Following are the steps to design a workflow:
Click the new workflow created. The blank Preview page is displayed.
Click Open Workflow Editor.
Drag and drop the required tasks in the editor.
Other than running regular tasks like Ingestion, building of pipelines, you can execute Bash commands and Hive queries, send notifications and also use a Decision Branch to add flow control.
Following is a sample workflow:
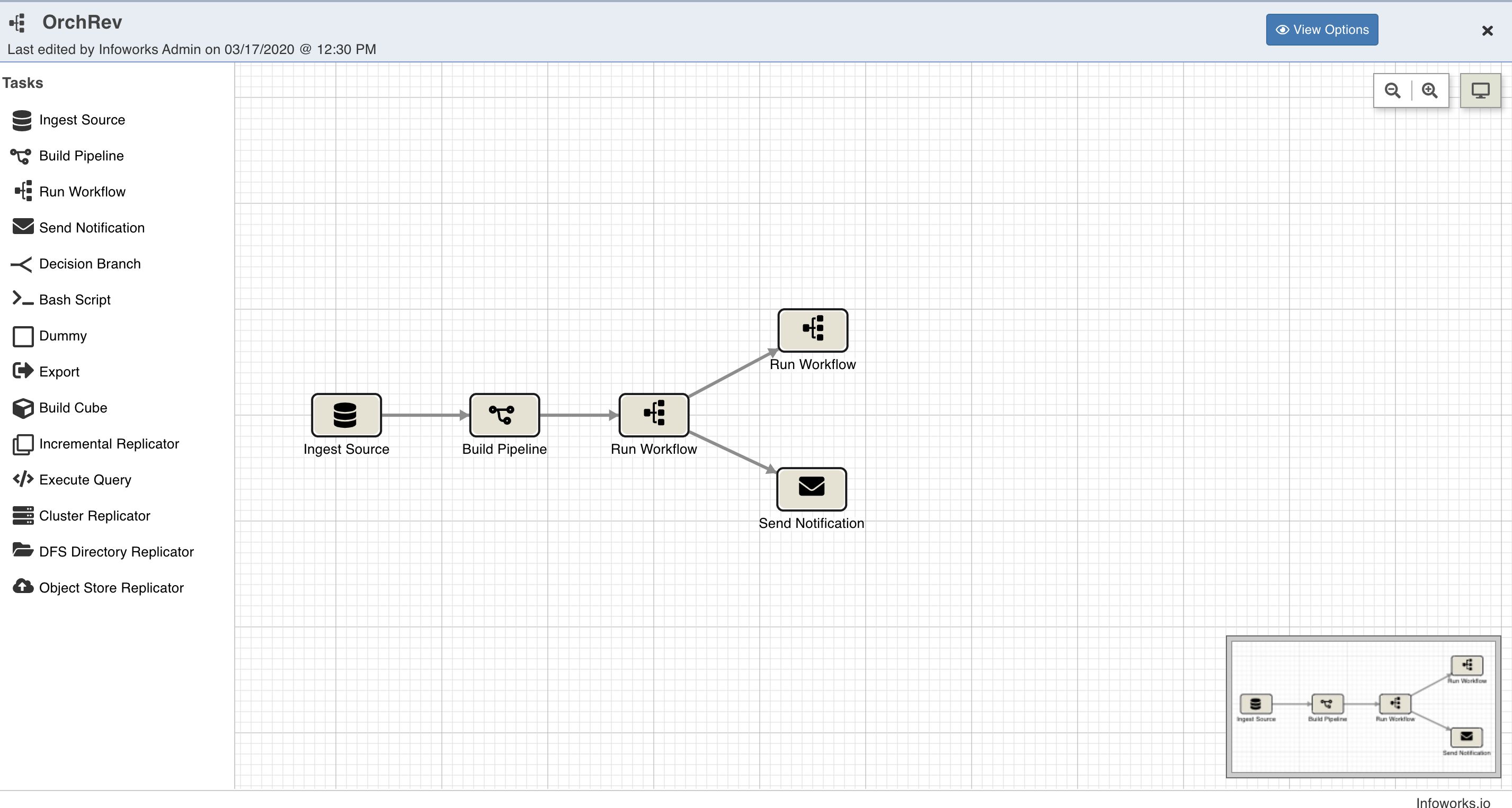
The following sections describe various options available on the Workflow Editor page.
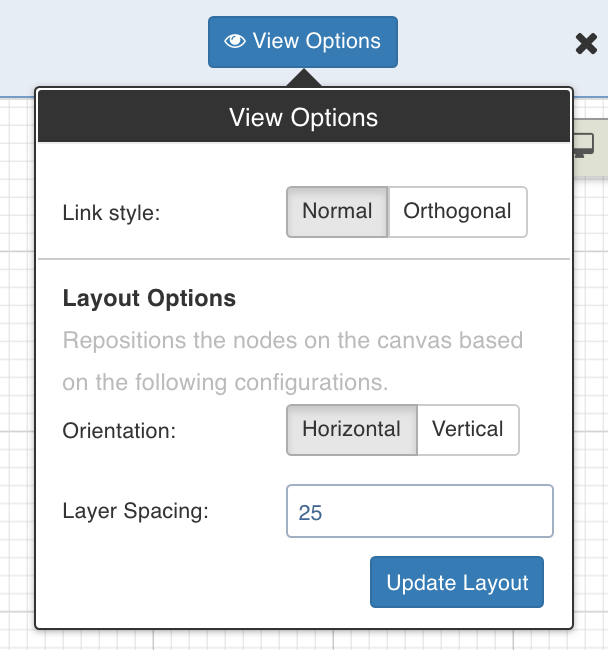
View Options
Click View Options, make the required changes and click Update Layout to select the way you want the workflow to display on the workflow editor page.
Link Style: Normal - displays straight arrows connecting the nodes. Orthogonal - displays right-angular arrows connecting the nodes.
Layout Options: Repositions the nodes on the canvas horizontally, vertically, or as per the layer spacing number provided.
Overview
The Overview option comes in handy if you are working on a complex workflow with many artifacts and tasks, and if the workflow exceeds the normal page view. The icon for the Overview option is represented as seen below:

Click the Overview option to open a pop-up window on the bottom right corner of the workflow editor page. Drag the cursor through the pop-up window to view a specific task/artifact or part of the workflow.
Tasks
This section which appears as a left panel includes a list of all the tasks that can be added to the workflow. To view the properties of a task, drag and drop it to the editor and double-click it.
Following are the available tasks:
The Workflow Variables and Run Settings fields are same for all tasks. These fields are explained below:
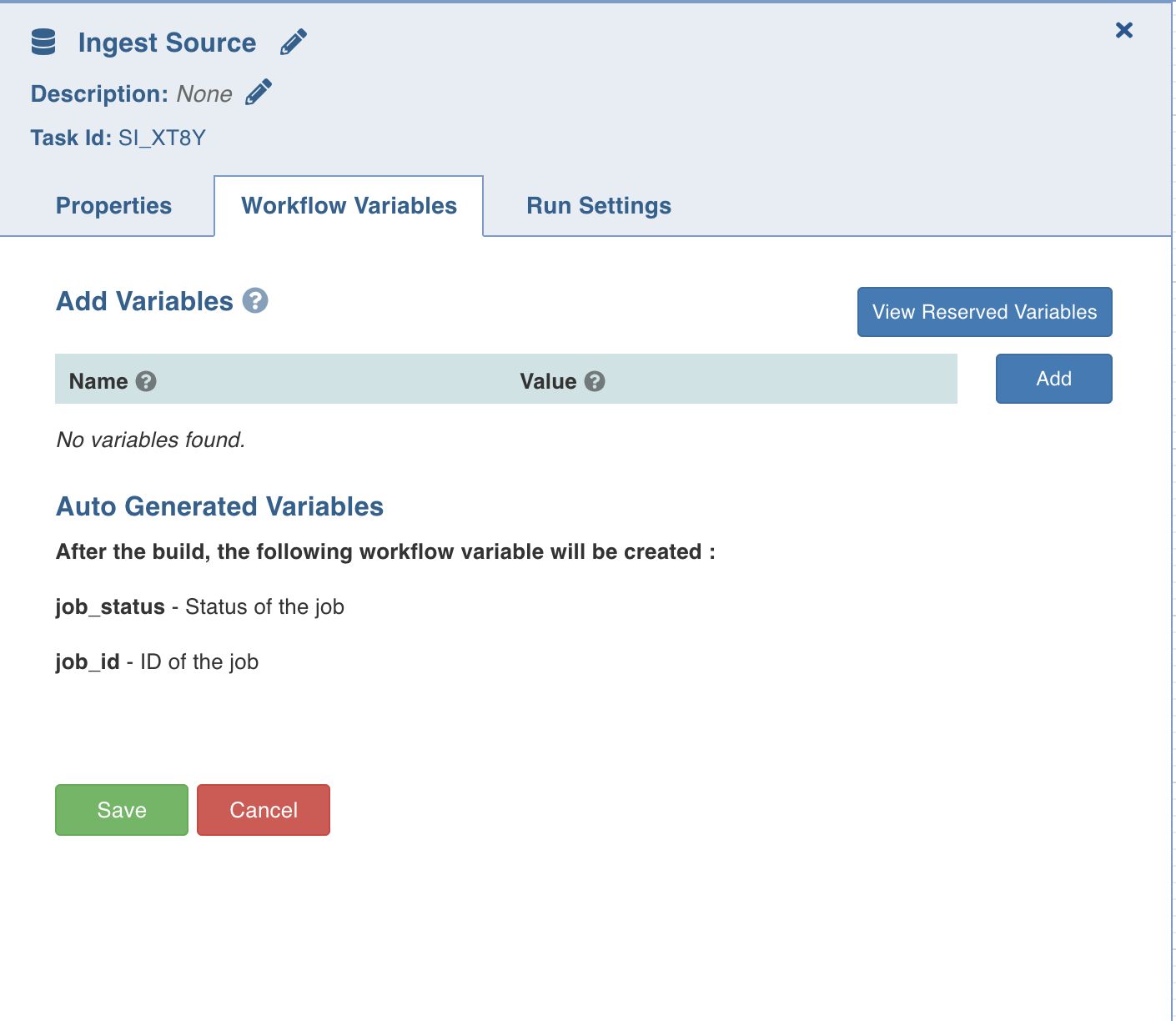
Setting Workflow Variables
Workflow variables are the static variables you can set to use in the downstream nodes. Following are the types of workflow variables:
Auto-generated workflow variables: These are the auto-generated workflow variables that you can see in the Properties section of a task.
User-defined workflow variables: These are the variables that you can set in the Workflow Variables section of a task.
View Reserved Variables: This displays the list of auto-generated and user-defined variables available to be user for this task. Names of the variables listed are reserved, and cannot be reused in this or the downstream tasks.
On the Workflow Variables section, click Add Variables and enter the variable name and value. You can add as many variables as required. These variables will be applied to the downstream nodes and they will override any variable values that are set in the admin or domain configuration settings.
Run Settings
Run settings are the task level settings that control run time behaviour of the tasks in a workflow. Following are the options:
No. of Retries: The number of times a task can be retried before stopping execution and failing. The default value is 0. When this value is set, the following options are enabled:
Delay Between Retries: The delay between two retries. The default value is 300 seconds.
Enable Exponential Backoff: Enabling this option backs off task exponentially after every failed attempt of execution. The retry delay is multiplied by 2 for every failed execution. This option is disabled by default.
Maximum Delay for Retries: This option is displayed when the Enable Exponential Backoff option is selected. Indicates the maximum delay time. The task does not exceed this time while retrying. The default value is 1000 seconds.
Execute when: The set of rules which define the scenario in which the task should be triggered.
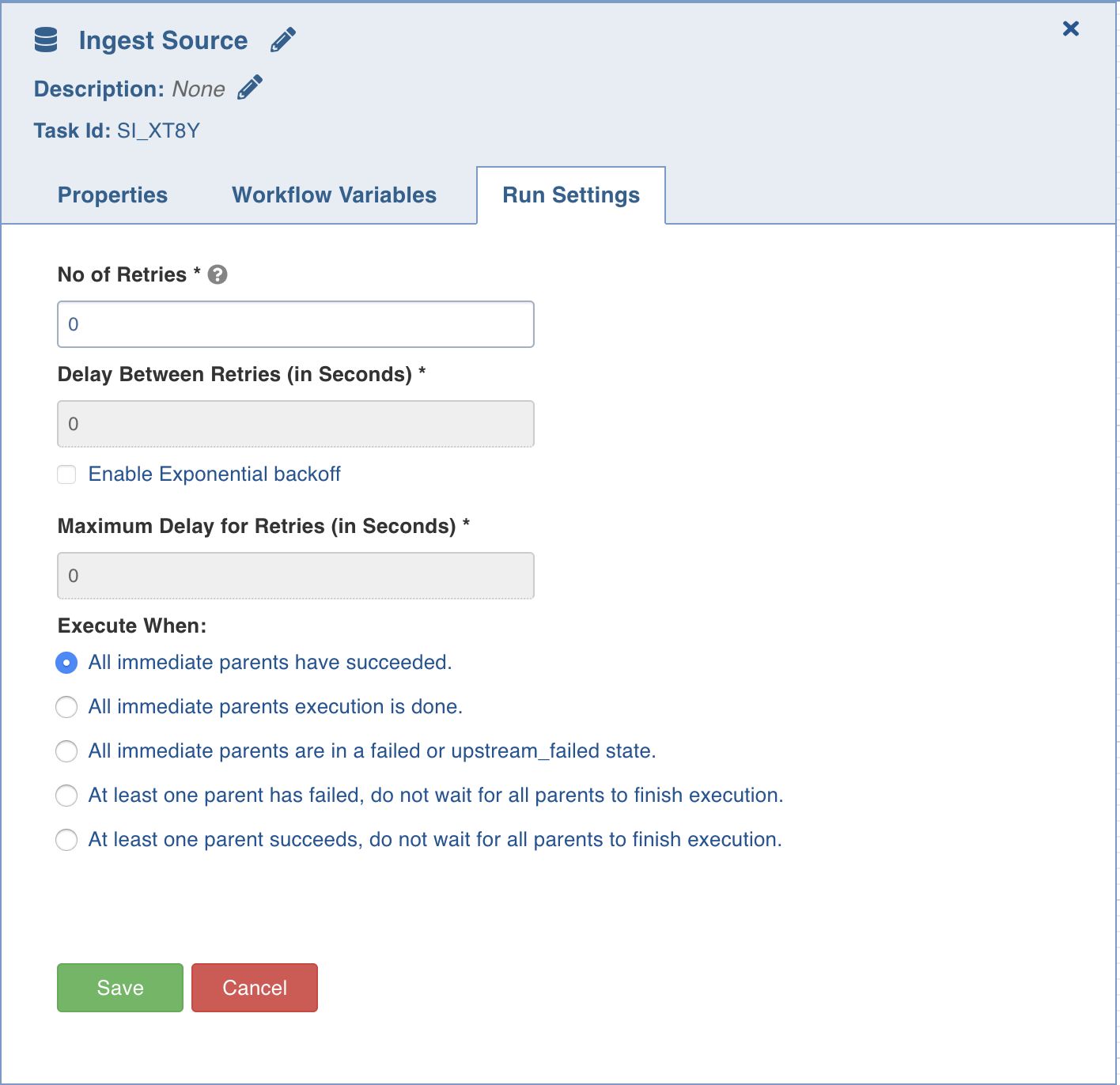
Ingest Source
This option ingests the required source.
Double-click the Ingest Source Table task and enter the following properties:
Title: Click the edit icon to change the default Ingest Source title.
Description: Enter the required task description.
Properties: Select the required Source name, Table group name, and Ingest Type.
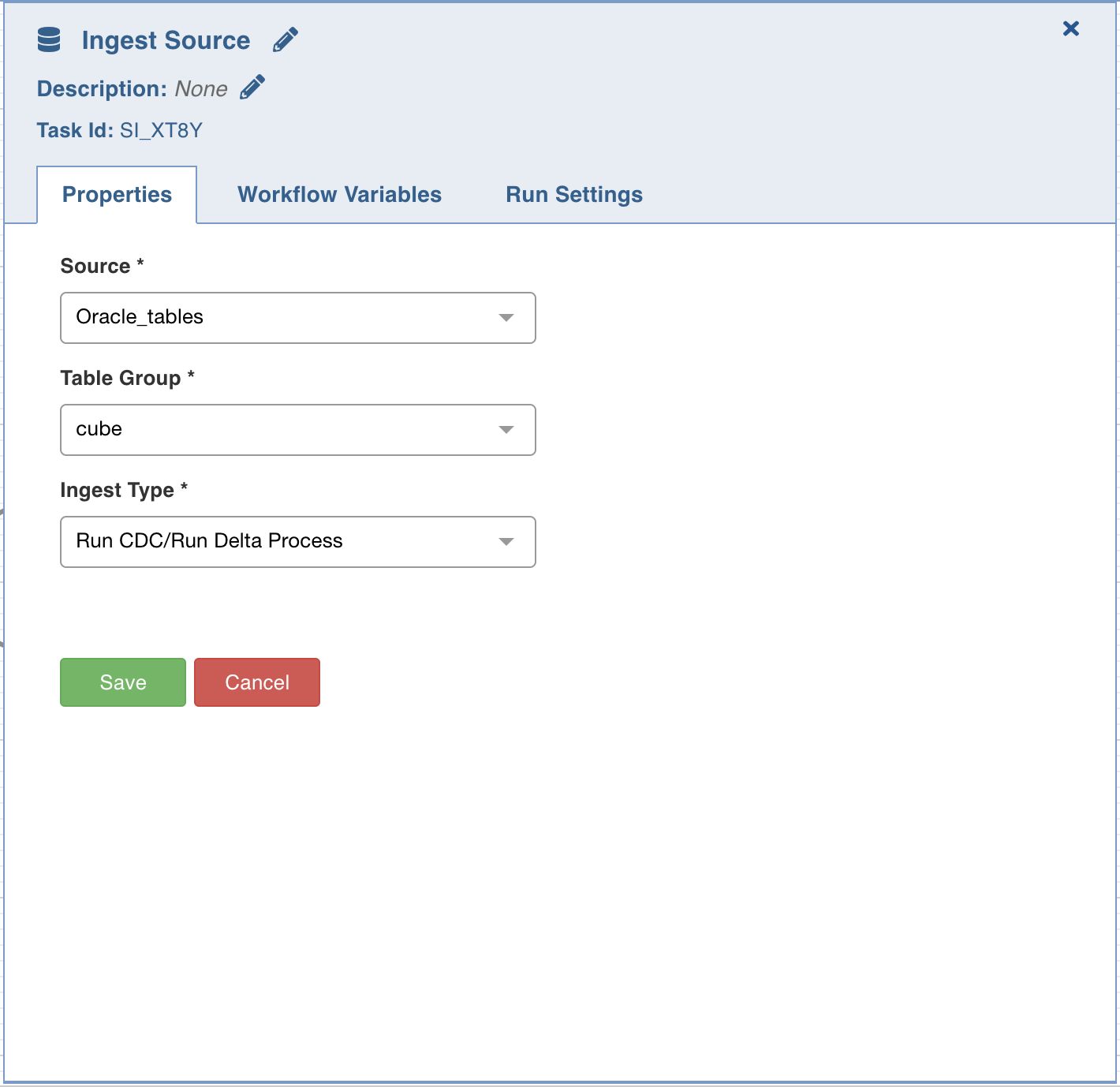
Build Pipeline
The Build Pipeline task, as the name suggests, builds a selected pipeline.
Double-click the Build Pipeline task and enter the following properties:
Title: Double-click the default title Build Pipeline Task to change the title.
Description: Enter the required task description.
Pipeline: From the drop-down, select the required pipeline that you want to build.
Pipeline Version: From the drop-down, select the required pipeline version that you want to build.
Pipeline Parameters: The list of pipeline parameters for the selected pipeline.
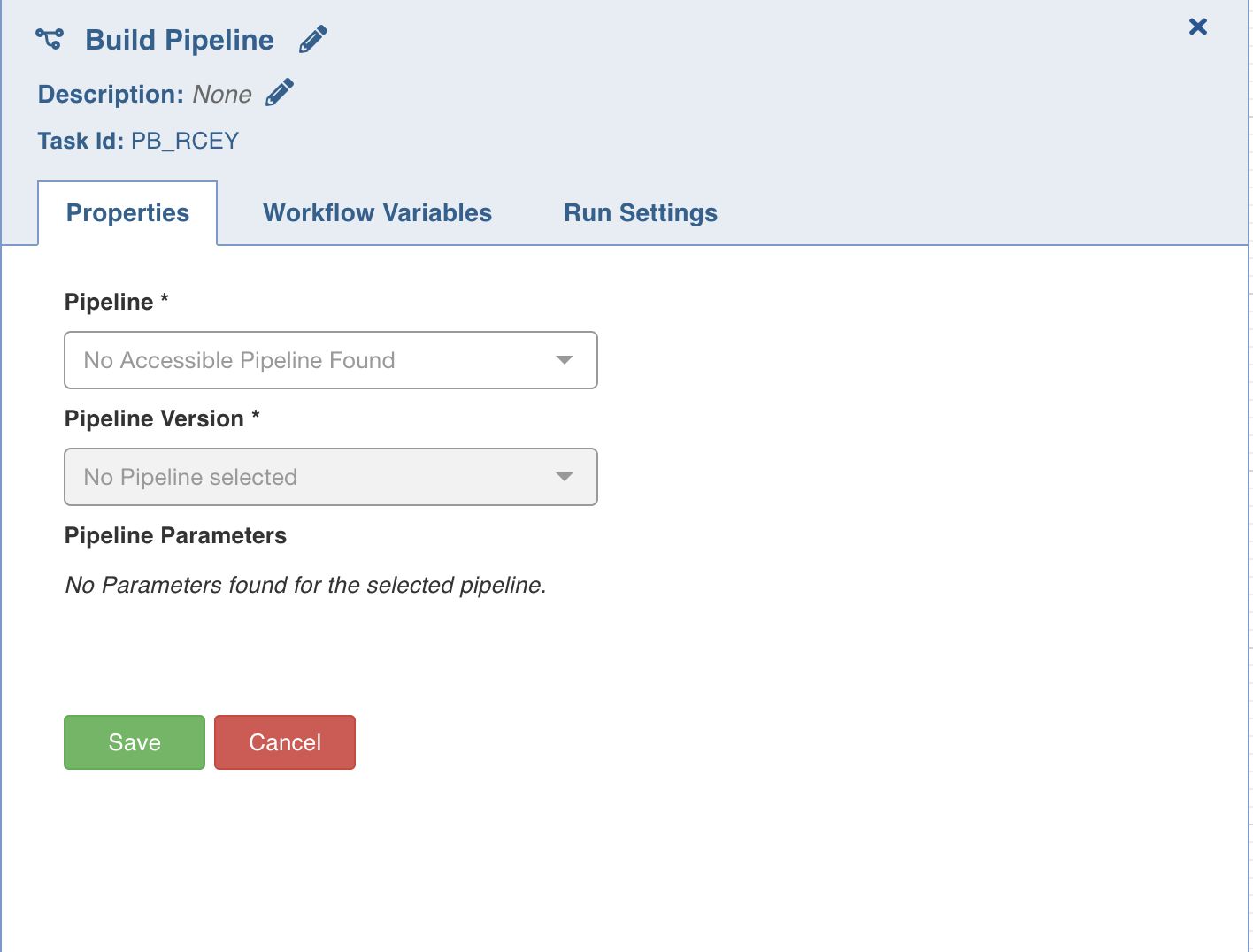
Run Workflow
This node allows you to trigger any workflow within a workflow.
Ensure the following:
You have access to the workflow.
The workflow does not cause a cyclic dependency, which means the workflow being triggered in the node is not an ancestor of the current workflow being edited.
Properties
Following are the Run Workflow properties:
Title: Double-click the default title, Run Workflow, to change the title.
Description: Enter the required task description.
Properties
Workflow: From the drop-down, select the required workflow to run. The lineage of the workflow will be displayed.
View Workflow: You can click this option to directly navigate to the selected workflow.
Lineage: Displays the hierarchy of all workflows in this task to be run.
NOTE The Run Workflow feature will be available only for the existing users. This feature will be deprecated in the upcoming version and hence recommended not to be used.
Execute Query
This task allows you to execute Hive queries.
Following are the examples of queries that can be executed:
select count(*) from ORDER_DETAILS where ORDER_ID=111
select count(distinct ORDER_ID) from ORDER_DETAILS
update ORDER_DETAILS set ORDER_ID = 111 where ORDER_ID = 222
The result of a select query must be a scalar value.
The update query can be executed only when ACID functionality is available with Hive.
Only select and update queries are supported currently.
Double-click the Execute Query task and enter the following properties:
Title: Double-click the default title Execute Query Task to change the title.
Description: Enter the required task description.
Hive Query: Enter the required hive query that you want to execute.
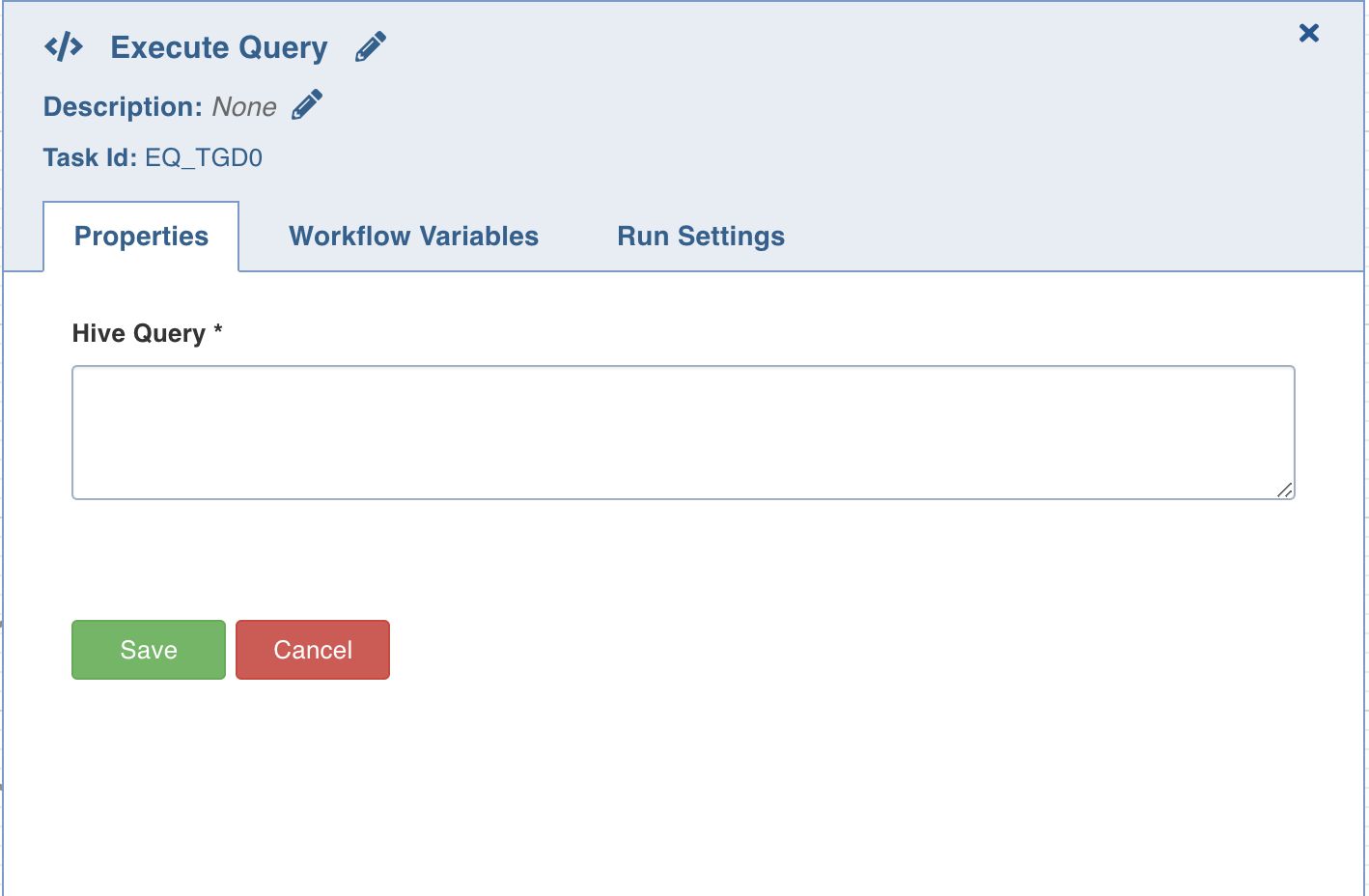
NOTE The Execute Query node does not support a kerberized Hadoop cluster.
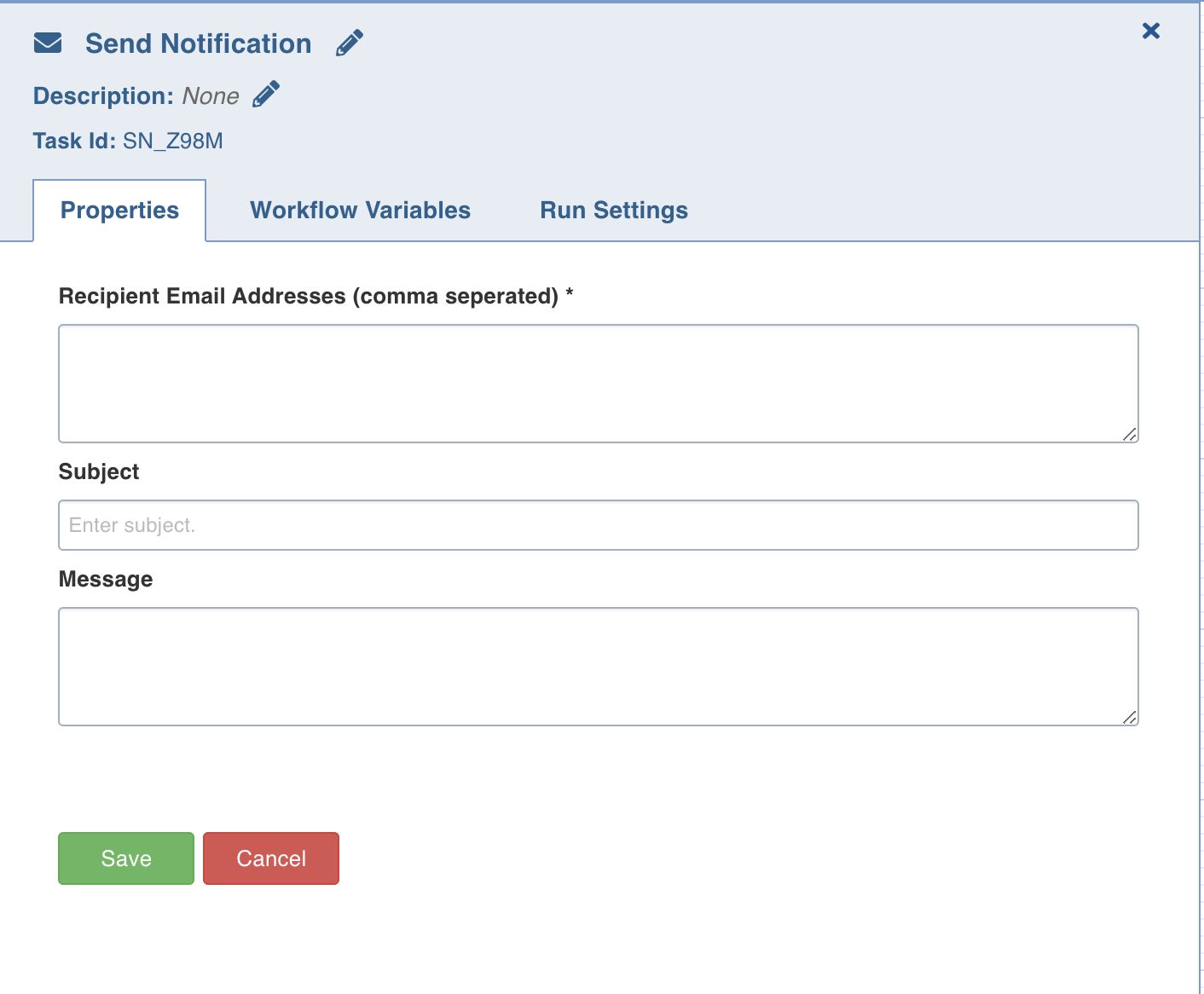
Send Notification
This task sends notification emails to the list of email IDs specified in the task Properties window.
Double-click the Send Notification task and enter the following properties:
Recipient Email Addresses: The recipients to be notified.
Subject: The subject of the mail.
Message: The notification message.
Decision Branch
This task allows you to add workflow control. The conditional logic defined in this task yields in two or more branches and switch paths to take based on the output values of the condition.
Double-click the Decision Branch task and enter the following properties:
Title: Double-click the default title Decision Branch Task to change the title.
Description: Enter the required task description.
Go to Task: Depending on the value fetched from the following when query, select the task that the workflow should flow to.
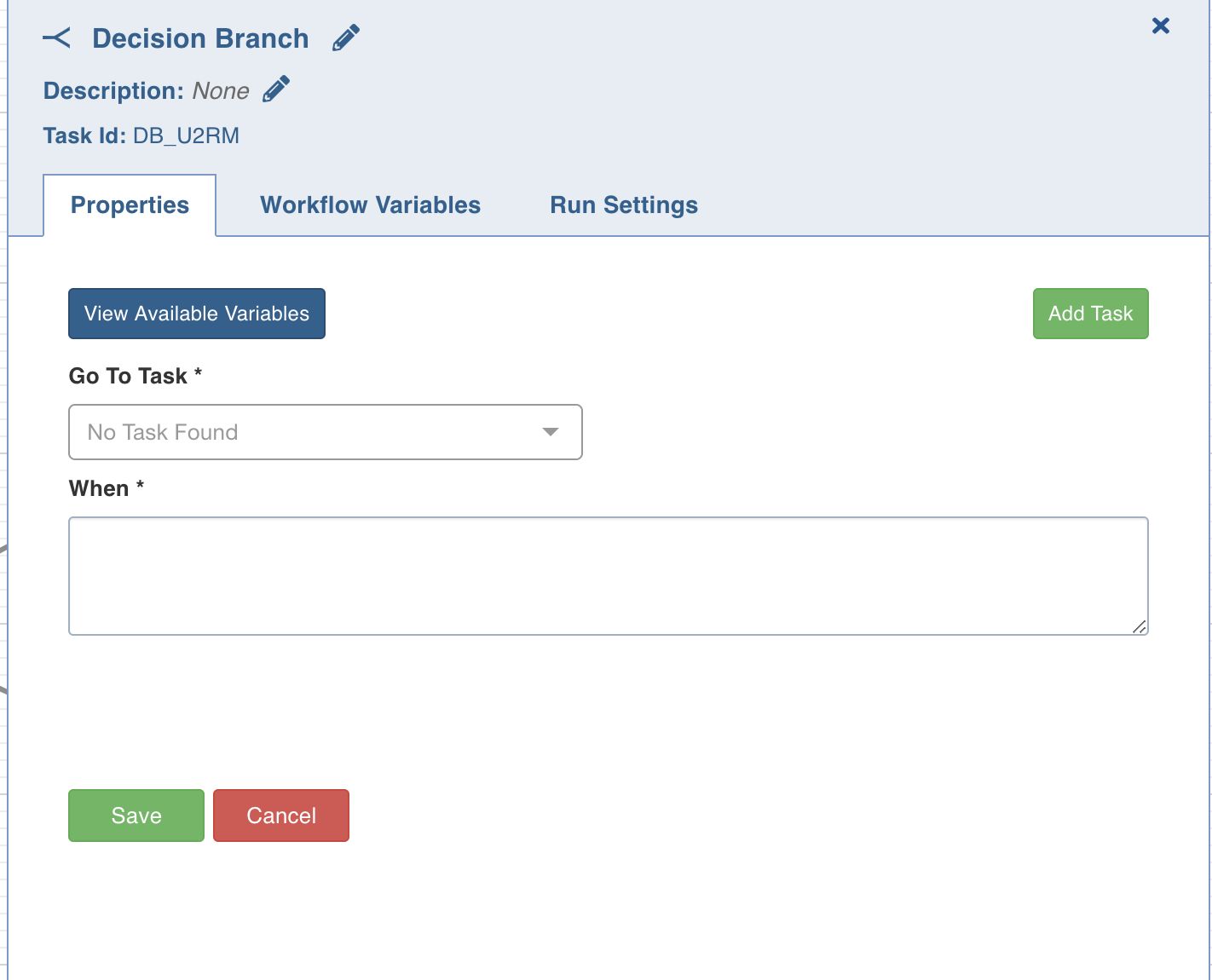
When: Enter a query in the following syntax:
get_value("<task-ID>", "<variable-name>")== '<status>', where<task-ID> and <variable-name>are available in the View available variables option, and values for<status>are success or failed. This syntax is used to retrieve values from the upstream tasks in the same workflow.
NOTE: In the When field, conditions must be entered in Python 3 compatible syntax. The first condition that is satisfied in the workflow is processed, and other conditions are ignored.
For example, get_value("JOB_123", "job_status")=='success'
On clicking the View available variables option, the Available Variables in this Task window is displayed. You can copy the required query using the Copy to clipboard option corresponding to each task ID, and then append the required <status>value using the above described syntax.
NOTE: The When field supports any Python code if you do not have to adhere to the results from the tasks in the same workflow.
Go To Node: Depending on the value fetched from the When query, select the node that the workflow should flow to.
Add case: You can click Add case option to add multiple cases.
View available variables: This option displays if a task has another preceding task connected to it. When you click the option, a page with all the available variables from the upstream tasks displays.
Bash Script
Bash script task can be used to run multiple bash statements. You can enter the bash statements in the text area and they will be executed sequentially.
View available variables: This option displays if a task has another preceding task connected to it. When you click the option, a page with all the available variables from the upstream tasks displays.
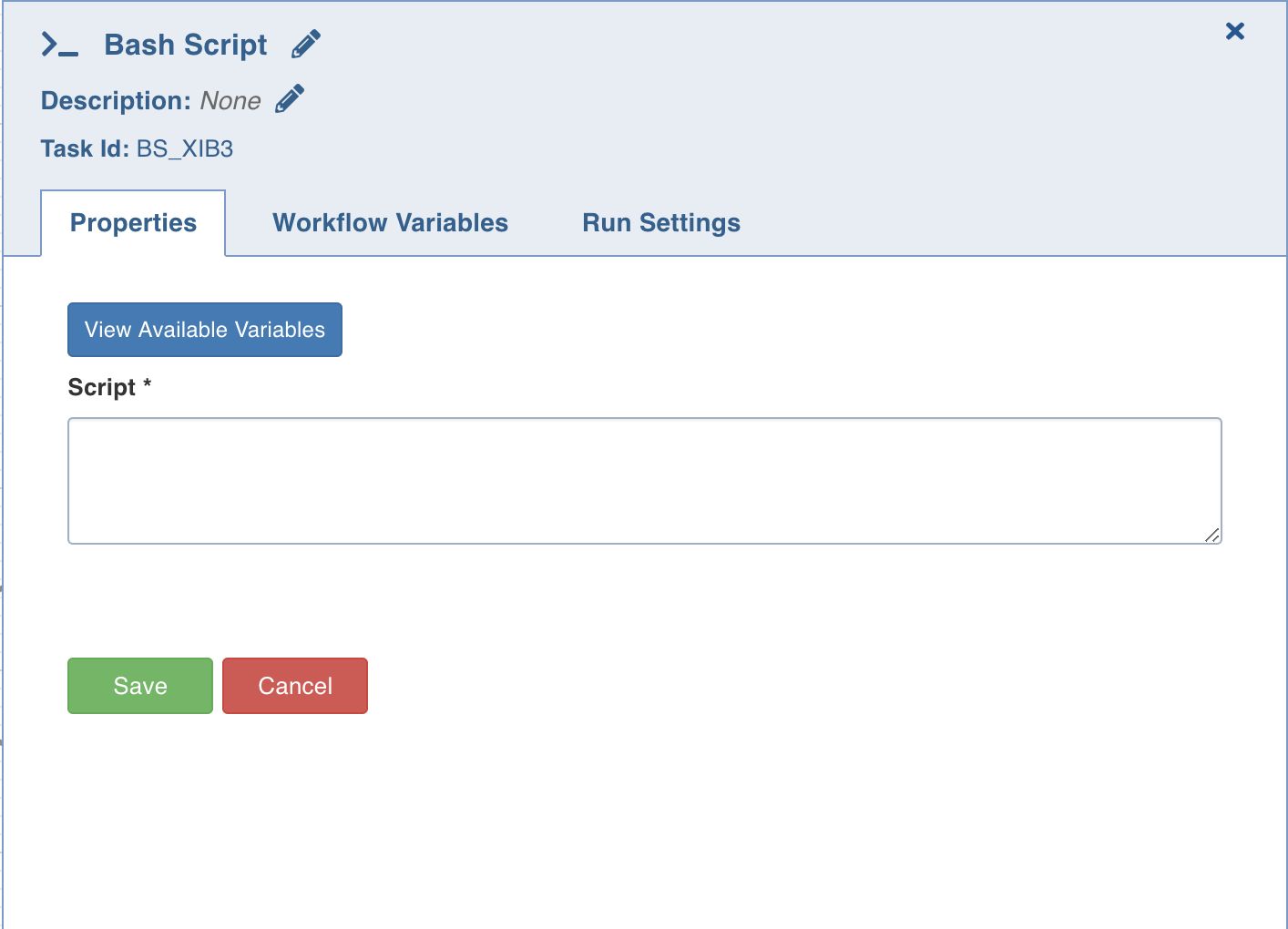
The last thing that will be echoed to the standard system output from the bash commands will be stored as a workflow variable with the name return_value.
Example: ls; pwd;
This will store the current directory in the workflow variable as it is the last value echoed to the standard output.
You can also alternatively run your script files directly using this task by specifying the exact location of your file.
Example: sh /Users/ec2-user/bash-sample.sh python /Users/ec2-user/python-sample.py
Note: _Infoworks DF supports Python 3 engine to run the script files. Hence, ensure that the script entered in the Script field is in Python 3 syntax.
Following are the environment variables that can be accessed within the Bash Node script:
$IW_WF_DAG_ID: Identifier for the current workflow under execution
$IW_WF_RUN_ID: Identifier for the current workflow run under execution
$IW_WF_TASK_ID: Identifier for the current task under execution
$IW_WF_DOMAIN_ID: Identifier for the domain under which the workflow is being executed
Dummy
The Dummy task, as the name suggests, acts as a dummy interface between multiple tasks, each of which must be connected to each other. Adding a dummy task between such tasks will avoid confusions and also makes the workflow look organized.

Export
The export task executes the export job on the selected entity.
Double-click the Export task and enter the following properties:
Title: Double-click the default title to change the title.
Description: Task description.
Export Type: Target entity: Source or Pipeline.
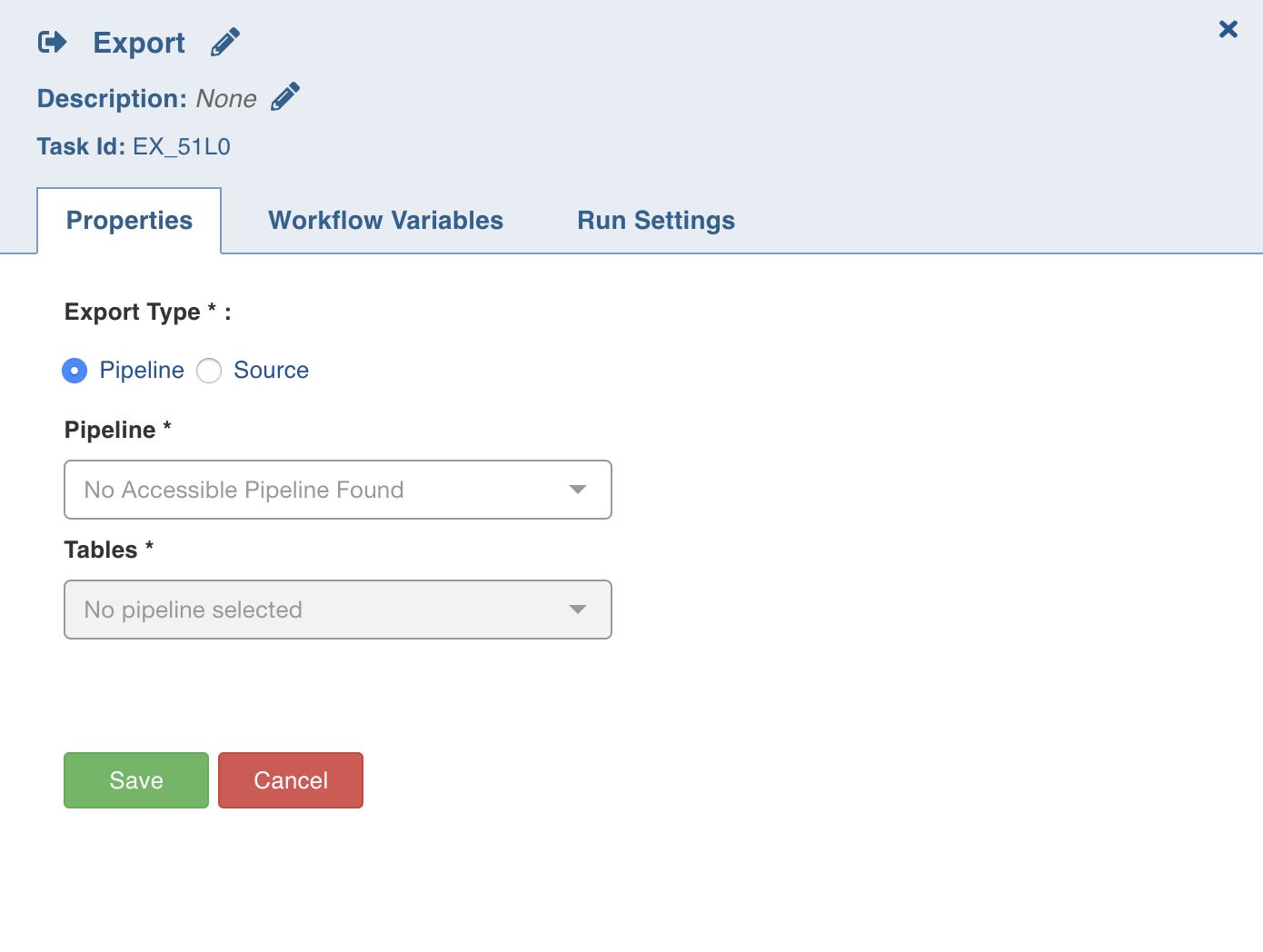
For source, set the following:
Source: List of accessible sources.
Table group: Target table group associated to selected source.
For pipeline, set the following:
Pipelines: List of accessible pipelines.
Table: Custom target table built in the pipeline.
View available variables: Indicates if a task includes another preceding task connected to it.
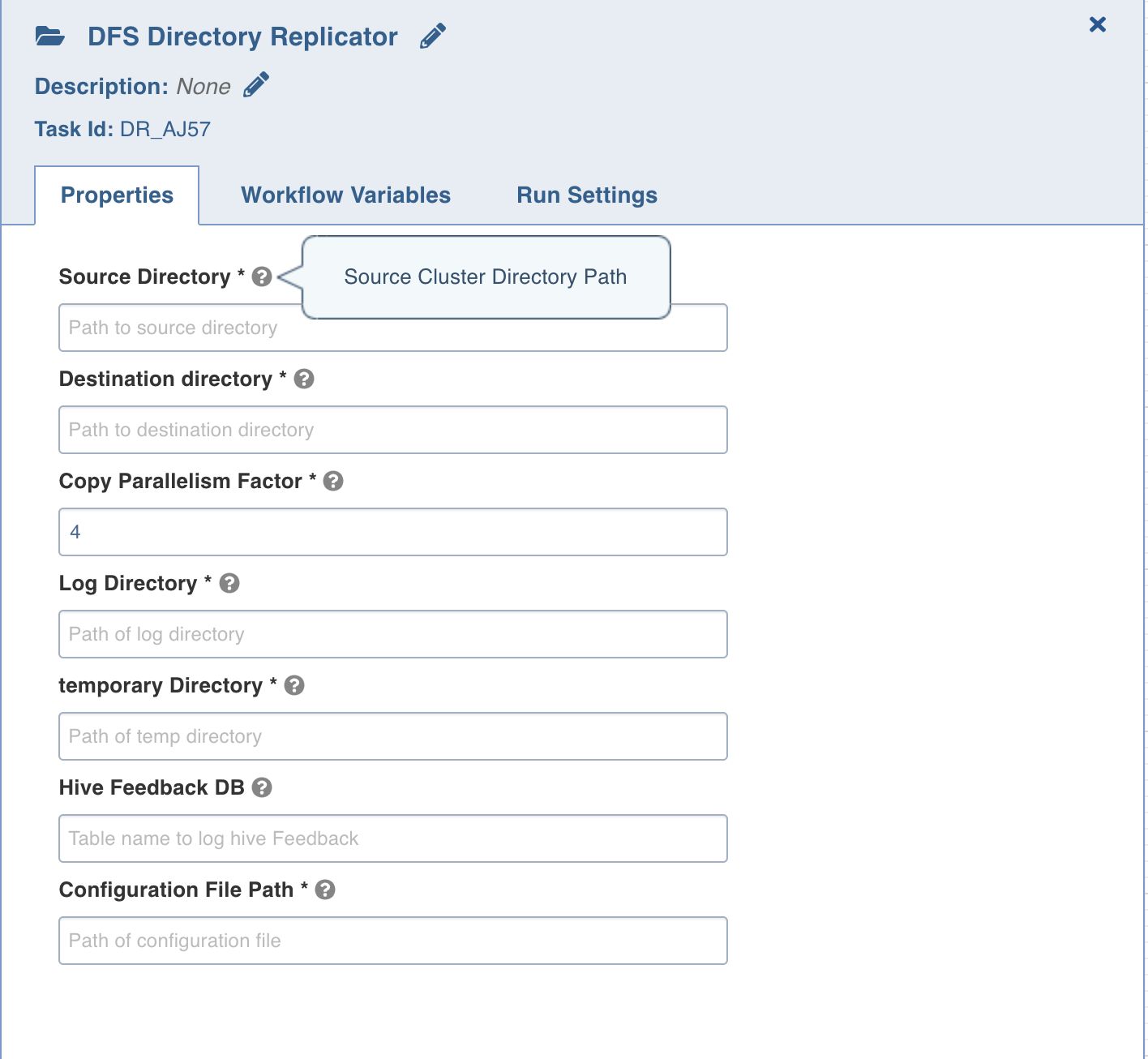
DFS Directory Replicator
This DFS Directory Replicator compares and copies data from the source DFS directory to destination DFS directory. Hive tables are then created for the compared (stage1) and copied (stage2) data.
Double-click the DFS Directory Replicator task and enter the following properties:
Source Directory: The replication source directory.
Destination Directory: The replication target directory.
Copy Parallelism Factor: The number of parallel HDFS copy jobs.
Log Directory: The directory where log files are stored.
Temporary Directory: The temporary directory where the files are first copied before being transferred to the destination directory.
Hive Feedback DB: Database name for Hive where tables for stage 1 and 2 are stored.
Configuration File Path: Option to provide additional/detailed configuration in a file for the job.
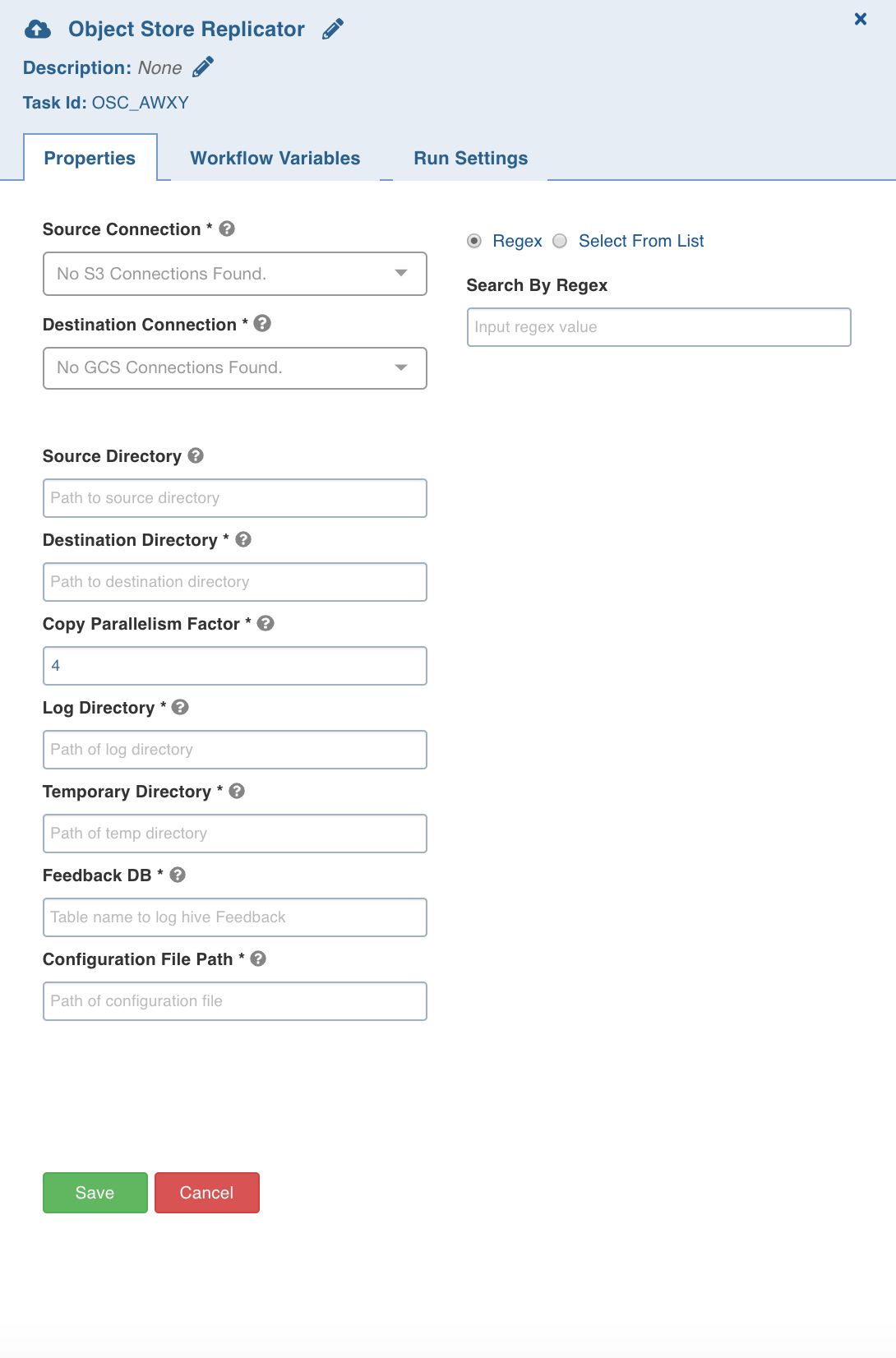
Object Store Replicator
This Object Store Replicator compares and copies data from the source object storage to destination object storage.
Double-click the Object Store Copy task and enter the following properties:
Source Connection: The replication source.
Destination Connection: The replication destination.
Source Files: The list of files and folders in the source. You can select the files and folders using a regex or from the directory structure of the source displayed.
Source Directory: The path to the replication source directory.
Destination Directory: The path to the replication target directory.
Copy Parallelism Factor: The number of parallel copy jobs.
Log Directory: The directory where log files are stored.
Temporary Directory: The temporary directory where the files are first copied before being transferred to the destination directory.
Feedback DB: Database name for Hive where tables for stage 1 and 2 are stored.
Configuration File Path: Option to provide additional/detailed configuration in a file for the job.
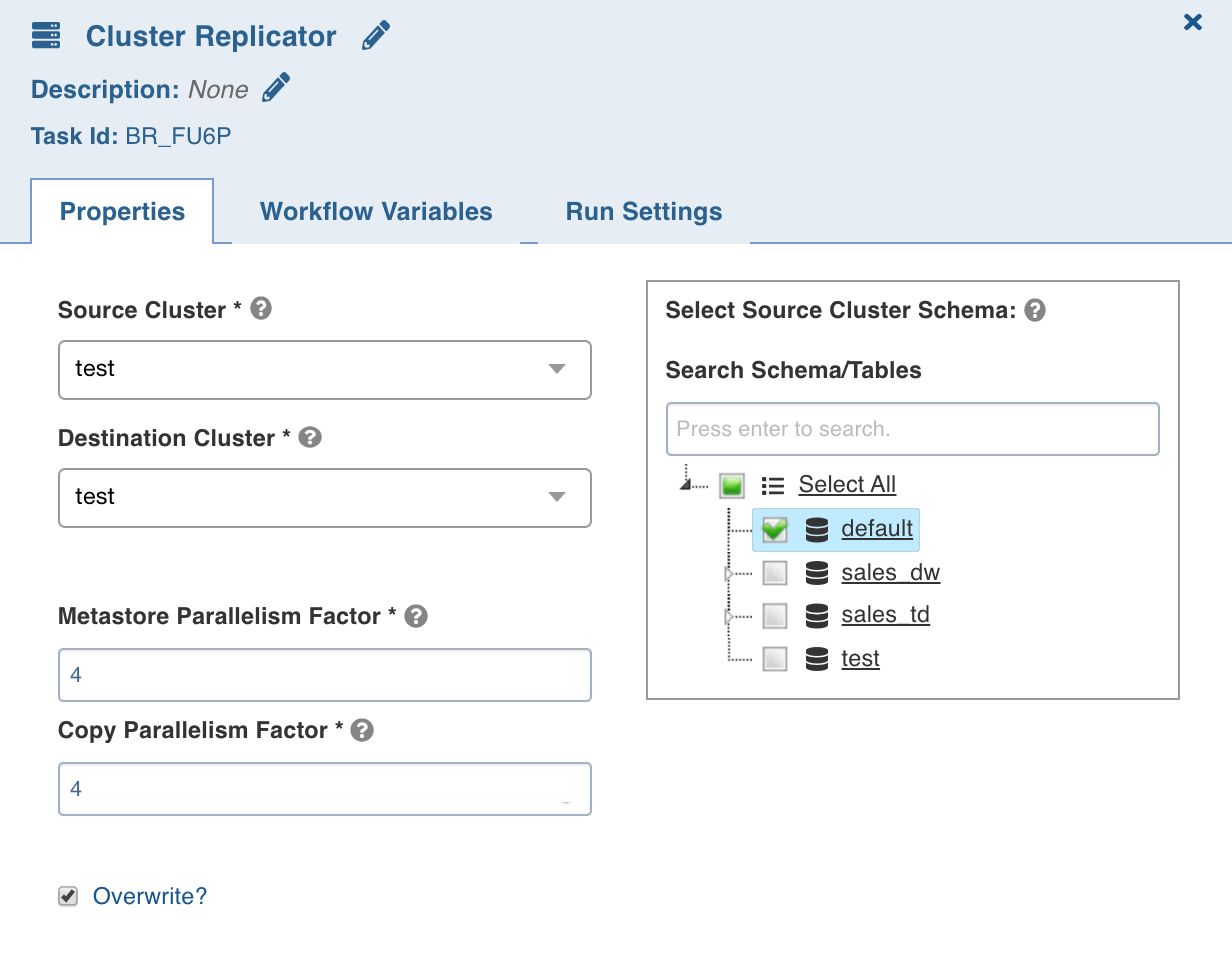
Cluster Replicator
The Cluster Replicator task replicates data from one cluster to another (currently from S3 to GCS).
Double-click the Cluster Replicator task and enter the following properties:
Source Cluster: The replication source.
Destination Connection: The replication destination.
Metastore Parallelism Factor: The number of parallel metadata replication jobs.
Copy Parallelism Factor: The number of parallel HDFS copy jobs.
Overwrite: The option to delete and copy data again, if data already exists at target location.