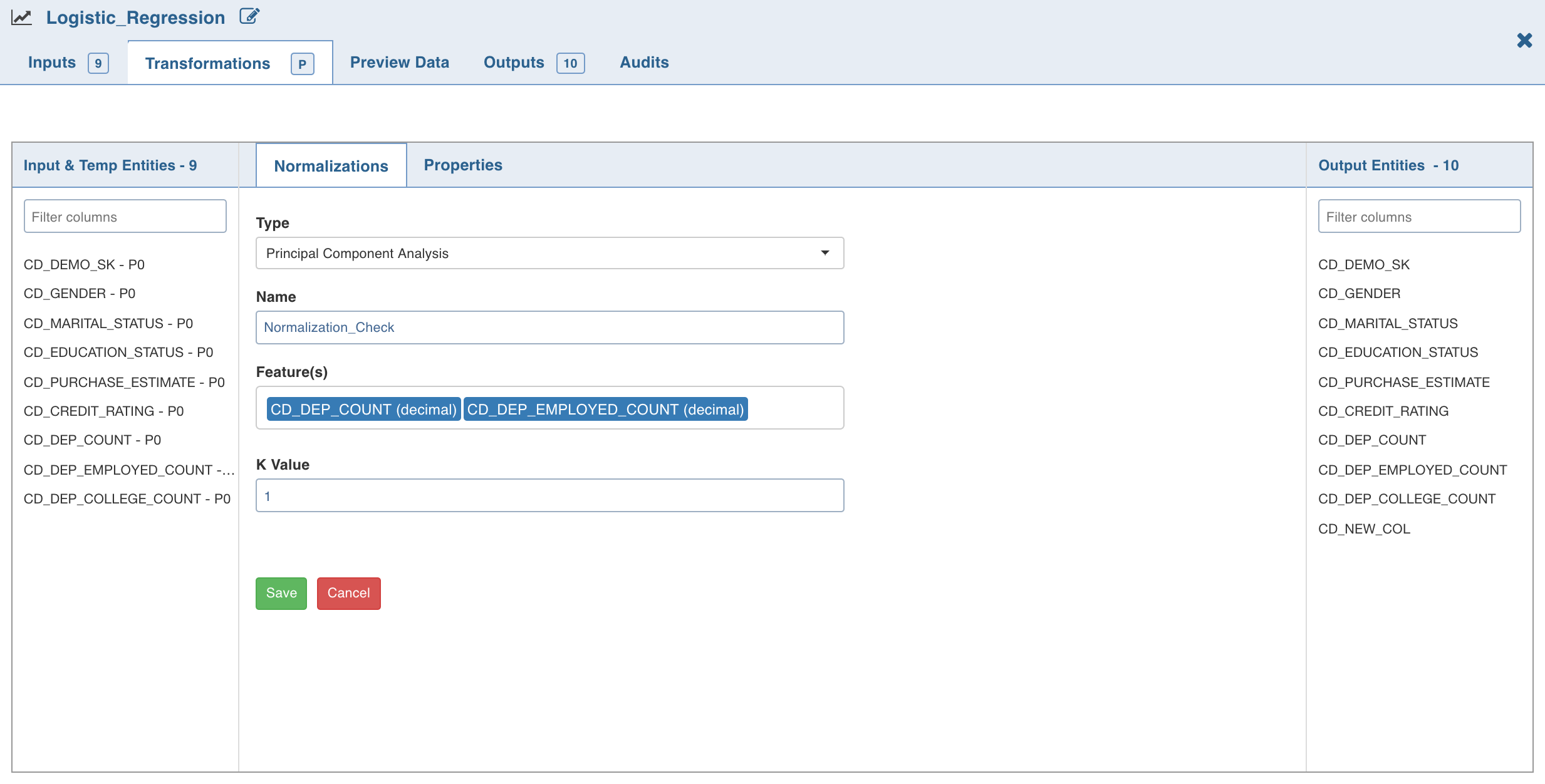
Click Normalization. A list of normalizations are displayed.
Click Add Normalization , enter the required details and click Save.
Decision Tree
Decision tree builds regression or classification models in the form of a tree structure. It breaks down a dataset into smaller and smaller subsets while at the same time an associated decision tree is incrementally developed. The result is a tree with decision nodes and leaf nodes. The topmost decision node in a tree which corresponds to the best predictor is called root node.
Following are the steps to apply Decision Tree node in pipeline:
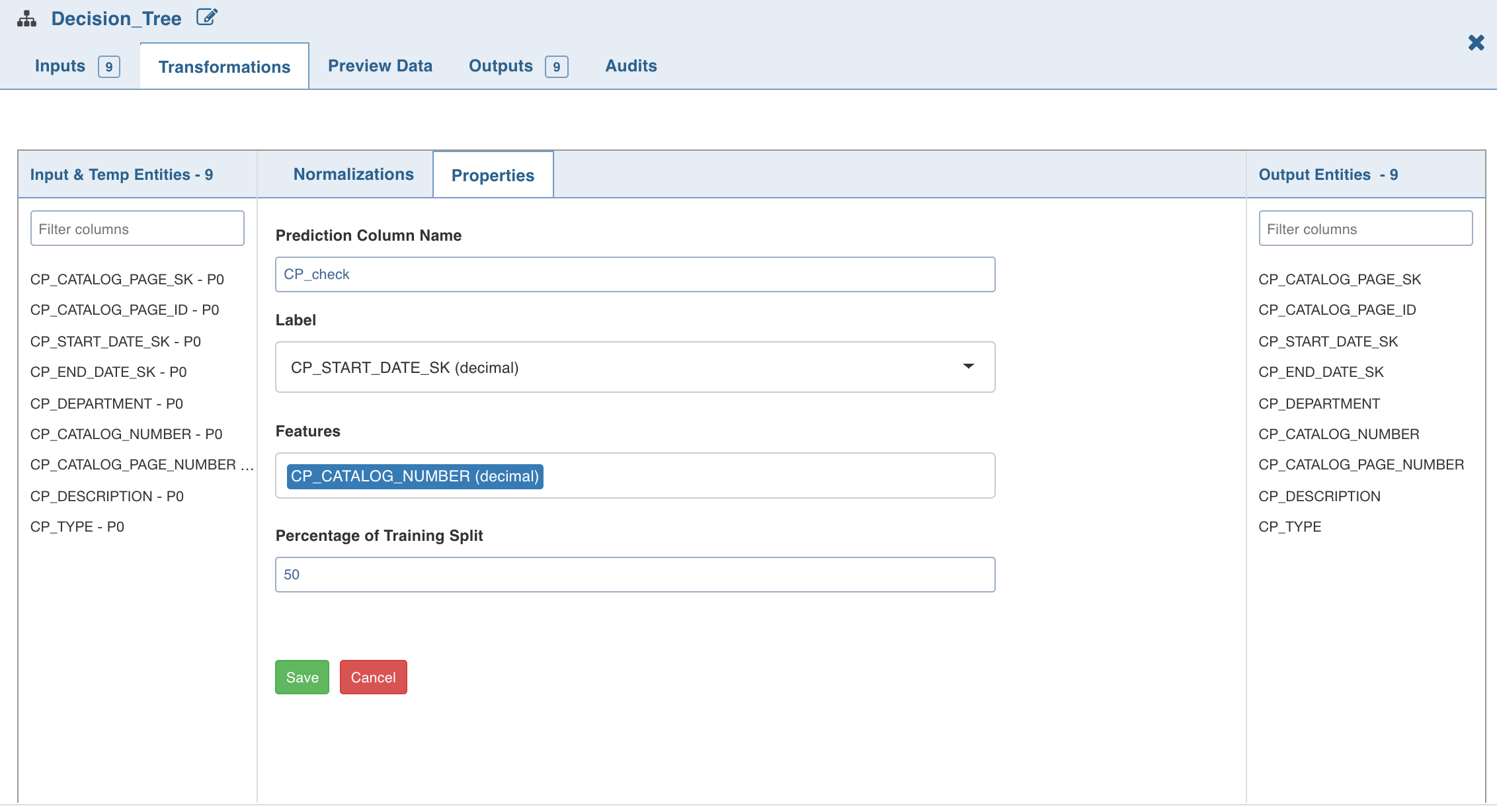
Double-click the Decision Tree node. The properties page is displayed.
Click Edit Properties to edit the properties and click Save.
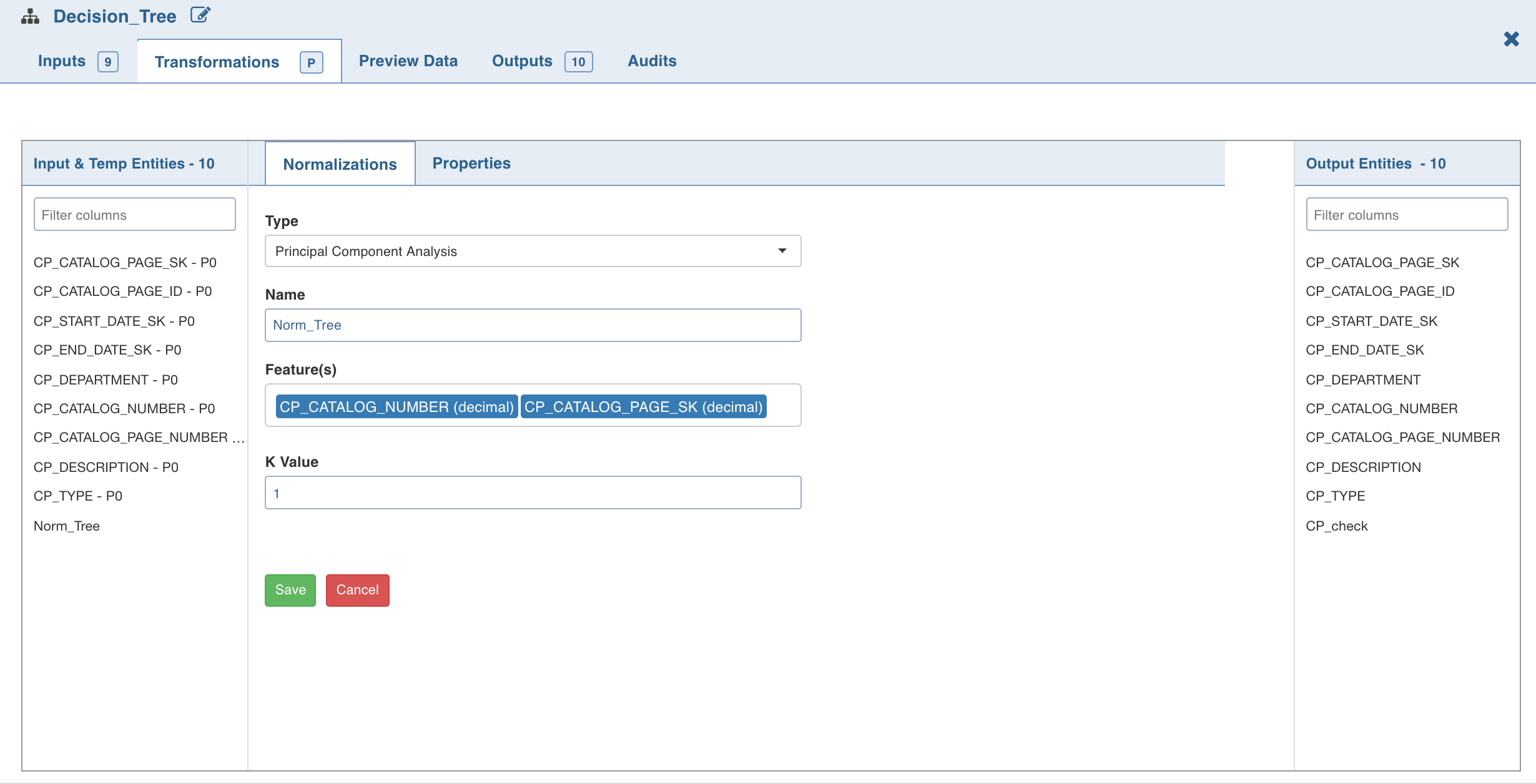
Click Normalizations. The list of normalizations are displayed.
Click Add Normalization, enter the required normalization properties and click Save .
K-Means Clustering
This unsupervised learning algorithm partitions observations into k clusters.
Following are the steps to apply K-Means Clustering node in pipeline:
Double-click the K-Means Clustering node. The properties page is displayed.
Click Edit Properties, enter the details and click Save.
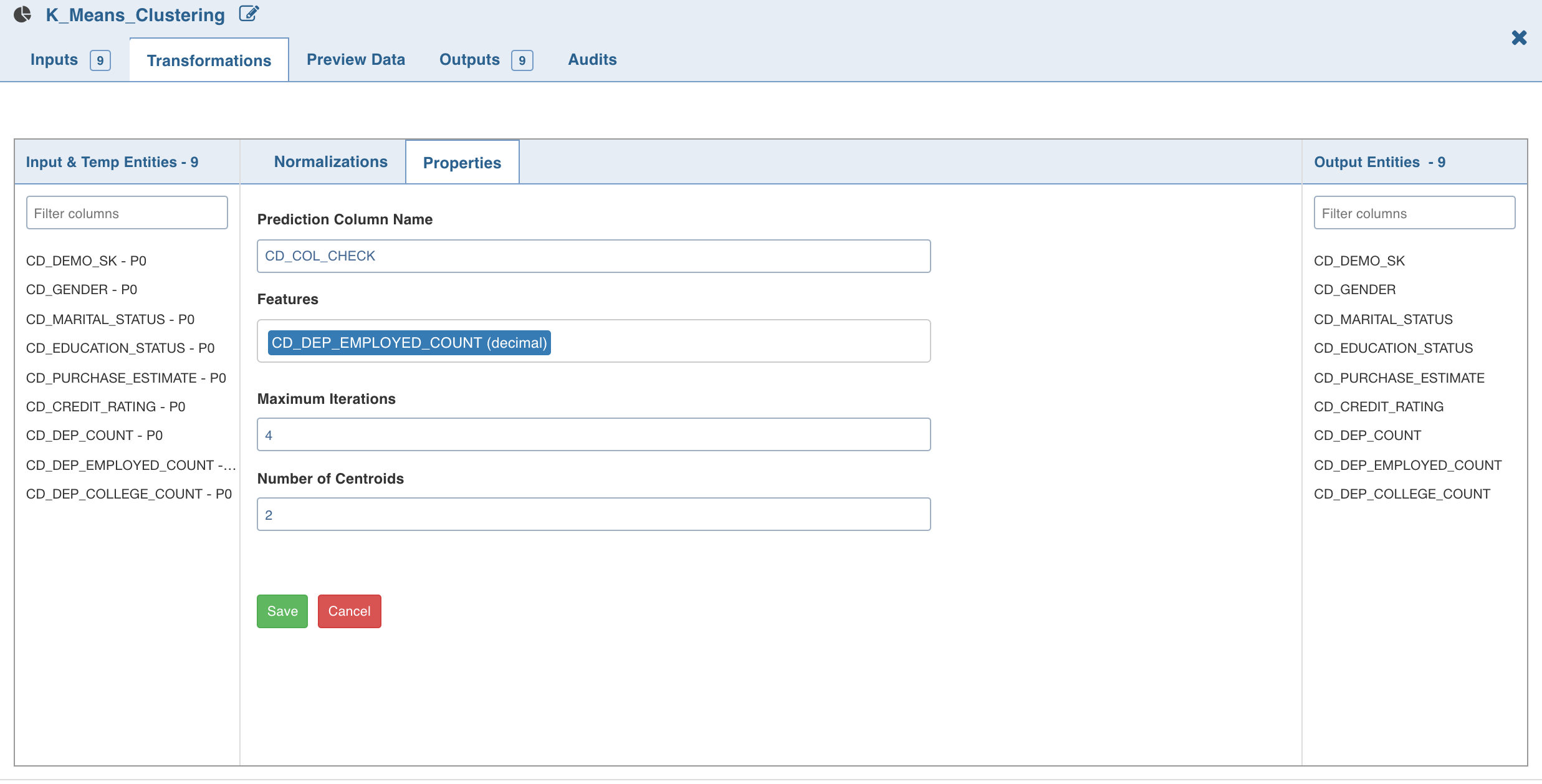
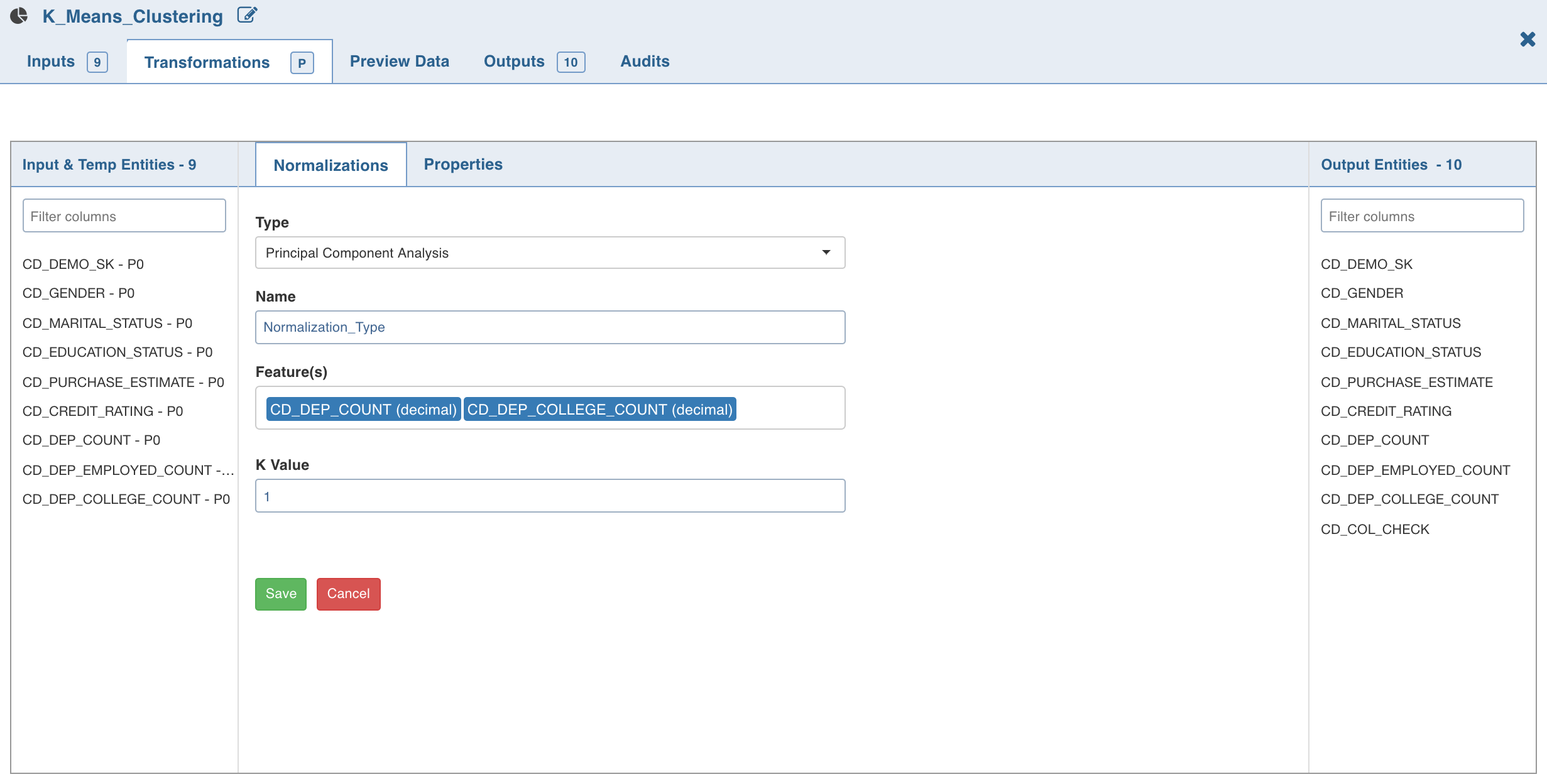
Click Normalization. The list of normalizations are displayed.
Click Add Normalization, enter the required normalization properties and click Save .
Random-Forest Classification
Like Decision Trees, the algorithm in Random Forest Classification creates a bunch of decision trees with random data and random features. Prediction will be the arithmetic average of the prediction of the individual decision trees.
Following are the steps to apply Random-Forest Classification node in pipeline:
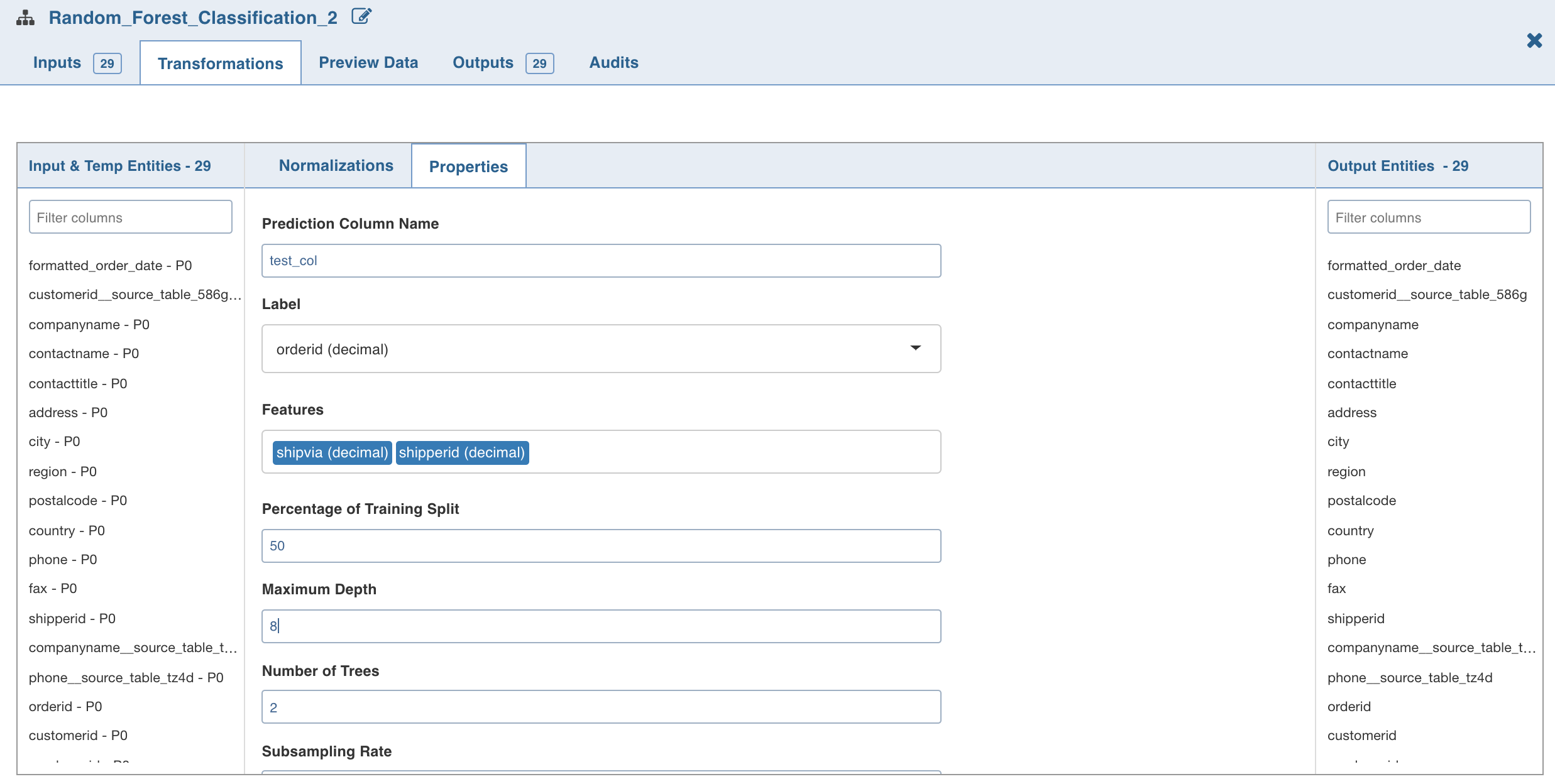
Double-click the Random Forest Classification node. The properties page is displayed.
Click Edit Properties, enter the details and click Save.
Following are the fields:
Maximum Depth is the maximum depth of trees, between 0 and 30.
Number of Trees is the number of trees (any integer value) used for the ensemble.
Subsampling Rate is the fraction of the training data used for learning each decision tree, in range (0, 1).
Click Normalization. The list of normalizations are displayed.
Click Add Normalization, enter the required normalization properties and click Save .
Analytics Model Export
Analytics Model Export node allows you to save Trained ML Spark Model. This model from the path can be used by any pyspark-based script to load model and apply on dataset matching schema to generate predictions/clusters.
This node does not export any data. Analytics Export Model takes Name and Base Path as input and stores Trained ML Spark Model and the PMML file corresponding to the trained model in the location with given name.
NOTE: Currently, PMML file does not get generated for Random Forest Node.
For example, if the name is reorder_prediction_logistic_regression and path is /spark/ml/models/, the model will be saved in /spark/ml/models/reorder_prediction_logistic_regression/.
Models are only exported in batch mode. In interactive mode, it will only validate column rename or exclude.
NOTE: This node can be attached only to the Advanced Analytics nodes. No Feature and Prediction columns in the Advanced Analytics node can be excluded inAdvanced Analytics node or export node.
Following are the steps to apply Analytics Model Export node in pipeline:
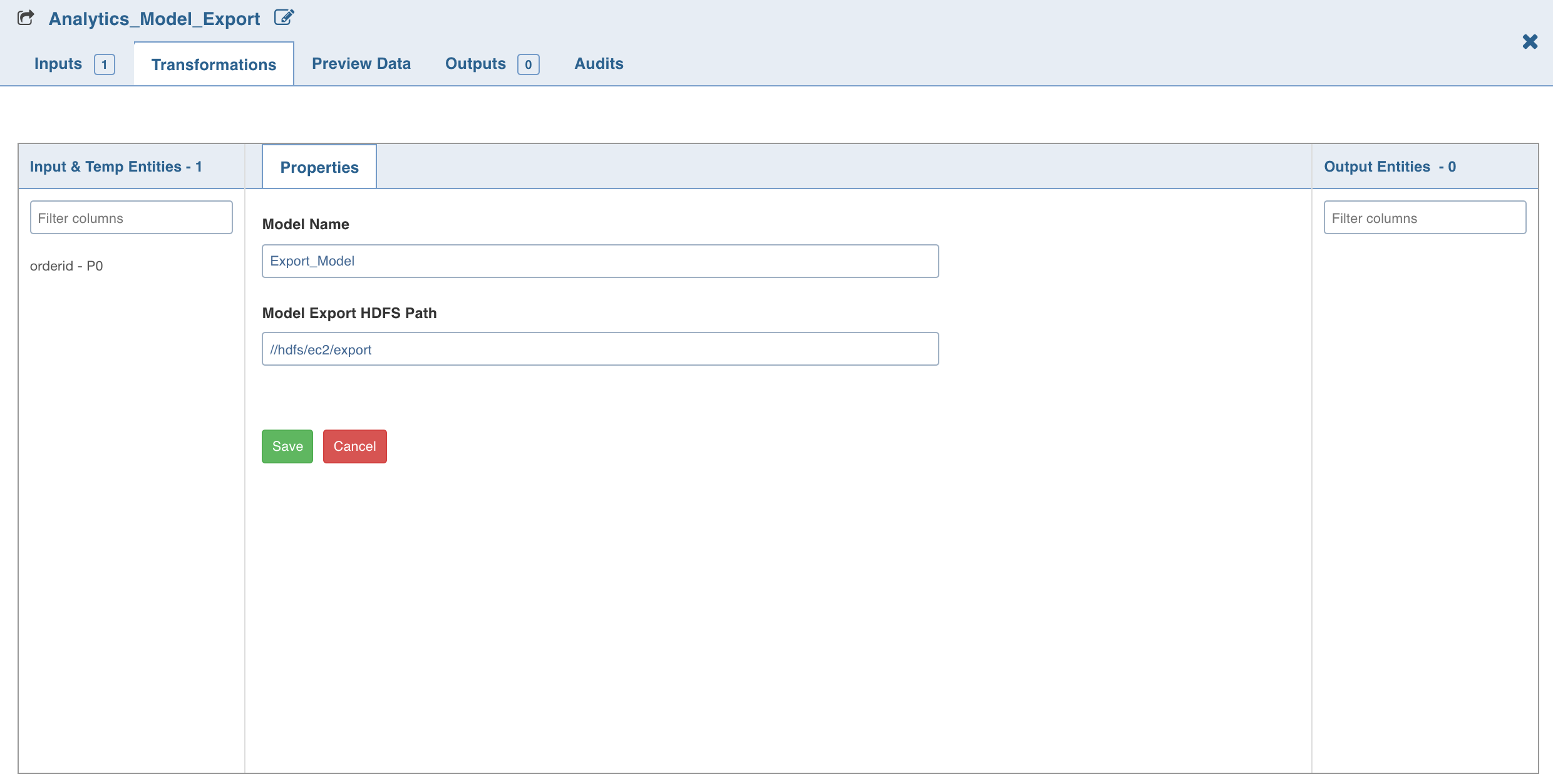
Connect the required advanced analytics node (Logistic regression, Decision tree, K Means clustering, Random forest classification) to the Analytics Model Import node and double-click the node. The properties page is displayed.
Click Edit Properties . Enter the Model Name and Model Export HDFS Path and click Save.
Analytics Model Import
The Analytics Model Import node allows you to import the saved/exported Trained ML Spark Model from HDFS to a pipeline. This model from the HDFS path can be used by any pyspark-based script to load the model and apply on dataset matching schema to generate predictions/clusters. This node does not import any data.
Analytics Model Import takes the Analytics Model name of various ML model types and their feature column mappings as input.
Following are the steps to apply Analytics Model Import node in pipeline:
Connect the required advanced analytics node (Logistic regression, Decision tree, K Means clustering, Random forest classification) to the Analytics Model Import node and double-click the node. The Properties window is displayed.
Click Edit Properties and select the analytics model from the Analytics Model to Import drop down.
Under Analytics_Model_Import (right), click the edit symbol and select the required columns whose values map with the selected analytics model (left).
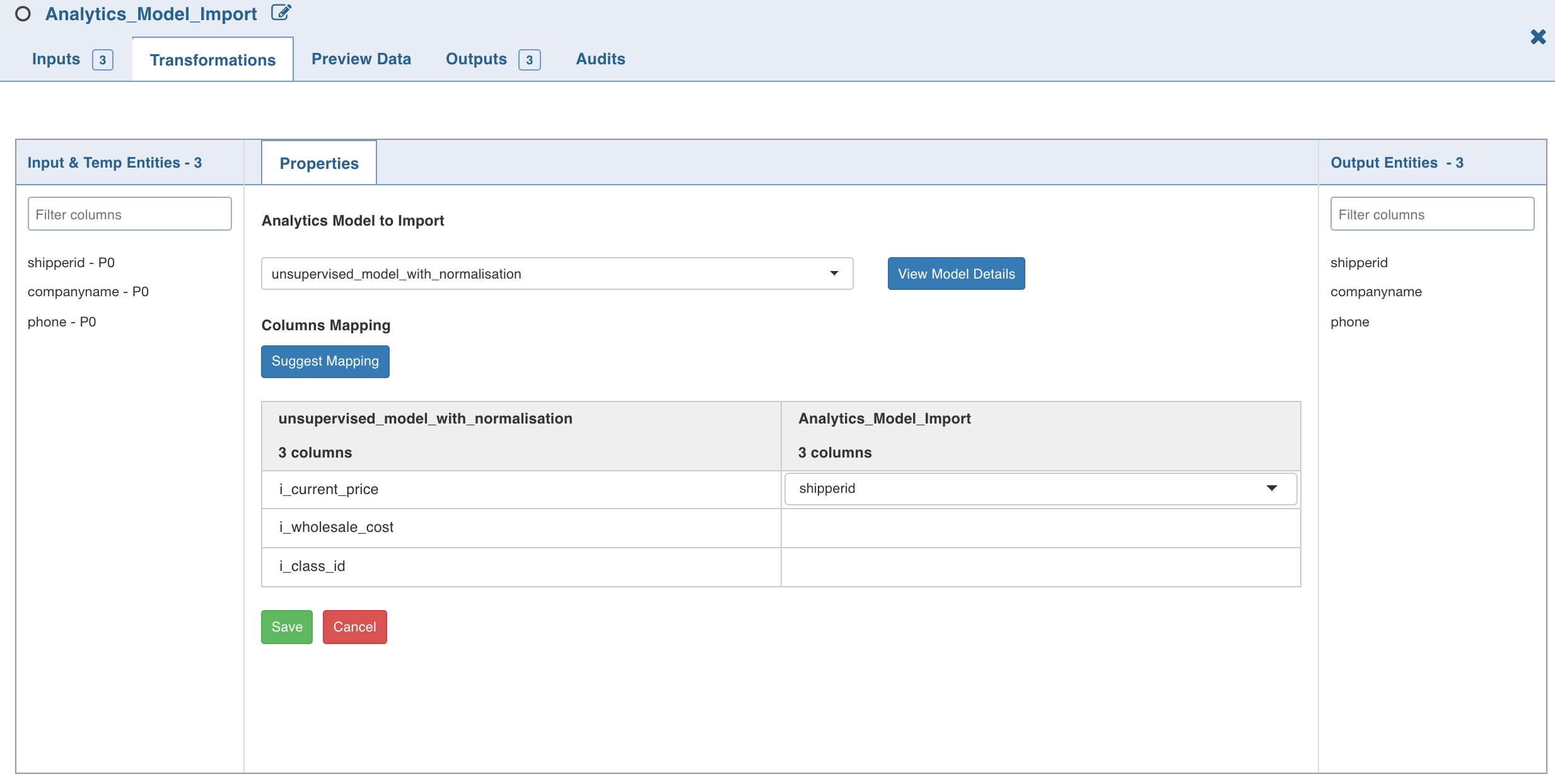
NOTE: If the values of columns under Analytics_Model_Import drop down do not map with those of the analytics model (as shown in the above illustration), the error message Data Type is not supported is displayed after you click OK.
Click Save.
Click Data to view the generated table data.
Error Messages and Limitations
Null Value Error: If any of the feature columns have null values, spark displays an error at vector assembler level. Workaround: Add a Filter node between the Analytics Model Input and the connecting node and add a not null condition on all feature columns with and condition.
H2O Support in Advanced Analytics Node
H2O is an open source, in-memory, distributed, fast, and scalable machine learning and predictive analytics platform that allows you to build machine learning models on big data.
Infoworks supports H2O as a machine learning engine for all the analytics nodes.
NOTES:
Normalization is not supported for H2O engine.
H2O engine is only supported in Spark local mode.