Prerequisites and Considerations
In Infoworks DataFoundry, data from streams (Kafka/MapR) can be used for incremental ingestion of data. The initial load of the data must be completed before performing ingestion of the streaming data.
Spark must be set up on the cluster.
Order of columns in stream remains the same as it was during the initial bulk load.
Infoworks DataFoundry supports Kafka records in delimited and JSON format (if the source type is JSON).
As most organizations rely on streaming data to provide real-time insights, it is necessary to discover, integrate and ingest data from the sources as soon as it is being produced, in any format and quality.
Infoworks DataFoundry supports ingestion of streaming data into data lakes. Data is stored in either ORC or Parquet format, and is updated via incremental data synchronization from Kafka.
Data Streaming
Before starting ingestion from Kafka, table must be configured for streaming.
Configuring Table
Navigate to the Source Configuration page and click the Streaming tab and select the Enable Streaming checkbox.
Provide the following configuration details:
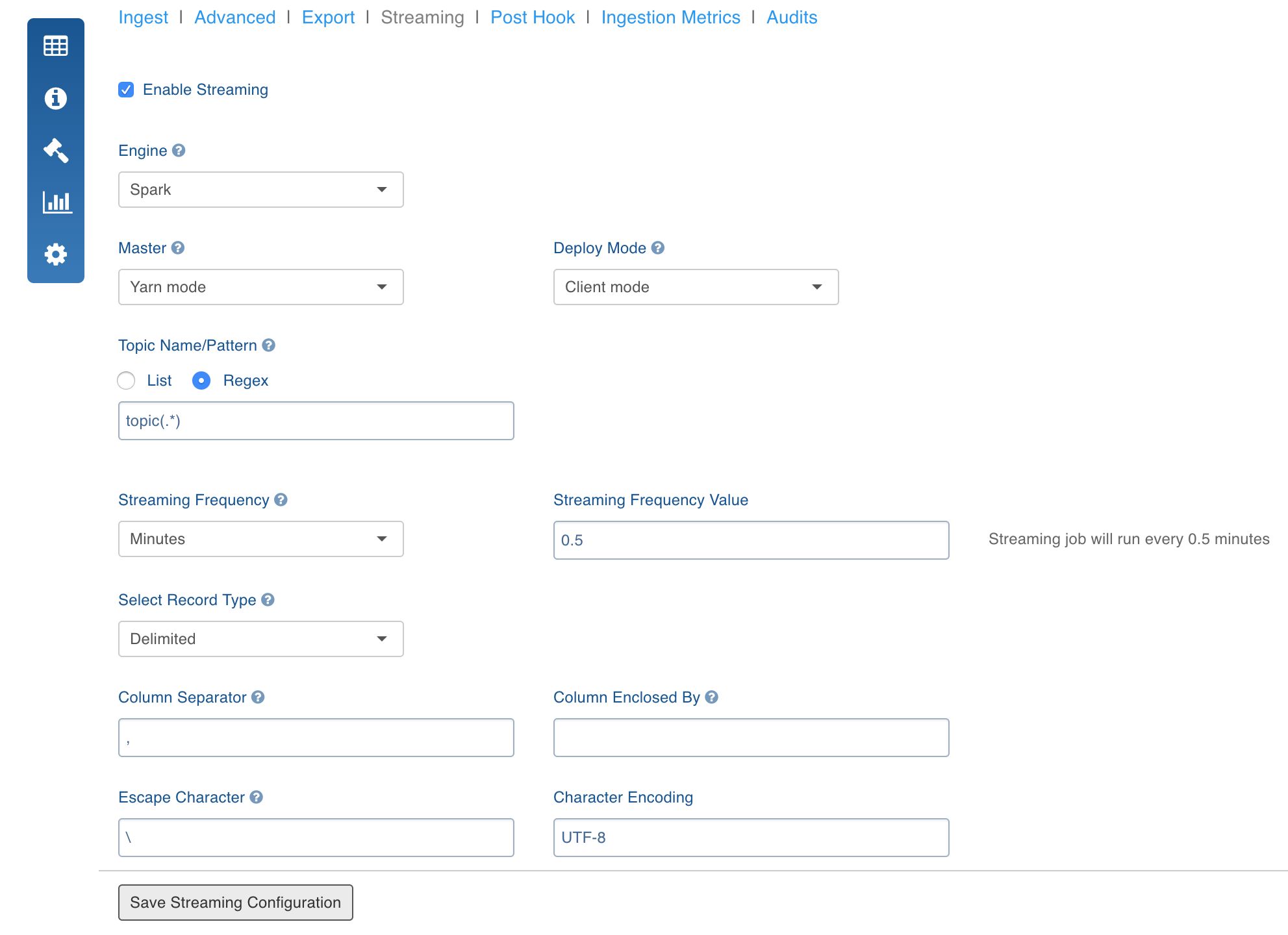
Select the Streaming Engine as Spark.
Select the Spark Master according to the cluster configuration. Spark can run job in Yarn and Standalone mode.
Select the Deploy Mode to run spark on the cluster or only on the edge node (client).
Select Spark streaming frequency based on the use case.
Enter Kafka/MapR Streams topic names/patterns associated to the corresponding table.
Topic name can be,
single, for example, Topic1.
a list, for example, Topic1,Topic2,Topic3.
a pattern, for example, Topic(.)*. In this case, all topics that match the given pattern will be subscribed. For topic regex, it is assumed that all topics that match the entered pattern have records with the same schema. And, any new topic added to a message queue which matches with the regex is subscribed automatically.
Click Save Streaming Configuration.
Setting Streaming Configurations
Set the following mandatory advanced configurations for streaming (Settings > Advanced Configurations > Add Configuration):
spark_home: The Spark installation path (Mandatory).
zookeeper_hosts: The Zookeeper host (Mandatory).
zookeeper_port: The Zookeeper port (Mandatory).
BOOTSTRAP_SERVERS_WITH_PORT: The Kafka Bootstrap servers, comma-separated list of values. For example, 127.0.0.1:9092,127.0.0.2:9092. (Mandatory)
Running Streaming Job
In the Source Configuration page, navigate to the Streaming tab to view the tables configured for streaming.
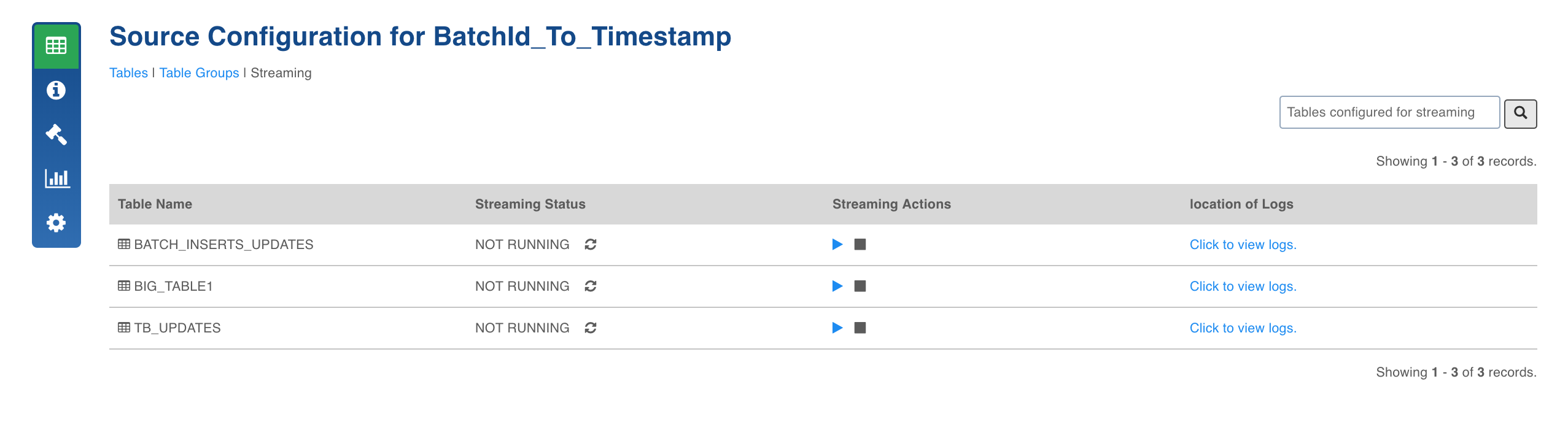
Click the start icon to start the streaming job.
Check the status for streaming job. You can click the stop icon to stop the Streaming job.
Click the Click to view logs option to view the job summary.
Records fetched by the streaming job can be queried using the view created in Hive with the name,
Realtime_<table name>. For example, for the TB_UPDATES table, the realtime view name will be Realtime_TB_UPDATES.
Editing Schema
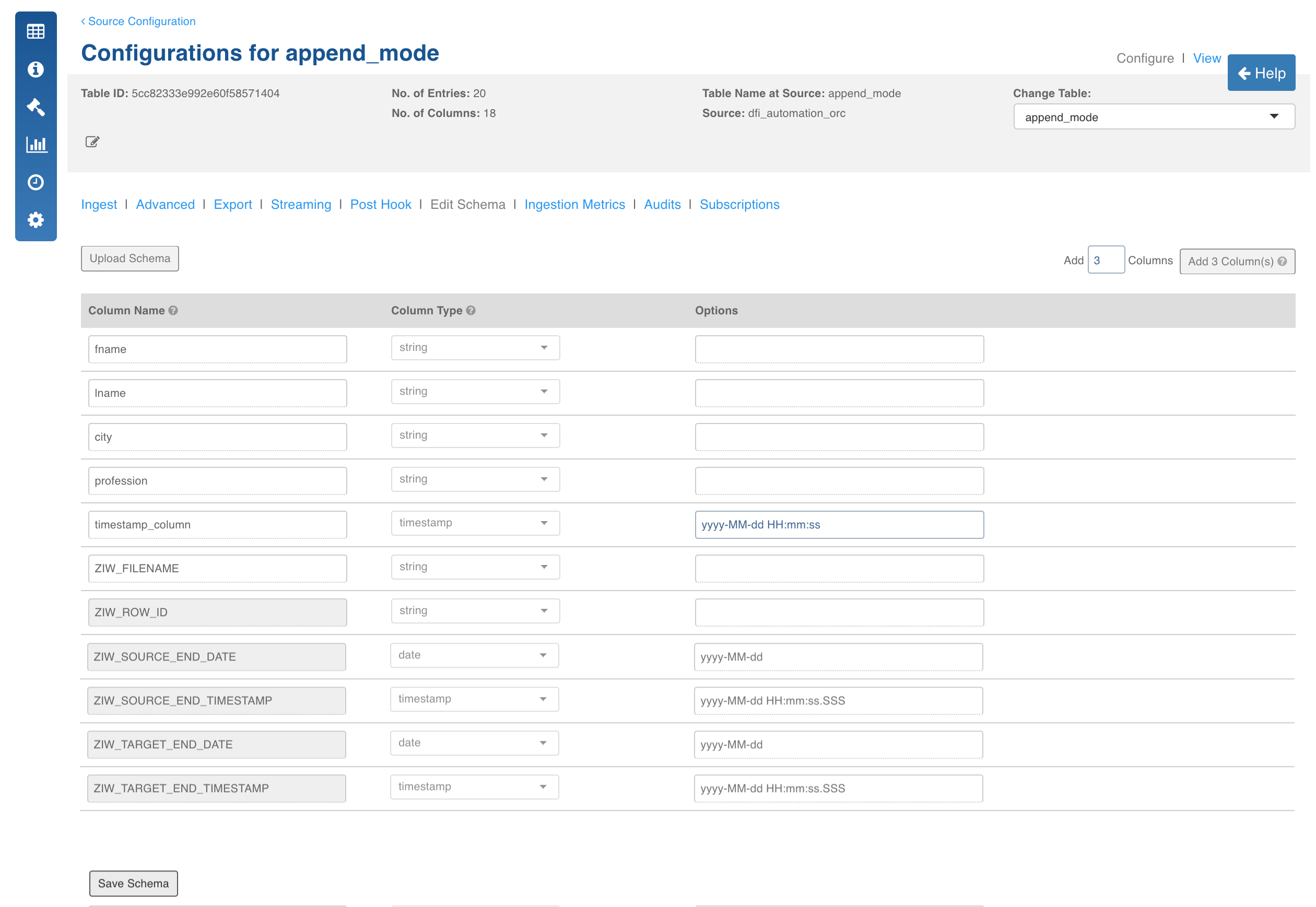
In streaming ingestion, if the data format is different from the file/RDBMS used for full load, you can specify the format by editing the schema. Once streaming is enabled and configured, you can edit the schema using the following steps:
In the Table Configuration page, click the Edit Schema tab.
Edit the required values. You can only edit the Options field value and not the Column Name or Column Type.
Click Save Schema.
Configurations
READ_MESSAGES_FROM: The value can be Kafka or MapR Streams. By default, the value is set as Kafka.
spark_home: The Spark installation path (Mandatory).
zookeeper_hosts: The Zookeeper host (Mandatory).
zookeeper_port: The Zookeeper port (Mandatory).
BOOTSTRAP_SERVERS_WITH_PORT: The Kafka Bootstrap servers, comma-separated list of values. For example, 127.0.0.1:9092,127.0.0.2:9092. (Mandatory)
USE_RECEIVER_BASED_APPROACH: The configuration to use Kafka low level APIs. The default value is false.
consumer_force_from_start: The configuration to force start Kafka consumer from start. The default value is false.
number_of_receivers: The number of Kafka receivers. The default value is 1.
SPARK_STREAM_WINDOW_DURATION_IN_SECONDS: The Spark stream window duration in seconds (source or table level).
SPARK_STREAM_SLIDING_INTERVAL_IN_SECONDS: The Spark stream sliding interval in seconds (source or table level).
spark_master: The Spark master in case of standalone or Mesos.
SPARK_STREAM_YARN_QUEUE: The Yarn queue name to submit spark streaming job.
SPARK_STREAM_DRIVER_MEMORY: The Spark stream job driver memory. For example, 1g, 2g. The default value is 1g.
SPARK_STREAM_EXECUTOR_MEMORY: The Spark stream job executors memory. For example, 1g, 2g. The default value is 1g.
SPARK_STREAM_DYNAMIC_ALLCOATION: The Spark dynamic resource allocation. The default value is false.
SPARK_STREAM_EXECUTOR_CORES: The number of cores in each executor. The default value is 1.
KAFKA_GROUP_ID: The Kafka consumer group ID. If the ID is not specified, Infoworks DataFoundry creates an ID.
KAFKA_KEY_DESERIALIZER: The custom key deserializer. You can extend org.apache.kafka.common.serialization.Deserializer to write the custom deserialize and configure the same class to be used by Infoworks DataFoundry. The default value is StringDeserializer.
KAFKA_VALUE_DESERIALIZER: The custom value deserializer. You can extend org.apache.kafka.common.serialization.Deserializer to write the custom deserialize and configure the same class to be used by Infoworks DataFoundry. The default value is StringDeserializer.
SASL_MECHANISM: The SSL Mechanism used to connect to Kafka.
SECURITY_PROTOCOL: The security protocol used to connect to Kafka.
SSL_TRUST_STORE_LOCATION: The Truststore location (truststore must be present in same location on all the nodes).
SSL_TRUST_STORE_PASSWORD: The Truststore password.
KERBEROS_KEYTAB_FILE_PATH: The Kerberos Ketab file path.
KERBEROS_PRINCIPAL: The Kerberos principal to be used by the streaming ingestion job.
DRIVER_JAVA_OPTIONS: The additional java options to be passed to Spark stream driver.
EXECUTOR_JAVA_OPTIONS: The additional java options to be passed to Spark stream executors.