The tables or sources that are fully ingested will always be truncated and reloaded on target.
Following are the steps to perform full ingestion for a table:
Click the Sources menu and click the required source.
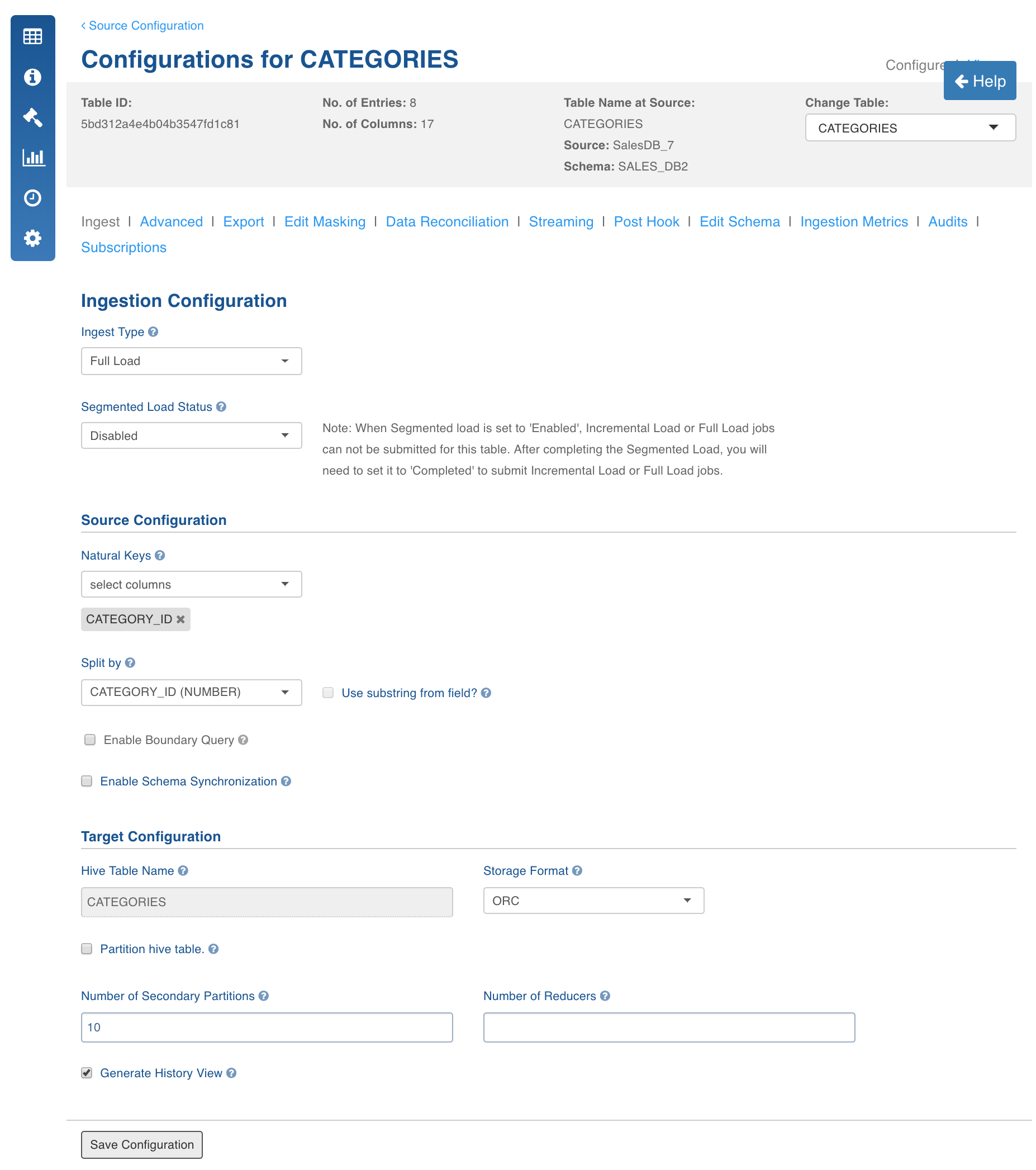
Click the Configure button for the required table.
In the Configuration page, set the Ingest Type to Full Load, and enter the required values.
Using TD Wallet for Teradata TPT Source
NOTE: Ensure that TD Wallet has been set up for the Infoworks user.
If the Source Type is Teradata and the Fetch Data Using is TPT, you can specify the Teradata Wallet Key, where the database password is stored.
For example, if the TD Wallet is set up and a key, TD_PASSWORD, is added with the database password as the value then, when configuring the source for TPT, you can select the Is Teradata wallet setup for Infoworks user? option and provide the key (TD_PASSWORD in this example) in the Key to retrieve Teradata Password from Wallet field to retrieve the password from the Teradata wallet.
Table Configuration Field Descriptions
The following table includes the fields related to all ingestion types. Refer to this table for source table configuration of all ingestion types.
Configuration Parameter | Description |
|---|---|
<b>Ingestion Configuration</b> | |
Ingest Type | Describes ingestion type of the table. {types} |
Segmented Load Status | Used to crawl large tables by breaking into smaller chunks. <i>For detailed configuration parameters, see <a private-link="true" section-type="doc" section-id="2973" page-id="12057" href="/2.7.0/product-documentation-2.7.0/segmented-ingestion">Segmented Ingestion</a></i>. |
<b>Source Configuration</b> | |
Natural Keys | Used to identify the row uniquely. This field is mandatory in incremental ingestion tables. This is used to identify and merge incremental data with the already existing data on target. Distribution of data into secondary partitions for a table on target will be computed based on the hashcode value of the natural key. <br><p><b>NOTE</b>: <i>You cannot update the value of natural key column while updating a row on source; all the components of the natural key are immutable.</i></p> |
Split by | Used to crawl the table in parallel with multiple connections to database. Split-by column can be an existing column in the data or derived from an existing column. <br>The <i>numbers, date, datetime </i>and<i> timestamp</i> columns are allowed to be selected as split-by key. In general, any column for which min and max can be computed, can be a split-by key.<br> <br><p><b>NOTE</b>: <i>Keys which increase or decrease gradually can be used as split-by. </i></p><p><span>Click the <b>Use substring from field</b> option to derive a split-by column from an existing column.</span></p> |
Use substring from field? | Check this option and enter the other field values to derive from the parent column.<br><b>NOTE</b>: <i>In case of date, datetime, timestamp column types you can derive a split-by. The possible split-by options are year, month, year-month, month-day and day-num-in-month.</i> |
Enable Schema Synchronization | Used to synchronize the Hive table schema if the source table is modified after ingestion. Check this option to enable schema synchronization. <br><p><b>NOTE</b>: <i>For the </i><i>timestamp, query-based, and Batch ID-based ingestion</i><i> types, this option is displayed in the <b>Synchronization Configuration</b></i><i> section of the page.</i></p> |
Enable Boundary Query | The query to use for creating splits. For details, see the <a href="https://devhub.infoworks.io/2.7.0/product-documentation/advanced-ingestion-functionalities#boundary-query">Boundary Query</a> section. |
<b>Synchronization Configuration</b> | |
Timestamp Column for Insert | Source column to be used as insert watermark. |
Timestamp Column for Update | Source column to be used as update watermark.<br><b>NOTE</b>: <i>It can also be the source column to be used as insert watermark.</i> |
Slowly Changing Dimension Type | Type of the query based ingestion. Slowly Changing Dimension 1 (SCD1) always overwrites the existing record in case of updates.<br> |
Configure Insert Query | Query to be configured to obtain the incremental inserts. The query must be able to select all the columns in the table along with the timestamp in the audit table. |
CDC Start Date | CDC start date and time. |
CDC End Date | CDC end date and time. |
External Audit Schema Name | Audit table schema where the audit information of <i>rec</i>add<i>ts</i> for the table is maintained. |
External Audit Table Name | Audit table name where the <i>rec</i>add<i>ts</i> for the record is stored. |
External Audit Join Column | Join column between audit table and source table. |
External Audit Timestamp Column | Timestamp column in the audit table, which maintains record audit. |
Batch-ID Column | Column used to fetch delta. |
Start Batch ID | Numeric value of<i> Batch ID</i> column (configured by the user during table configurations) starting which the delta is fetched. |
End Batch ID | Numeric value of <i>Batch ID</i> column (configured by the user during table configurations) till which the delta is fetched. |
<b>Target Configuration</b> | |
Hive Table Name | Name of the table in Hive which will be used to access the ingested data. |
Storage Format | Storage format (ORC or Parquet) |
Partition Hive Table on | Used to partition the data in target. The partition column also can be derived for <i>date</i>, <i>datetime</i> and <i>timestamp</i> column. This will further partition the data. A hierarchy of partitions are supported with both normal partitions and derived partitions.<br><p><b>NOTES</b>: <i>Ensure that the partition columns data is immutable.</i></p><p><i>You can provide a combination of normal and derived partitions in the hierarchy. </i></p> |
Extract a New Column | Check this option for supported datatypes to derive a partition from an existing column.<br><b>NOTE</b>: <i>Fill the corresponding field values based on the derived type</i>. |
Is Epoch | <p>When extracting a new column, checking this field indicates whether the selected column is epoch. This allows you to select the partitions from epoch value based on the <strong>date’s</strong> function. For example, year month, year, month, date.</p><p>Epoch is supported for all numeric datatypes except <strong>int</strong> and <strong>float</strong>.</p> |
Derived Column Name | This is a mandatory field to be filled when deriving a partition column.<br><b>NOTE</b>: <i>Ensure no other columns in this table have the same name.</i> |
Extract Function | The extract function. If the parent column is a timestamp or date column, you can select extract function as one of the following: day num in month, month, year, year month, month day. If the parent column is other than timestamp or date, use the regular expression as the extract function. <br><b>NOTE</b>: <i>This is a mandatory field to be selected when deriving a new column.</i> |
Data file pattern (regex) | If you select regular expression as the extract function, you must enter corresponding regular expression. <br><b>NOTE</b>: <i>This field is a mandatory field if regex is used as an extract function.</i> |
Extract format | When using regex derived partition, this field specifies the values to extract from a data pattern to partition the data.<br><b>NOTE</b>: <i>This field is mandatory if regex is used as an extract function.</i> |
Number of Secondary Partitions | The target data can be distributed among various partitions and each partitions in turn can have various secondary partitions. A table with no primary partition can also have secondary partitions. Secondary partition helps in parallelising the ingestion process. |
Number of Reducers | The number of reducers for the ingestion map reduce job. Increasing the number of reducers helps reduce the ingestion duration.<br>This will help in processing the MR jobs faster. This will be effective with the combination of partition key and number of secondary partitions. In any data processing using MR job, this will help in bringing the parallelism based on the data distribution across number of primary partitions and secondary partitions on Hadoop. |
Generate History-View | If this configuration is enabled, history view table will be created (along with the current view table) in Hive, which contains the versions of incremental updates and deletes. |
Number of Secondary Partitions to Merge in Parallel | It is a number that represents number of secondary partitions can be merged in parallel for a table. |
Number of Secondary Partitions to load in-memory for Merge | It is a number that represents number of parallel merge jobs that will be loaded in memory while the merge for previous set of secondary partitions are in progress during map side merge. |
Data Viewer - Superset
Superset is a visualization platform that allows you to query and create visual models from Hadoop data. Superset enables you to visualize the data stored in Hive after being ingested from source.
Following are the steps to query a superset:
NOTE: The configuration, ENABLE_DATAVIEWER, must be set to true to enable the data viewer.
In the Source Configuration page, click View for the required table record. The Data page is displayed with the data viewer.
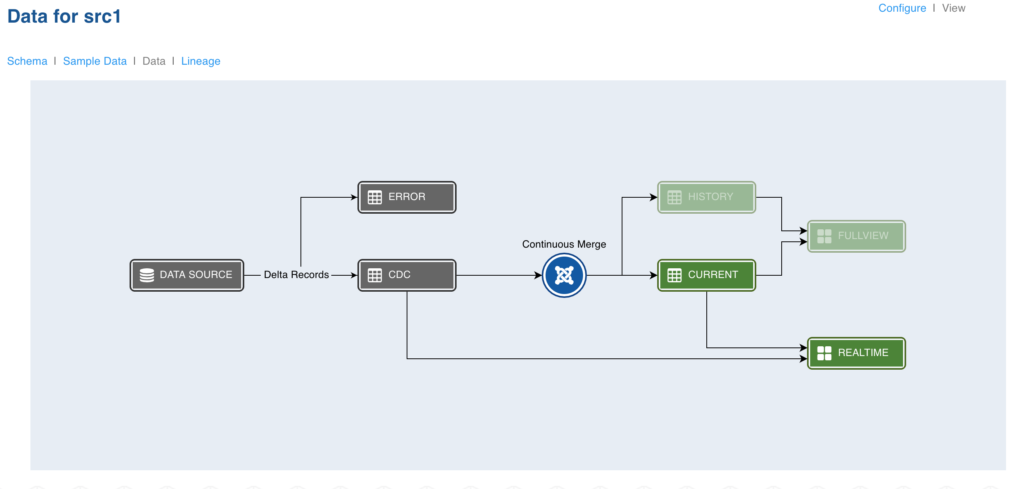
Click the required table to view the Apache superset. A new window with the Apache superset will be displayed as follows:
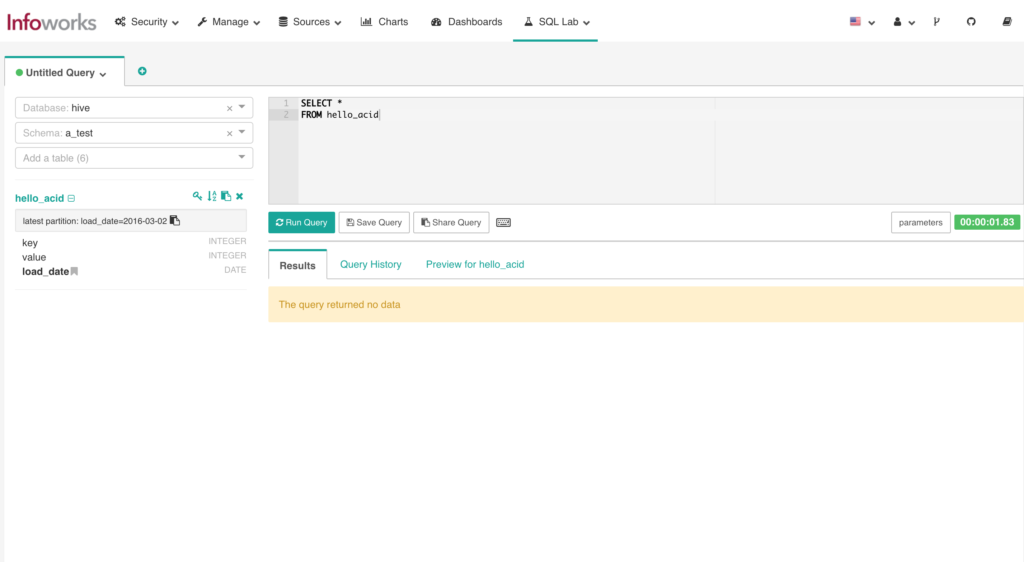
Run the queries to obtain the required data from the Hive tables.
Table Operations
Following are the steps to truncate, delete, recrawl and reorganize the table data:
In the Source Configuration page, click the Actions button for the required table.
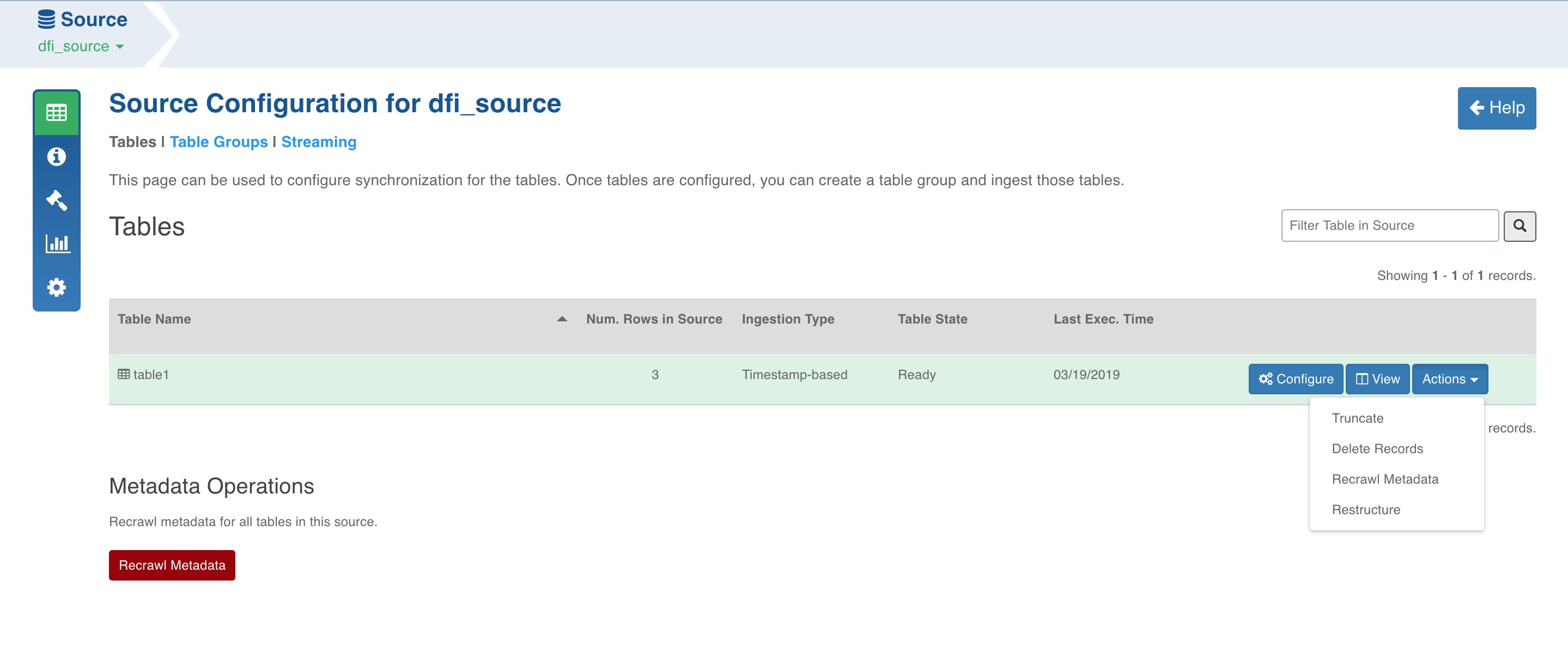
Perform either of the following:
Click Truncate to delete data from the target and reset the table metadata (row count and last ingested timestamp).
Click Delete Records and specify a select query. This query will run on the current Hive table corresponding to the DFI table and will delete all the result rows from the current Hive table. This option is disabled if natural key is not selected.
Click Recrawl Metadata to refresh the column list based on the schema from the source system.
NOTE: This option does not update the row count and last ingested time stamp on the table.
Click Restructure to reorganize the table data based on the configurations given for the job.
Click the Recrawl Metadata button in the Metadata Operations section to recrawl metadata for all the tables.
NOTE: This option does not update the row count and last ingested time stamp for the tables.
Click Fetch New Tables to crawl the new tables added to the source schema.