Introduction
This section describes the step by step process for setting up Infoworks Service Recovery.
Pre-requisites
- Minimum of three node clusters (primary, secondary, and tertiary) must be setup.
- All nodes must be identical. They must have the same Infoworks DataFoundry user. Also, the Infoworks DataFoundry user must have the same privileges and must belong to the same group.
- Infoworks home directory must be created, and the Infoworks DataFoundry user must have write privileges on it across all the edge nodes.
- On the primary edge node, 2.8.0+ version of Infoworks DataFoundry must be installed.
Also, ensure to download the latest service scripts using following instructions:
cd $IW_HOME/binwget https://infoworks-resources.s3.amazonaws.com/service_recovery/service_recovery.tar.gztar -xvf service_recovery.tar.gzrm -rf service_recovery.tar.gz
NOTE: Use the env-check.sh script to validate all the prerequisites, using the following command:bash $IW_HOME/bin/environment-checker-ansible/env-check.sh
Service Recovery Set Up Procedure
Setting up Infoworks DataFoundry Service Recovery is a two-step process, described as follows:
Step 1: Configure services for recovery
This step includes copying required binaries, files, and configurations from primary node to secondary and tertiary nodes. This also includes preparing and configuring services for failover.
Step 2: Configure failover services during recovery phase
Infoworks DataFoundry installation or upgrade for versions greater than 2.8.0 supports the following services:
- UI
- Governor
- Hangman
- Rest API
- Query Service
- Data Transformation
- Cube Engine
- HA Service
- Monitoring Service
- Platform, which includes Platform Services, Notification User Consumer, and Notification Artifact Consumer.
- Configuration Service
- Postgres
- RabbitMQ Cluster
- Orchestrator, which includes Orchestrator Webserver, Orchestrator Engine Webserver, Orchestrator Engine Scheduler, and Orchestrator Engine Worker.
- Nginx
- MongoDB
- MongoDB Infoworks DB
- MongoDB Infoworks Collections
If node or services are down on primary, the failover process ensures to provide uninterrupted processing of the stopped services on the secondary node within minimal switch over period. There are three different kinds of failover mechanisms in Infoworks DataFoundry platform.
- Automated Failover: The failover is automated and requires no action from the user. This includes MongoDB, Platform Services, and RabbitMQ services.
- Master Slave Failover: The user must run a script to set up failover on the required edge node. This includes Postgres service.
- Manual Failover: The user must manually run a set of services to make them available on the secondary nodes. This includes UI, Governor, Hangman, Rest API, Query Service, Data Transformation, Cube-Engine, Monitoring Service, Configuration Service, and Orchestrator Services.
NOTE: After the failover, all the manual failover services must be running together on a single edge node. Also, the Postgres Master and Orchestrator services must be running together on the same edge node.
Follow the steps below to set up failover services:
- Execute FileSync Utility
- Set Up MongoDB Service Recovery
- Set Up Postgres RabbitMQ and Platform Service Recovery
Executing FileSync Utility
Following are the pre-requisites to execute filesync utility:
- IW_USER must be present on remote machines (secondary nodes).
- SSH_USER must have su permissions to IW_USER.
- Infoworks is setup on primary node.
- Infoworks Home directory is created and write permissions are provided for IW_USER on secondary nodes.
After setting up Infoworks on the primary node, you must copy the binaries, configuration files, and libraries on to secondary and tertiary nodes.
The FileSync Utility is used to keep all the servers in sync, for libraries, binaries, and configuration files.
Follow the steps below to setup FileSync Utility:
- Navigate to the /bin/infoworks-filesync-ansible folder.
- Run the following command: ./setup-iw-filesync.sh.
- Provide required inputs on prompt during script execution. The required files are automatically copied to remote hosts using the Infoworks tool.
- Ensure that there are no errors on console, or in the /bin/infoworks-filesync-ansible/ansible.log file.
Setting Up MongoDB Service Recovery
Following are the pre-requisites to set up MongoDB service recovery:
- IW_USER must be present on remote machines (secondary nodes).
- SSH_USER must be same as IW_USER.
- Any running instances of Mongo on the remote nodes must be stopped.
- Infoworks is setup on primary node.
- Infoworks Home directory is created, and write permissions are provided for IW_USER on secondary nodes.
- Secondary nodes are identical to the primary node (and are part of the same cluster).
Follow the steps below to set up MongoDB replication, which helps in the automated failover of MongoDB instances.
- Navigate to the /bin folder on the primary edge node.
- Run the command: ./mongo-ha-setup.sh, which performs following activities.
Now, perform the post-execution and validation steps as follows:
Pre-execution of Service Recovery Setup
- A backup of the conf.properties file will be created in the
<IW_HOME>/temp/conf.properties.YYYY-MM-DD-HH-MMfile. - All Infoworks and infrastructure services will be stopped.
- A tar file for the Mongo directory will be created in the /temp/-pre directory. (Optional)
- Prompt is displayed to enter the path to pem file, ssh user, and mongo port which defaults to 27017.
User Creation
- An oplogger user is created with read access to local database.
- An iw-ha admin user is created, if it does not exist.
Replica Set Creation
- A backup tar of Mongo directory will be created in the /temp/ directory.
- Prompt is displayed to enter the IPs/hostnames of the other two nodes.
- Backup tar is copied from the primary node to the secondary nodes, and MongoDB is started on the secondary nodes.
- When MongoDB is up and running on the remote nodes, replica set is initiated and remote nodes are added to the replica set.
Post-execution of Service Recovery Setup
- Post-execution step is optional.
- Remove the backup in the /temp/ folder.
Validation
- Step 1: On Primary node, Navigate to /bin and run the following commands: ./status.sh. MongoDB Replica will show the status of mongo servers running in the cluster.

On successful setup, the replica set will be online. Follow the steps below to view the replica set information:
- Navigate to the
<IW_HOME>/resources/mongodb/binfolder. - If you do not know the MongoDB password, go to the /conf/conf.properties file and find the encrypted Mongo password using the value of the metadbPassword parameter.
Execute the following command to find your MongoDB password : <IW_HOME>/apricot-meteor/infoworks_python/infoworks/bin/infoworks_security.sh -decrypt -p <MONGO PASSWORD>
- Execute the following command:
./mongo admin --host $host -u iw-ha -p $passwordwith relevant parameters, where $host is the primary node hostname or the IP address, and $password is the MongoDB password. - In the Mongo prompt, execute the following command:
rs.status(). This displays the replica set information. - Exit from the prompt using the exit command.
Note: If the MongoDB service recovery node is in unrecoverable state, perform the procedure mentioned in Resync Member of Replica Set.
- Step 2: Starting/Stopping/Monitoring Mongo Service Recovery
Ensure that the following files are available in <IW_HOME>/bin directory before setting up MongoDB service recovery.
NOTE: Ensure that the latest version of mongoha_start.sh and mongoha-start-stop.sh files are downloaded.
- mongo-ha-reset.sh – used to reset the Mongo HA node to non-SR(non-service recovery) node. The script does not impact the other remote machines.
- mongo-ha-setup.sh, mongoha_start.sh – used to setup the Mongo HA.
- mongo-ha-start-stop.sh – used to start/stop Mongo remotely from the edge node.
- Usage: mongo-ha-start-stop.sh {host} {stop/start}
- mongo_start.sh mongo_stop.sh – used to stop/start mongo locally. Available in the
<IW_HOME>/resources/mongodb/bindirectory. - status.sh – used to monitor the status of all Infoworks services including Mongo replica. Check for the MongoDB Replica parameter.
Setting Up Postgres, RabbitMQ, and Platform Service Recovery
Following are the pre-requisites for setting up Postgres, RabbitMQ, and Platform service recovery:
- IW_USER is present on remote machines (secondary nodes).
- Secondary nodes are identical to the primary node (part of the same cluster).
- SSH_USER has su permissions to IW_USER.
- Infoworks DataFoundry is setup on primary edge node and replication has occurred (Infoworks DataFoundry is present on all nodes).
- Write permissions for Infoworks Home directory are provided for IW_USER.
Perform the following steps to set up Postgres, RabbitMQ, and Platform services recovery, which helps in automated failover for these services:
Navigate to the /bin/infoworks-ha-ansible folder on primary node.
Run the following command: ./setup-iw-ha.sh, and enter required details as in the description that follows:
- Setup service recovery for RabbitMQ, Postgres and Platform services to true, as required.
- Enter the host details for the selected service recovery services.
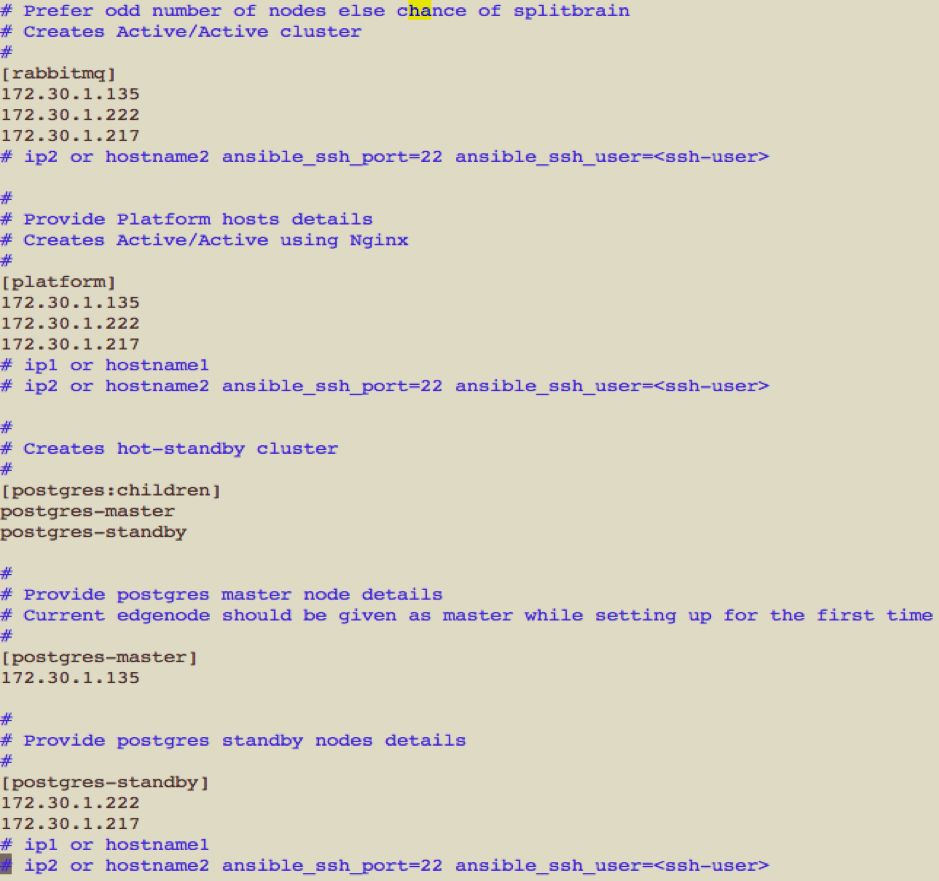
- Enter the ssh details for the hosts.
NOTE: For RabbitMQ and Platform, provide the host details in the order of priority from top to bottom. For Postgres service, under the [postgres-master] section in the host file, enter the primary node IP address and, under the [postgres-standby] section in the host file, enter the IP addresses of the secondary nodes.
All Infoworks services will be stopped.
- Enter the su password, if password is not set, press Enter.
Installation procedure starts. After successful installation, service recovery is setup for the selected services, and this starts the Infoworks services.
Infoworks Service Recovery Failover
MongoDB, RabbitMQ, Platform and Postgres services
On failure of MongoDB, RabbitMQ, and Platform services on primary edge node, the secondary edge node will be automatically promoted. This requires no action. For Postgres service recovery failover, follow the steps below:
Prerequisites
Ensure that the setup-iw-ha.shcommand has already been run in your system, and the following values are configured:
In the conf.properties file for all the nodes, ensure the following:
postgresha=ypostgres_host=<IP1,IP2,IP3>. For example,postgres_host=172.30.1.5,172.30.1.6,172.30.1.7postgres_port=<Postgres Port1,Postgres Port2,Postgres Port3>. For example,postgres_port=3008,3008,3008
In the primary node which runs as the Postgres master node, perform the following:
- Navigate to the
<IW_HOME>/binfolder. - Execute the following command:
./status.sh - Ensure that you get the following output: Postgres [master] RUNNING
In the secondary nodes which are run as Postgres standby, perform the following:
- Navigate to the
<IW_HOME>/binfolder. - Ensure that you get the following output: Postgres RUNNING
Procedure
Run the following steps in one of the cluster nodes:
- Navigate to the
<IW_HOME>/bin/infoworks-ha-ansiblefolder. - Run the following command:
./postgres-failover.sh - Validation: On successful completion, Postgres will run on the new master and service will be shown as
postgres [master]. Postgres will be stopped on other nodes, and new Postgres master will be the first IP address in the conf.properties file.
In the current master (promoted) node, setup the postgres service recovery again using the following steps.
- Navigate to the
<IW_HOME>/bin/infoworks-ha-ansiblefolder. - Run the following command:
./setup-iw-ha.sh - Setup service recovery only for Postgres, and make it false for RabbitMQ and Platform.
- Enter the host details for the selected service recovery services.
- Enter the ssh details for the hosts. The required files will be automatically copied to remote hosts using Infoworks tool. All Infoworks services will be stopped.
- Enter the su password. If password is not set, press Enter.
- Installation procedure starts.
NOTE: Ensure that while entering host details, the newly promoted master is given under [postgres-master] section, and the old master along with the arbiter node are given under the [postgres-standby] section. Also, ensure that while running workflows, orchestrator services run only on postgres master node.
Other Infoworks Services Manual Failover
The manual steps for failover can be used by executing commands when one of the following Infoworks services fails on the primary node, or during a node failure:
- User Interface
- Hangman
- Governor
- REST API
- Query Service
- Orchestrator
- Cube Engine
- Data Transformation
- Monitoring Service
- Configuration Service
Ensure that the following prerequisites are satisfied:
- IW_USER is present on remote machines (secondary nodes).
- The remote machine is identical to the existing edge node (must be part of the cluster).
- SSH_USER has su permissions to IW_USER.
- Infoworks Home directory is created and are identical on all nodes of the cluster.
- All Infoworks and Infra services are stopped on the secondary nodes.
Restart all Infoworks services.
- Stop all services on primary node by running the following command:
$IW_HOME/bin/stop.sh all orchestrator - Start all services on secondary node by running the following command:
$IW_HOME/bin/start.sh all orchestrator
Case 1: Primary Node is Down
Promote one of the secondary servers as primary, when the primary node is down. In case of node failovers, user must switch all the Infoworks services from primary to one of the secondary nodes. To promote secondary node as Postgres master, perform the following steps:
- Navigate to the
<IW_HOME>/bin/infoworks-ha-ansiblefolder. - Run the following command:
./postgres-failover.sh. This runs the Postgres in the standalone mode. - Enter the ssh details for the hosts. You must specify a working standby node as the master node in the hosts file.
- Enter the su password. If password is not set, press Enter.
To set up service recovery from the start, perform the following steps:
- Navigate to the
/bin/infoworks-ha-ansiblefolder. - Run the following command:
./setup-iw-ha.sh - Set up service recovery for Postgres, RabbitMQ and Platform services as True.
- Enter the host details for the service recovery.
- Enter the ssh details for the hosts.
- Enter the su password. If password is not set, press Enter. This initiates the installation procedure.
- In this case RabbitMQ and Platform service setups are optional. These are automatically failed over to the secondary nodes.
NOTE: Ensure that orchestrator services are running only on the Postgres master node. In case of node failovers, only the Infoworks services are taken care of with our service recovery steps. Any external applications using the primary’s IP must be handled manually by the user.
Case 2 : Primary Node and One Secondary Node are Down
In this scenario, Infoworks DataFoundry will not be functional. To make it functional, follow one of the following options in the order of preference:
Option 1: By bringing Infoworks on the primary node by performing the following steps:
- Start MongoDB using the following commands
source <path_to_Infoworks_home>/bin/env.sh
$IW_HOME/bin/start.sh mongo
- Start all services using the following command:
$IW_HOME/bin/start.sh all other orchestrator
Optionally, perform the following:
- When the secondary node which was down, is up and running, start MongoDB using the following commands:
source /bin/env.sh
$IW_HOME/bin/start.sh mongo
- Start Platform services, RabbitMQ, and Postgres using the following command:
$IW_HOME/bin/start.sh platform rabbitmq postgres - Bring back the secondary node with the Postgres master, by running Postgres service recovery setup on the current Postgres master node by following the description under the Set up service recovery from the start, perform the following steps topic under the Case 1: Primary Node is Down section.
Option 2: When the primary node cannot be recovered, perform the following steps:
- Start MongoDB on the other secondary node (Two MongoDB instances must be running across the edge node cluster), by using the following commands:
source <path_to_Infoworks_home>/bin/env.sh
$IW_HOME/bin/start.sh mongo
- Promote the currently running secondary node as a primary by following the instructions under the Case 1: Primary Node is Down section.
Option 3: When the primary and one secondary node cannot be recovered, perform the following steps:
- In this scenario, run Infoworks in a non-service recovery setup.
- Reset Mongo service recovery on the currently running secondary node using the following command:
$IW_HOME/bin/mongo-ha-reset.sh - Start all other services on the currently running secondary node using the following command:
$IW_HOME/bin/start.sh all orchestrator
Optionally, perform the following:
- When the other nodes are recovered again, setup service recovery as described in the Set Up MongoDB Service Recovery and Set Up Postgres RabbitMQ and Platform Service Recovery sections.
Case 3: All Nodes are Down
In this scenario, Infoworks will not be functional. To execute the preferred approach, perform the following steps:
- Start Mongo on the Postgres master using the following commands:
source <path_to_Infoworks_home>/bin/env.sh
$IW_HOME/bin/start.sh mongo
- Start Platform and all other services using the following command:
$IW_HOME/bin/start.sh all orchestrator - Reset mongo HA using the following command:
$IW_HOME/bin/mongo-ha-reset.sh - When the other nodes are recovered again, setup service recovery as described in the Set Up MongoDB Service Recovery and Set Up Postgres RabbitMQ and Platform Service Recovery sections.
Upgrading on Service Recovery Cluster
Constraints:
- Upgrade must take place in the current primary node only.
- No Infoworks jobs must be running on any of the nodes in the edge node cluster.
- Atleast two MongoDB instances other than the current upgrading node must be up and running. i.e., All the three MongoDB instances must up and running.
Perform the following steps for upgradation:
- Run the command:
source <path_to_infoworks_home>/bin/env.sh - Upgrade to latest Infoworks version on the primary server by using the following commands:
cd $IW_HOME/scripts (Ensure that if the scripts folder is not available (base versions below 2.7.0), you must create the scripts folder).
wget https://s3.amazonaws.com/infoworks-setup/2.8/update.sh -O update.sh
./update.sh -v 2.8.4-hdp-rhel7
- Download latest service recovery scripts on the primary server using the following commands:
cd $IW_HOME/bin
wget https://infoworks-resources.s3.amazonaws.com/service_recovery/service_recovery.tar.gz
tar -xf service_recovery.tar.gz
rm -rf service_recovery.tar.gz
- Set up file sync on the primary server using the following commands:
cd $IW_HOME/bin/infoworks-filesync-ansible/
./setup-iw-filesync.sh
- Set up Postgres service recovery on the primary server using the following commands. This must be the Postgres master after this step.
cd $IW_HOME/bin/infoworks-ha-ansible
./setup-iw-ha.sh
OS Patching Scenarios
Scenario 1: When OS patching planned on the primary node
Failover the Infoworks services onto one of the secondary nodes using the steps described in the Case 1: Primary Node is Down section. Continue with the patch. When the patch is completed on the primary node, perform the following steps:
- Start MongoDB using the following commands:
source <path_to_Infoworks_home>/bin/env.sh
$IW_HOME/bin/start.sh mongo
- Start Platform services, RabbitMQ, and Postgres using the following command:
$IW_HOME/bin/start.sh platform rabbitmq postgres - Bring back the primary node up to speed, with the postgres-master, by running Postgres service recovery setup on the current Postgres master node, by following the description under the To set up service recovery from the start, perform the following steps topic under the Case 1: Primary Node is Down section.
Scenario 2: When the OS patch is planned on one of the secondary nodes
Stop all the Infoworks services on that secondary node. Continue with the patch. When the patch is completed on the secondary node, perform the following steps:
- Start MongoDB using the following commands:
source <path_to_Infoworks_home>/bin/env.sh
$IW_HOME/bin/env.sh
- Start Platform services, RabbitMQ, and Postgres using the following command:
$IW_HOME/bin/start.sh platform rabbitmq postgres - Bring back the secondary node up to speed, with the postgres-master, by running Postgres service recovery setup on the current Postgres master node, by following the description under the To set up service recovery from the start, perform the following steps topic under the Case 1: Primary Node is Down section.