Infoworks creates the tables based on the input parameters and transfers the data to Teradata using Teradata Connector For Hadoop.
NOTE: Ensure Teradata Connector For Hadoop is installed. For details, see External Client Drivers.
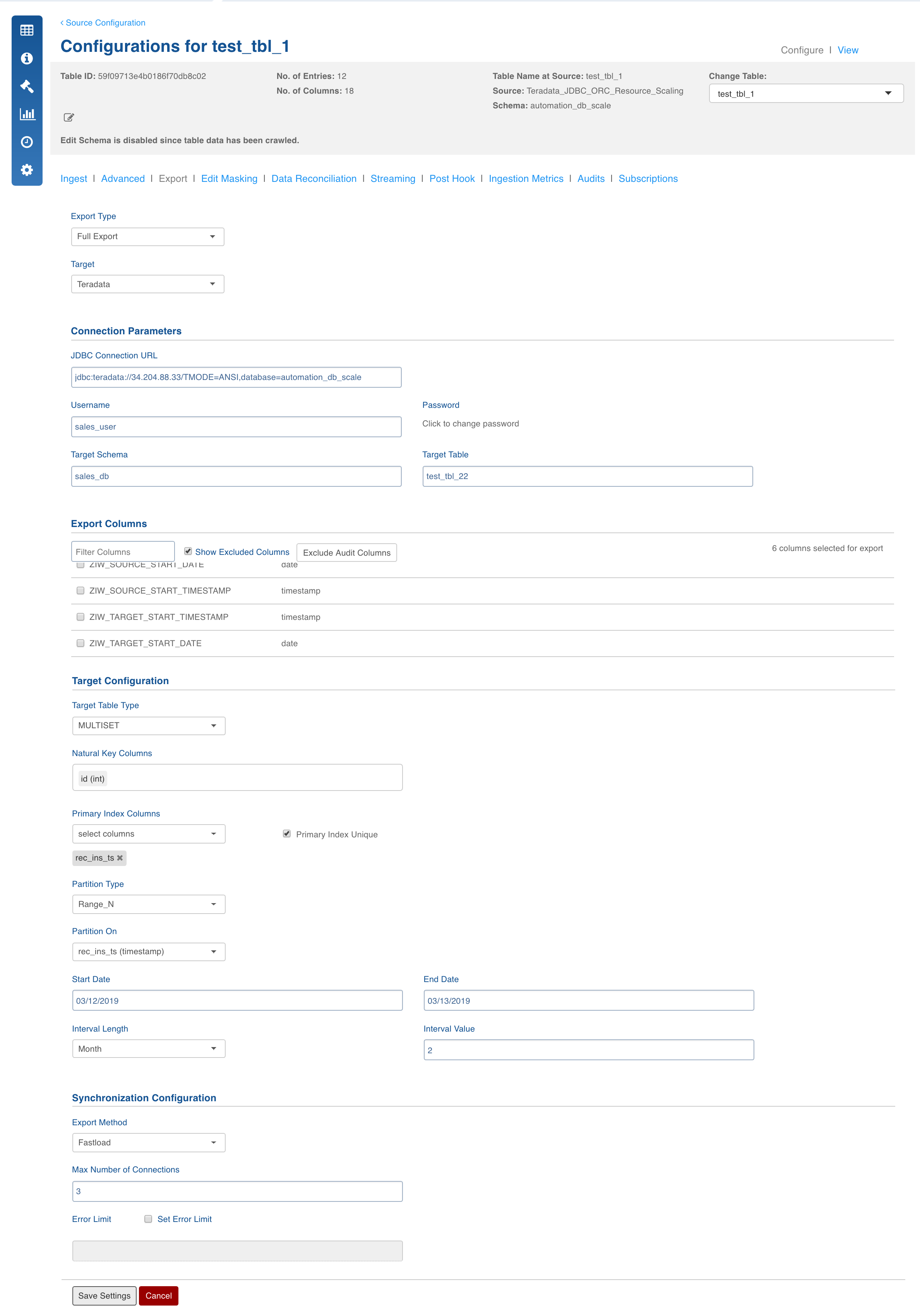
Field Description
Export Type: Select Full Export/Incremental Export into Teradata.
Target Database: The database type you want to export to (Teradata).
JDBC Connection URL: The connection URL needed to connect to the target database.
Username: Username of the target database.
Password: Password of the target database.
Target Schema: The schema in which you want the target table to be created.
Target Table: Name of the target table.
Export Columns: The selections of columns that must be exported to the target database. The user must select at least one column. User can use the Select all and Deselect All buttons to make the selection faster.
Target Table Type: Option of selecting a SET table or a MULTISET. SET tables does not allow duplicate values in the table, where as a MULTISET table allows duplicate values.
Natural Key Columns: Natural Key Columns are the columns that help determine a row uniquely. Primary Index and Partition Column must be a part of the Natural Key Columns for export to Teradata.
Primary Index: The primary Index of the target table to be created.
Partition Type: The two options are No_partition and Range_n.
No Partition: The target table would not be partitioned.
Range_n: The target table would be partitioned on Range_n partition type of Teradata. If this option is selected, more options will be displayed.
Partition On: The column that you want to partition on. This must be a Date column.
Start Date - The start date of the range_n condition.
End Date - The end date of the range_n condition.
Interval Length - A selection from Day, Month, Year.
Export Method: This includes the following two options:
FastLoad : This method initializes a fast load session on Teradata and all the mappers add data to it. This method should be selected by default.
Batch Insert: In this method, all the mappers write to Teradata using insert statements. This method should be used when there is binary data that you want to export.
Max Number Of Connections: The maximum number of connections that you want to allow to write to the target database.
Set Error Limit: If this checkbox is checked, you can specify an error limit.
Error Limit: The limit on the numbers of rows that go to error table, before the job fails.
Feature Scope and Known Issues
These datatypes in Hive are supported by the export feature: TINYINT, SMALLINT, INTEGER, BIGINT, TIMESTAMP, DATE, STRING, BOOLEAN, BINARY, CHAR, VARCHAR.
These datatypes in Hive are not supported by the export feature: UNION, ARRAY, STRUCT, MAP.
Currently, Incremental Export after the first export with zero rows in not supported. In such situation, please perform a full export once there is some data in the Hive table; post which, you can perform incremental exports.
Cancelling the Infoworks job will not automatically cancel the MapReduce job which exports data to Teradata.
Teradata export is not supported in GCP installations.
Best Practices
The export method should be Fastload by default. If there are binary columns in the table, use "Batch Insert".
The maximum number of mappers should not be set more than the number of AMPs in Teradata.
Natural Key should always be unique for the table.
Set an error limit to verify that the data has been transferred correctly.
Troubleshooting
Configurations
td_table_and_column_name_limit: The limit for the size of the name of table and columns in the target. Default value is 128.
shorten_td_export_destination_column_name: should the column names be shortened if it goes beyond the Teradata limit. Default value is false.
shorten_td_export_destination_table_name: should the table names be shortened if it goes beyond the Teradata limit. Default value is false.
teradata_export_multiplication_factor: The multiplication factor for varchar and blob columns to get the destination size of column in Teradata while doing a full export. Default value is, for example, 0.
export_yarn_queue: the configuration to specify the yarn queue used when exporting pipeline target tables to Teradata. The value must be a string.