Leveraging HBase Namespace to Isolate IW Cubes
HBase Namespace feature uses the namespace to isolate Infoworks-related data/cubes from other applications on a shared HBase cluster.
This ensures secure and safe accessibility of Infoworks data. It allows only the Infoworks admin to create and drop the tables on the cluster and denies permissions for other users to access them.
To configure a cube to use namespace feature, follow these steps:
Enter the command cd {IW_HOME}/cube-engine/conf/.
Locate the file kylin.properties.
Assign a unique namespace for the cube: kylin.storage.hbase.namespace=iw_cube where, iw_cube is the namespace.
NOTE: Ensure that the HBase namespace exists. If you do not specify the name for the namespace, the data will be added to the default namespace on the HBase cluster.
Restart the cube engine.
Query Pushdown for Unsupported/Unknown Cube Queries
Query pushdown feature allows to run queries that are not supported by the materialized Cube on underlying engine like Hive and spark. For example, using a measure in a query which is not defined in a cube will result in an error because cube is not aware of such measure. In such cases, with query pushdown enabled, your query will pass and return results from underlying tables.
Queries served by Underlying engine will be relatively slower than Cube queries.
If underlying engine table used in query has updates, then you may end up in wrong result.
NOTES:
To configure a cube to use Query pushdown feature, follow these steps:
In the Admin page, click the Configuration icon.
In the System Configuration page, click Cube tab.
In the Cube Configuration page, select pushdown engine from the drop-down list and save changes. The following page shows configurations for setting Hive as pushdown engine.
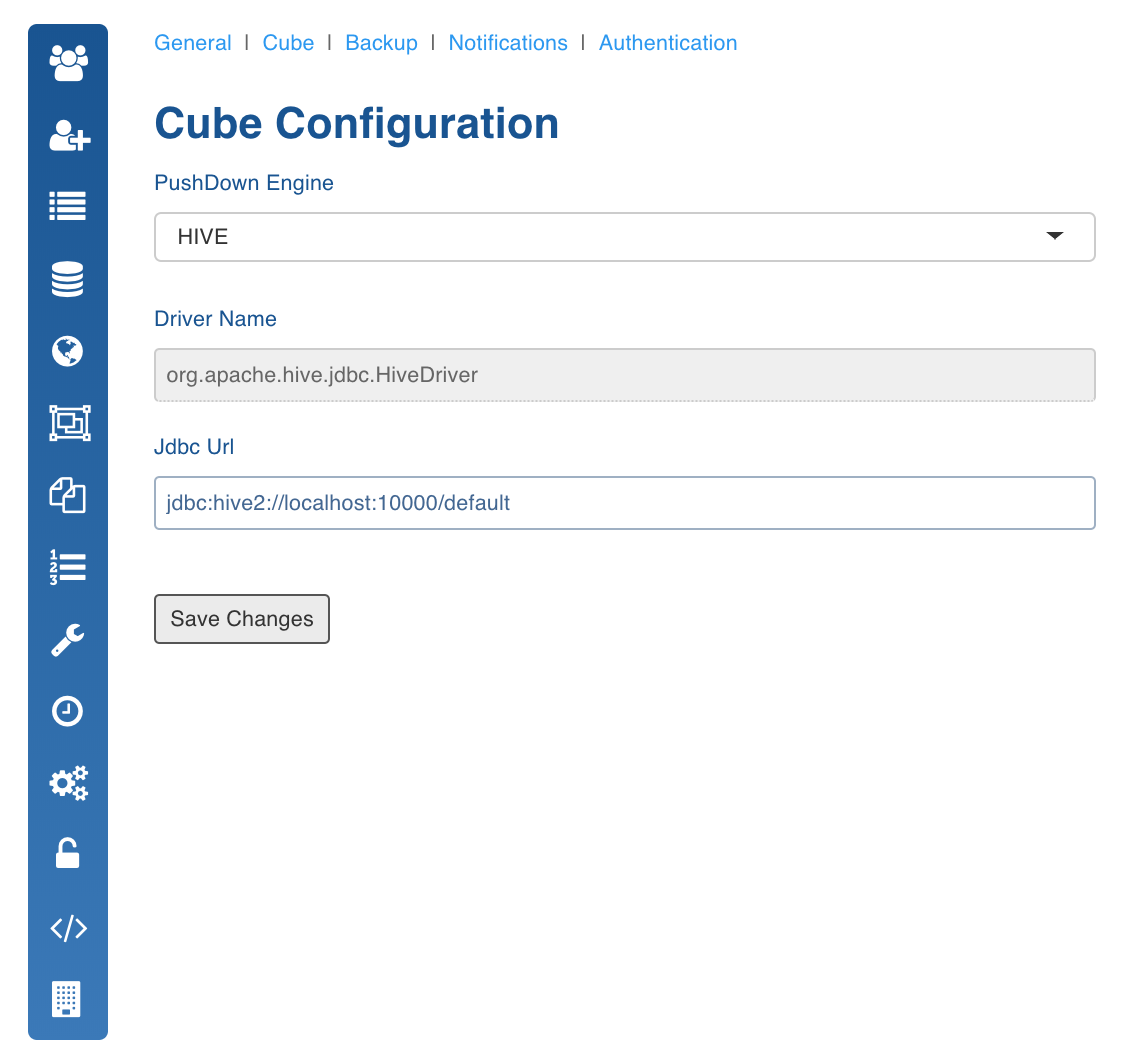
To disable pushdown engine query redirection, select None in the pushdown engine drop-down and save changes.
On setting the above configurations, queries will redirect to pushdown engine if not known to Cube. If the pushdown engine is set and you want to further configure cube engine to block certain type of queries and run them on pushdown engine, you can add the below configurations in cube engine. All these configurations must be added in kylin.properties.
Limit number of rows returned by select all query:
kylin.query.force-limit. Default value is -1, which denotes it does not apply any limit and return records based on user query.Limit number of derived dimensions that can be used in a query:
kylin.query.derived.dimension.force-limit. Default value is 1, which denotes that maximum 1 derived dimension is allowed in user query.Limit number of cross aggregation group columns that can be used in a query:
kylin.query.cross.aggregation.group.columns.force-limit. Default value is 1, which denotes that maximum 1 cross aggregation group column is allowed in user query.Limit number of unknown measures that can be used in a query:
kylin.query.unknown.measures.force-limit. Default value is 1, which denotes that maximum 1 unknown measure is alowed in user query.
NOTE: Any modification made in above configurations will require a restart of the cube engine.