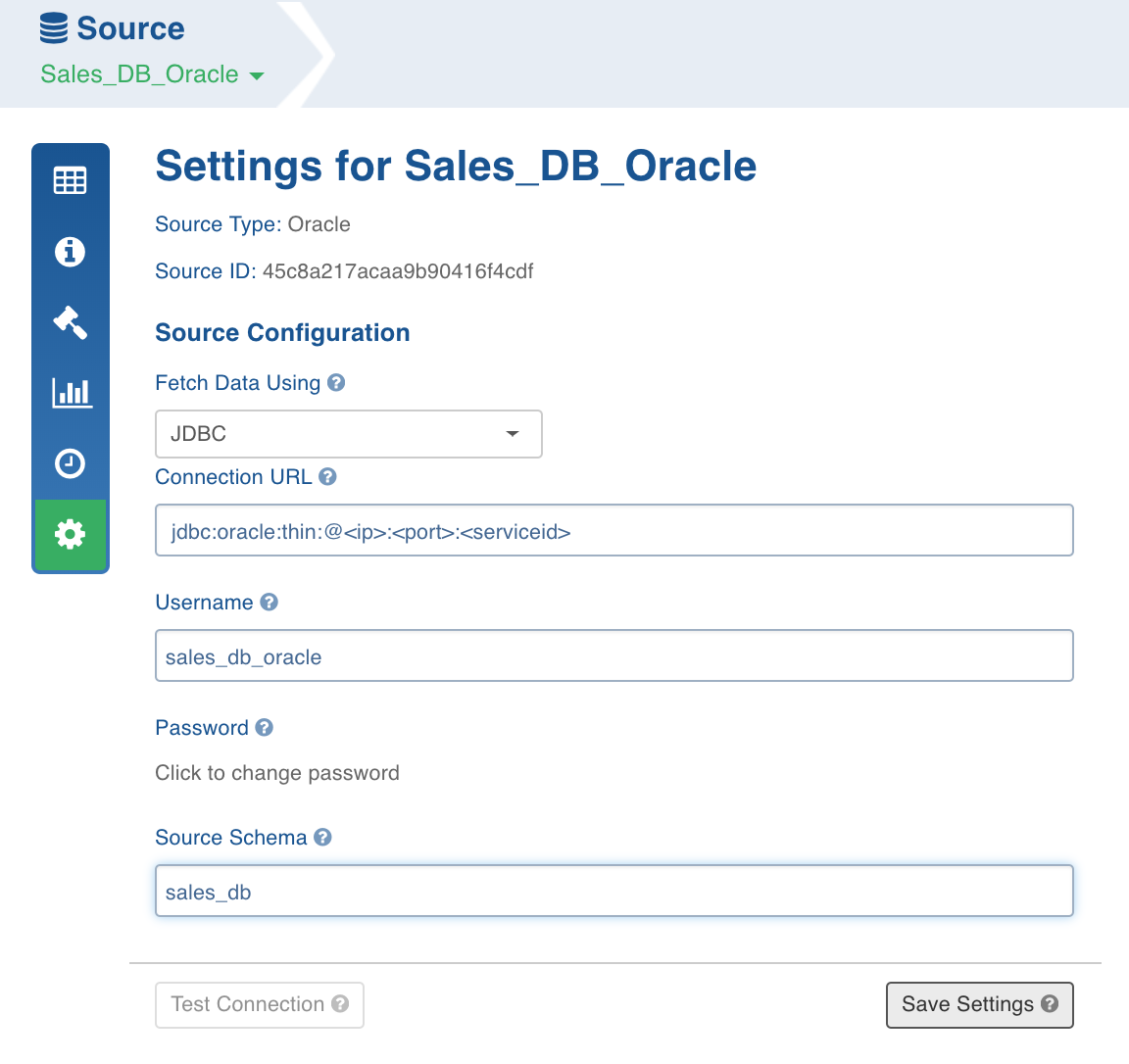
Configuring Source
- Click the Sources menu, click the required source.
- Click the Click here to enter them link or the Settings icon.
Enter the following source configuration details:
- Fetch Data Using: JDBC or TPT for Teradata, JDBC or BCP for SQL Server. For other RDBMS source types, only JDBC is enabled.
NOTE: In RDBMS ingestion using JDBC, the fetchsize parameter can be added as a constant at the table level. The value is an integer and the default size is 5000. This parameter is used to fetch the number of rows at once using JDBC, which improves the performance for large table ingestions.
- Connection URL: JDBC URL for the source.
- Username: Database user name.
- Password: Database password.
- Source Schema: Database schema to be crawled.
- Click the Test Connection option to verify the connection details entered.
NOTE: Click the Ingestion Logs icon to view the progress and logs of the test connection.
- Click Save Settings to save the table configuration in metadata storage.
Using TD Wallet for Teradata TPT Source
NOTE: Ensure that TD Wallet has been set up for the Infoworks user.
If the Source Type is Teradata and the Fetch Data Using is TPT, you can specify the Teradata Wallet Key, where the database password is stored.
For example, if the TD Wallet is set up and a key, TD_PASSWORD, is added with the database password as the value then, when configuring the source for TPT, you can select the Is Teradata wallet setup for Infoworks user? option and provide the key (TD_PASSWORD in this example) in the Key to retrieve Teradata Password from Wallet field to retrieve the password from the Teradata wallet.
RDBMS ingestion includes the following steps:
Metadata Crawl
This process crawls the schema of tables, views from source, and stores it on metadata store in the Infoworks platform.
Following are the steps to crawl metadata:
- Click the Sources menu and click the required RDBMS source.
- In the Source Configuration page, click the Crawl Metadata button.
NOTE: Click the Ingestion Logs icon to view the progress and logs of the metadata crawl.
- After the successful crawl, the Source Configuration page is displayed.
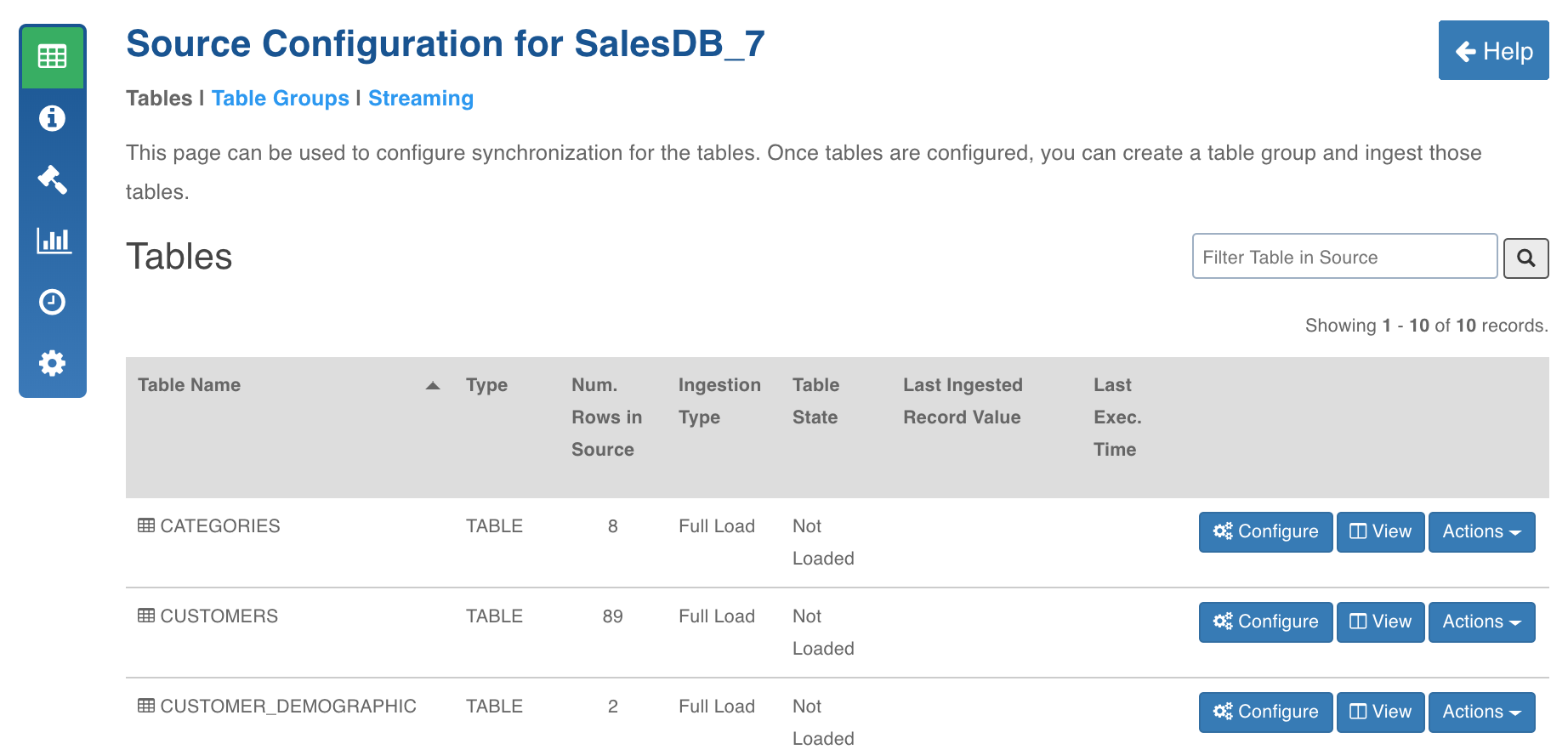
- Click the View button and click the Schema tab. The table metadata is displayed.
Edit Schema
You can also edit the target datatype of columns using the following steps:
- In the Source Configuration page, select the table to be ingested.
- Click the Edit Schema tab and edit the target data type for required columns. The Hive table will be created with the specified datatypes.
Following are the datatype conversions supported:
| Source Datatype | Target Datatype |
|---|---|
| String | Boolean, Integer, Float, Double, Long, Decimal, Date, Timestamp. Timestamp: yy-MM-dd hh:mm:ss |
| Boolean | String |
| Integer | Float, Double, Long, Decimal, String |
| Float | Double, Long, Decimal, String |
| Double | Float, Long, Decimal, String |
| Long | Float, Double, Decimal, String |
| Decimal | Integer, Float, Long, String |
| Date | String |
| Timestamp | String |
| Byte | String |
WARNING: The job might fail if any datatype conversion is not possible or if any error record is found.
- The Options field allows you to edit the precision and scale of the column. You can use the Bulk Edit option to edit the precision and scale of all the columns.
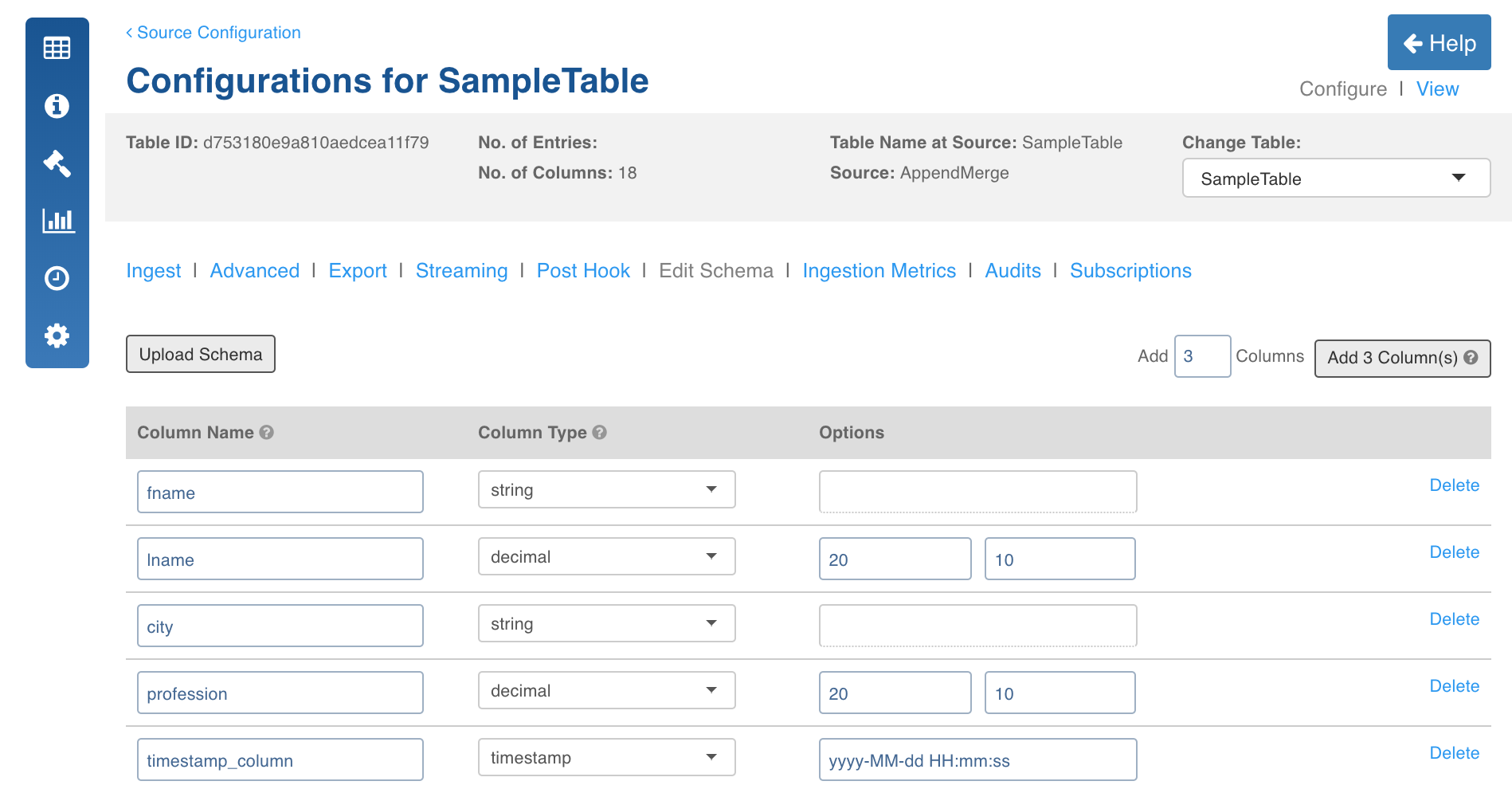
NOTE: The precision and scale values can be edited only for the Decimal datatype columns.
Limitation
Providing scale values greater than the precision values might cause issues.
Configurations
The following configurations must be used when performing metadata crawl for very large sources:
- crawl_connection_threshold (integer): The number of tables after which the connection will be re-established with source database system. The default value is 1000.
- METADATA_CRAWL_BATCH_SIZE (integer): The number of tables for which the metadata is stored in memory. The default value is 1000.
- enable_autofill_fk_relations (boolean): This option enables auto-filling of natural keys during metadata crawl, fetching of foreign keys and relations when set to true. The default value is false.
Data Ingestion
Following are the methods of data ingestion from source to Hadoop:
During data ingestion, the following set of Infoworks-specific audit columns will be appended to each record in the table:
Here,
- Type 1: SCD1 indicates no older version of the record is available.
- Type 3 indicates truncate reload.
| Audit Column | Type | Description |
|---|---|---|
| ZIW_SOURCE_START_DATE | Type 1: SCD1 | Date value retrieved from rec_add_ts for inserts. Date value retrieved from rec_upd_ts for updates. |
| Type 1:SCD 2 | Date value retrieved from rec_add_ts for inserts. | |
| Type 2:SCD 1 | Date value retrieved from rec_add_ts, which is stored in DWT_ABC.t_rec_hist table for inserts.Date value retrieved from rec_chg_ts, which is stored in DWT_ABC.t_rec_hist table for updates. | |
| Type2:SCD 2 | Date value retrieved from rec_add_ts for query based tables, which is stored in DWT_ABC.t_rec_hist table for inserts. | |
| Type 3 | Will be load date for truncate reload tables. | |
| ZIW_SOURCE_START_TIMESTAMP | Type 1: SCD1 | rec_add_ts for inserts. rec_upd_ts for all updates. |
| Type 1:SCD 2 | rec_add_ts for all inserts. | |
| Type 2:SCD 1 | rec_add_ts which is stored in DWT_ABC.t_rec_hist table for all insertsWill be rec_chg_ts,which is stored in DWT_ABC.t_rec_hist table for updates. | |
| Type2:SCD 2 | rec_add_ts, which is stored in DWT_ABC.t_rec_hist table for all inserts. | |
| Type 3 | Will be load timestamp for truncate reload tables. | |
| ZIW_TARGET_START_DATE | Type 1: SCD1 | Loading date of record onto Hadoop. If the load spreads across two dates, this will be updated with the date when the full load/ CDC started. |
| Type 1:SCD 2 | Loading date of record onto Hadoop. If the load spreads across two dates, this will be updated with the date when the full load/ CDC. | |
| Type 2:SCD 1 | Loading date of record onto Hadoop. If the load spreads across two dates, this will be updated with the date when the full load/ CDC started. | |
| Type2:SCD 2 | Loading date of record onto Hadoop. If the load spreads across two dates, this will be updated with the date when the full load/ CDC started. | |
| Type 3 | Loading date of record onto Hadoop. If the load spreads across two dates, this will be updated with the date when the full load/ CDC started. | |
| ZIW_TARGET_START_TIMESTAMP | Type 1: SCD1 | Load timestamp of record onto Hadoop. If the load spreads across multiple timestamps it should be the first date timestamp. |
| Type 1:SCD 2 | Load timestamp of record onto Hadoop. If the load spreads across multiple timestamps it should be the first date timestamp. | |
| Type 2:SCD 1 | Load timestamp of record onto Hadoop. If the load spreads across multiple timestamps it should be the first date timestamp. | |
| Type2:SCD 2 | Load timestamp of record onto Hadoop. If the load spreads across multiple timestamps it should be the first date timestamp. | |
| Type 3 | Load timestamp of record onto Hadoop. If the load spreads across multiple timestamps it should be the first date timestamp. | |
| ZIW_SOURCE_END_DATE | Type 1: SCD1 | Set to future date 2999-12-31 for all inserted records. Set to date retrieved from (recupdts-1 sec) for all updated records. |
| Type 1:SCD 2 | Set to future date 2999-12-31 for all inserted records. Expired records are updated with the date retrieved from new record version (rec_add_ts-1 sec) of DWT_ABC.T_REC_HIST table. | |
| Type 2:SCD 1 | Set to future date 2999-12-31 for all inserted records. Set to date retrieved from (rec_chg_ts-1 sec) for all updated records from DWT_ABC.t_rec_hist table. | |
| Type2:SCD 2 | Set to future date 2999-12-31 for all inserted records. Expired records are updated with the date retrieved from new record version (rec_add_ts-1 sec) of DWT_ABC.T_REC_HIST table. | |
| Type 3 | Set to future date 2999-12-31 for all inserted records. | |
| ZIW_SOURCE_END_TIMESTAMP | Type 1: SCD1 | Set to future date time 2999-12-31 23:59:59 for all inserted records. Set to (rec_upd_ts-1 sec) for all updated records. |
| Type 1:SCD 2 | Set to future date time 2999-12-31 23:59:59 for all inserted records. Expired records are updated with new record version (rec_add_ts-1 sec) of DWT_ABC.T_REC_HIST table. | |
| Type 2:SCD 1 | Set to future date time 2999-12-31 23:59:59 for all inserted records. Set to (rec_chg_ts-1 sec) for all updated records. | |
| Type2:SCD 2 | Set to future date time 2999-12-31 23:59:59 for all inserted records. Expired records are updated with new record version (rec_add_ts-1 sec) of DWT_ABC.T_REC_HIST table. | |
| Type 3 | Set to future date time 2999-12-31 23:59:59 for all inserted records. | |
| ZIW_TARGET_END_DATE | Type 1: SCD1 | Set to 2999-12-31 for all active records on Hadoop. |
| Type 1:SCD 2 | Set to 2999-12-31 for all active records on Hadoop. Set to the load date on Hadoop for the expired. | |
| Type 2:SCD 1 | Set to 2999-12-31 for all active records on Hadoop. | |
| Type2:SCD 2 | Set to 2999-12-31 for all active records on Hadoop. Set to the load date on Hadoop for the expired. | |
| Type 3 | Set to 2999-12-31 for all active records on Hadoop. | |
| ZIW_TARGET_END_TIMESTAMP | Type 1: SCD1 | Set to 2999-12-31 23:59:59 for all active records on Hadoop. Set to load timestamp for all expired records on Hadoop. |
| Type 1:SCD 2 | Set to 2999-12-31 23:59:59 for all active records on Hadoop. Set to load timestamp for all expired records on Hadoop. | |
| Type 2:SCD 1 | Set to 2999-12-31 23:59:59 for all active records on Hadoop. Set to load timestamp for all expired records on Hadoop. | |
| Type2:SCD 2 | Set to 2999-12-31 23:59:59 for all active records on Hadoop. Set to load timestamp for all expired records on Hadoop. | |
| Type 3 | Set to 2999-12-31 23:59:59 for all active records on Hadoop. | |
| ZIW_ACTIVE | Type 1: SCD1 | It is true for all records during full load. Will set to true for all incremental inserts during CDC. Will set to false for all updated records during CDC. |
| Type 1:SCD 2 | It is true for all records during full load. Will set to true for all incremental inserts during CDC. Will set to false for all updated records during CDC. | |
| Type 2:SCD 1 | It is true for all records during full load. Will set to true for all incremental inserts during CDC. Will set to false for all updated records during CDC. | |
| Type2:SCD 2 | It is true for all records during full load. Will set to true for all incremental inserts during CDC. Will set to false for all updated records during CDC. | |
| Type 3 | It is true for all records during full load. | |
| ZIW_IS_DELETE | Type 1: SCD1 | Set to true for all soft/hard delete records otherwise false. |
| Type 1:SCD 2 | Set to true for all soft/hard delete records otherwise false. | |
| Type 2:SCD 1 | Set to true for all soft/hard delete records otherwise false. | |
| Type2:SCD 2 | Set to true for all soft/hard delete records otherwise false. | |
| Type 3 | Set to false for all inserted records. | |
| ZIW_STATUS_FLAG | Type 1: SCD1 | This is set to I for all records during full load. This is set to I for all incremental inserts during CDC. Set to U for all incremental updates during CDC. Set to D for all hard deletes during CDC. |
| Type 1:SCD 2 | This is set to I for all records during full load. This is set to I for all incremental inserts during CDC. Set to U for all incremental updates/Expired records during CDC. Set to D for all hard deletes during CDC. | |
| Type 2:SCD 1 | This is set to I for all records during full load. This is set to I for all incremental inserts during CDC. Set to U for all incremental updates/Expired records during CDC. Set to D for all hard deletes during CDC. | |
| Type2:SCD 2 | This is set to I for all records during full load. This is set to I for all incremental inserts during CDC. Set to U for all incremental updates/Expired records during CDC. Set to D for all hard deletes during CDC. | |
| Type 3 | This is set to I for all records. | |
| ZIW_ROW_ID | Type 1: SCD1 | This is generated with natural key values for each record. |
| Type 1:SCD 2 | This is generated with natural key values for each record. | |
| Type 2:SCD 1 | This is generated with natural key values for each record. | |
| Type2:SCD 2 | This is generated with natural key values for each record. | |
| Type 3 | This is generated with natural key values for each record. |
Advanced Configuration for SQL Server BCP Source
Multilines are supported in string columns for SQL Server BCP source (Source Type - SQL Server and Fetch Data Using - BCP). If the source table includes string columns with line breaks, perform the following:
- Navigate to the source and click Configure on the required table.
- Click the Advanced tab and click Add Configuration.
- Set the key as ENABLE_QUOTENAME and value as true. The default value is false.
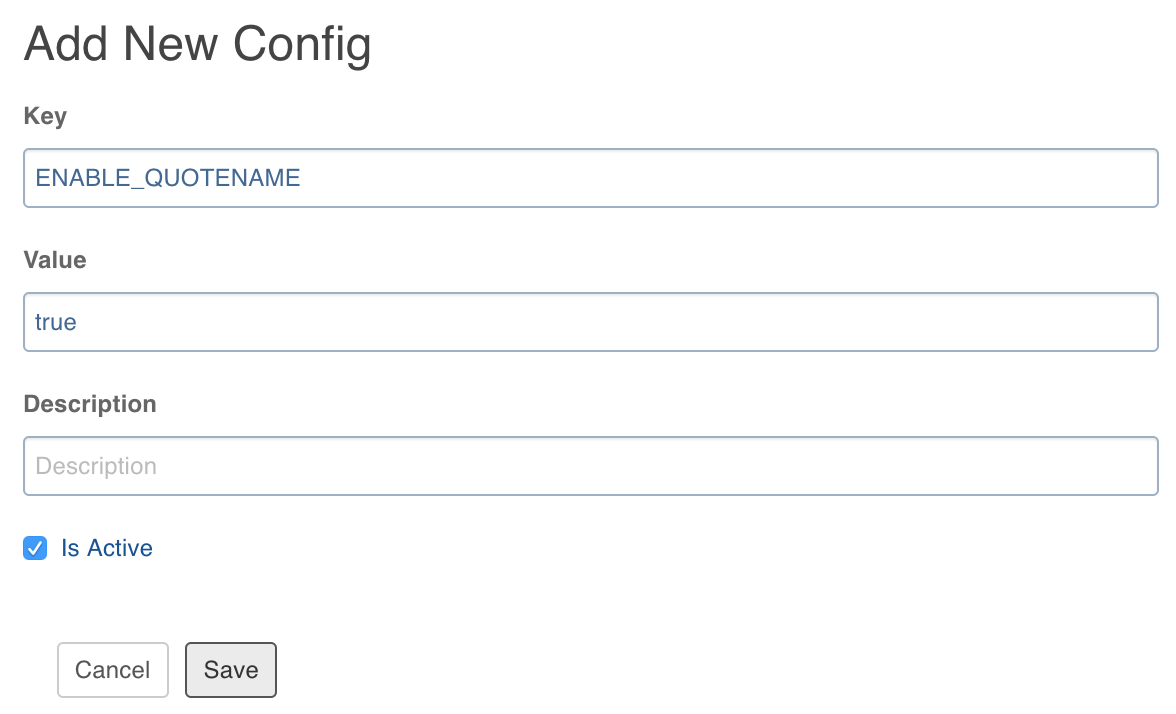
- Click Save.
SQL Server Windows Based Authentication
The SQL Server driver supports SQL Server AD login. For details on setting Microsoft drivers for SQL Server AD login, see Connecting using Azure Active Directory authentication.