Infoworks supports ingestion of SalesForce data with CDC and merge support. Infoworks uses the SFDC Bulk API to obtain SalesForce data. This data is written into CSV files on HDFS which are in turn ingested into Infoworks using the existing structured file ingestion method.
Feature List
SalesForce ingestion supports the following features:
- Schema crawl
- Data crawl
- CDC and Merge
Creating Source
In the Admin section (Admin > Source > New Source), create a source and select the source type as Salesforce.com. Enter the Hive schema name and HDFS location.
Configuring Source
- Click the Sources menu and select the SalesForce source you created.
- In the Source Configuration page, click the Click here to enter them link.
- In the Settings page, perform the following:
- Enter the Salesforce environment (Production or sandbox), connection instance URL, username, password, secret key, fetch mechanism and API version.
NOTE: If the Fetch Mechanism selected is REST or Both, enter the Client ID and Client Secret Key.
- Click Save Settings.
Schema Crawl
- Click the Source Configuration icon. The following page is displayed.
- Click Crawl Metadata. A job will be started to obtain SalesForce tables and schema. The job will use the mappings specified in /{IW_HOME}/conf/mappings/sfdcMappigns to convert the data types from SalesForce to Hive.
Unsupported Datatypes Through BulkAPI: Datatypes in SalesForce like address, geometry, base64Binary, etc are not supported by BulkAPI. So, during metacrawl these columns are ignored and the remaining columns are obtained. You can specify the unsupported types through the SFDC_UNSUPPORTED_DATATYPES admin constant, the default value is address,geolocation,base64Binary.
- Refresh the page after some time to see the new tables.
Data Crawl Full Load
To enable schema synchronization, see the Enabling Schema Synchronization section.
Following are the steps to perform a full load data crawl:
- Click Sources on the main menu.
- Click the source that you created. The tables page is displayed with all the tables in that source.
- Click Configurations button for the table that requires a full load data crawl.
Enter the following values:
- Natural keys: Select the natural keys as required.
- Enable Schema Synchronization: Enable this checkbox to synchronize the columns added and deleted from Salesforce with the data lake. Synchronization is supported only for merge/append of tables that are crawled already.
NOTE: This feature is currently supported only for Salesforce REST API ingestion.
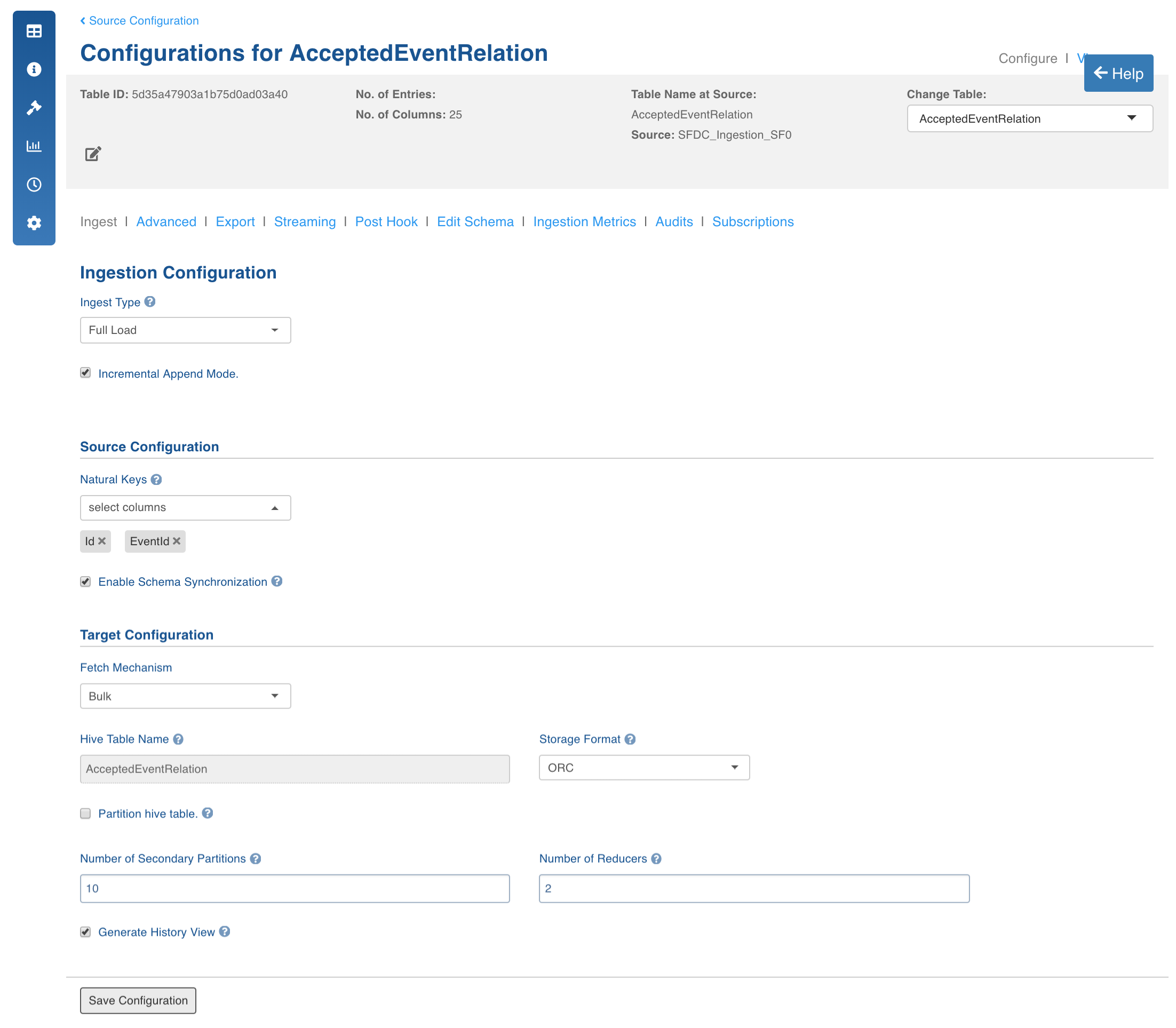
- Fetch Mechanism: Select the fetch mechanism as REST or Bulk.
- Bulk Connection Chunk Size: Infoworks uses SalesForce bulk connector to obtain data from SalesForce. If PK chunking is set to true, the bulk connector divides the SalesForce query into multiple batches or chunks based on the ID. This property specifies the max number of records in a particular batch or chunk.
- Bulk Max Retries: Infoworks waits for each batch to reach the completed state. This property specifies the maximum number of retries allowed in the bulk API for a batch to be completed before considering the job as failure.
- Batch Sleep Time: The sleep time between consecutive retries to obtain the status of batch.
- Number of Writer Threads: The number of threads to start to write salesforce data from bulk API into CSV.
- PK Chunking: Specifies whether PK chunking is to be enabled for the table.
Some tables in SalesForce do not support PK chunking. For more details, see SalesForce bulk API documentation.
- Select the storage format, secondary partitions and number of reducers as required. You can also select the checkbox to generate history view.
- Click Save Configuration.
- Click Table Group in the Table page.
- For first time ingestion or for a clean crawl, click Initialize and Ingest Now.
- To append new data to the crawled source, click Ingest Now from the second crawl onwards. Only the new and changed data will be picked.
Data Crawl Incremental Load
Following are the steps to perform an incremental load data crawl on SalesForce:
- Click Sources on the main menu.
- Click the source that you created. The tables page is displayed with all the tables in that source.
- Click Configurations icon for the table that requires an incremental load data crawl.
- In the Configuration page, enter the required values.
- Select timestamp-based incremental load and add timestamp column used for synchronization. By default, the SystemModTimestamp column will be selected.
- Fetch Mechanism: Select the fetch mechanism as REST or Bulk.
- Click Table Group in the Table page.
- For first time ingestion or for a clean crawl, click Initialize and Ingest Now.
- To append new data to the crawled source, click Ingest Now from the second crawl onwards, only the new and changed data will be picked.
Configurations
You can specify the salesforce to Infoworks mappings by editing the file located in the /opt/infoworks/mappings/sfdcMappings folder. The following configurations can be set at the table or source advanced configuration section. It can also be set at a global level in the configuration tab in the Admin section.
- CSV_KEEP_FILES: Set this value to true to retain the CSV files which are used for ingestion into Infoworks.
- CSV_PARSER_LIB: The underlying CSV parser library used by Infoworks. The default value is UNIVOCITY. It is recommended to use the default parser. In case of any issue, user can try setting COMMONS, JACKSON or OPENCSV parser. This configuration can be set at the source or table level.
- PARSE_DATE_AS_LOCALTIME: Set this value to true. Else, the CSV parser converts the CSV timestamp columns into the the system time zone.
Known Issues
- Setting the CSV_PARSER_LIB configuration to commons causes issues while parsing the CSV file for Salesforce.
- If the PARSE_DATE_AS_LOCALTIME configuration is not set to true, synchronization issues might occur. It is recommended to set this value to true at the global level to avoid adding in each source advanced configuration.
- Some tables in SalesForce do not support Bulk API and currently cannot be ingested to Infoworks. Also some tables do not support Primary Key chunking. So, the PK Chunking property must manually be set to false in their respective tables configurations. By default, the PK Chunking property is set to true.
- The following tables cannot be ingested using Infoworks due to the behaviour of Bulk API: AcceptedEventRelation, CaseStatus, ContractStatus, KnowledgeArticle, KnowledgeArticleVersion, KnowledgeArticleVersionHistory, KnowledgeArticleViewStat, KnowledgeArticleVoteStat, LeadStatus, OpportunityStage, PartnerRole, RecentlyViewed, SolutionStatus, TaskPriority, UserRecordAccess, ContentFolderItem, DeclinedEventRelation, EventWhoRelation, TaskStatus, TaskWhoRelation, UndecidedEventRelation
An exception in the below format will be displayed in the logs when an entity is not supported by Salesforce Bulk API:
Table AcceptedEventRelation failed. [AsyncApiException exceptionCode='InvalidEntity' exceptionMessage='Entity 'AcceptedEventRelation' is not supported by the Bulk API.' ]
- Some datatypes like address, geolocation, base64Binary, etc are not supported by the Salesforce BulkAPI.
Enabling Schema Synchronization
Perform the following to enable schema synchronization for Salesforce source via REST API:
- Create a Salesforce source.
- Perform the metadata crawl.
- Configure the table and check the Enable Schema Synchronization checkbox.
- Perform data crawl for the table.
NOTE: If a new column is added to the source table, during incremental ingestion, the specific column value will be set null in the existing tables. If a column is deleted from the source table, during incremental ingestion, the specific column value will be set null for the new tables.