The System Configuration page allows you to add/delete configurations and change the values and descriptions of configuration keys. The autocomplete feature allows you to select the required configuration from the drop-down list based on your input.
- Click the Admin menu and click the Configuration icon. The System Configuration page will be displayed.
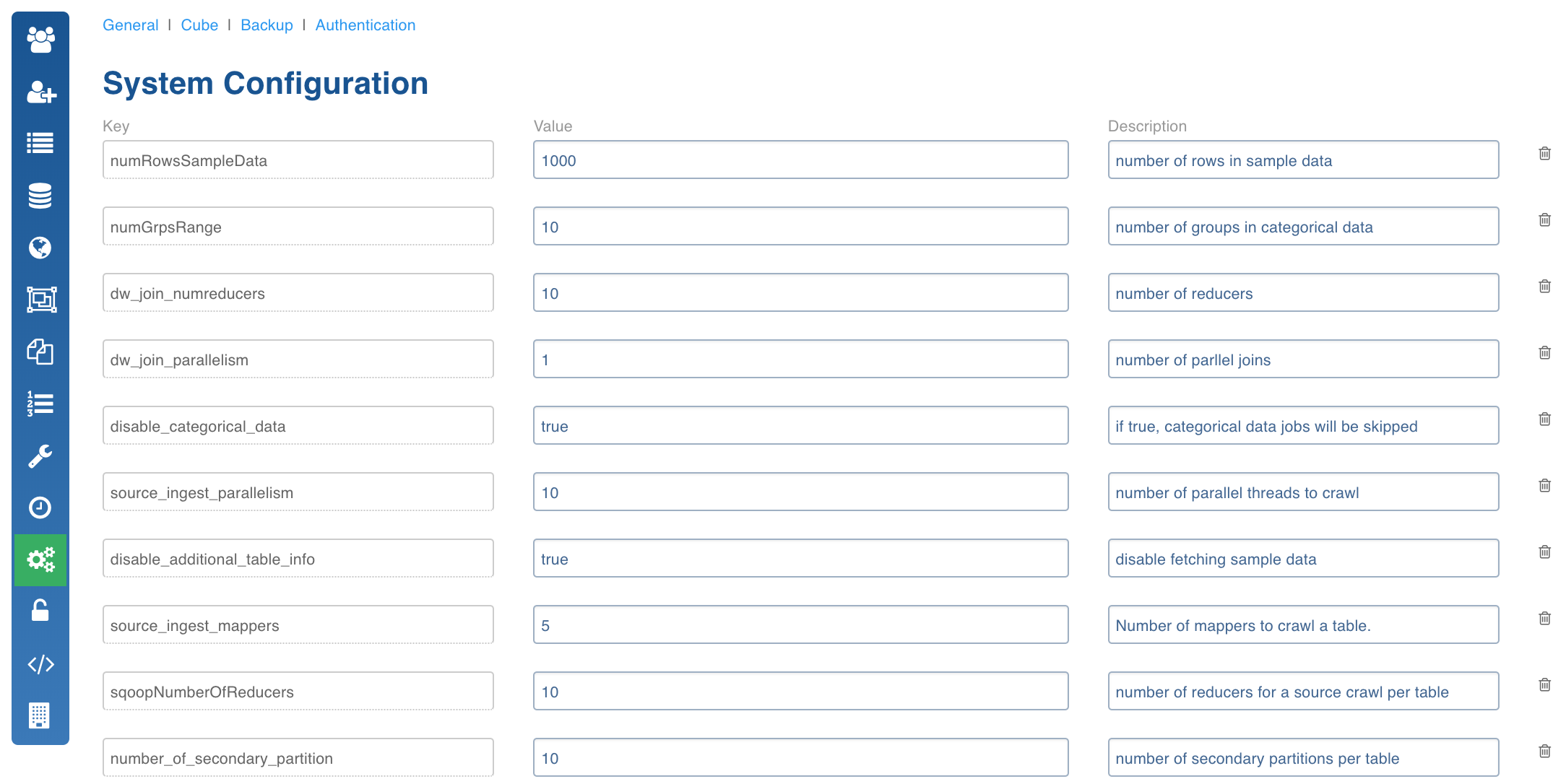
The following table lists all the configuration parameters and their descriptions.
System Configuration Keys and Descriptions
| Configuration Parameter | Description | Default Value |
|---|---|---|
| hiveConfigurationVariables | Extra parameters for the hive connection. Default when we ship must be 'hive.auto.convert.join=false; hive.insert.into.multilevel.dirs=true' | 'hive.auto.convert.join=falsehive.insert.into.multilevel.dirs=true' NOTE: Other values can be:hive.auto.convert.join=false;hive.insert.into.multilevel.dirs=true;hive.mapred.supports.subdirectories=true; mapred.input.dir.recursive=true; hive.optimize.insert.dest.volume=true; hive.exec.parallel=true; |
| numRowsSampleData | Number of rows to be retrieved as part of sample data. | 100 |
| numGrpsRange | Number of groups to be created while computing categorical data. | |
| dw_join_numreducers | Number of reducers for data warehouse join. | 10 |
| dw_join_parallelism | Number of parallel joins for data warehouse build. | 3 |
| disable_categorical_data | If true, categorical data computation will be skipped. | false |
| source_ingest_parallelism | Number of tables to crawl in parallel. | 2 |
| disable_additional_table_info | If true, fetching sample data and computing categorical data will be skipped. | false |
| source_ingest_mappers | Number of mappers to crawl a table. | 1 |
| sqoopNumberOfReducers | Number of reducers to crawl a table | 20 |
| number_of_secondary_partition | Number of secondary partitions in each primary partition | 2 |
| extract_row_limit | Number of rows to crawl from a table per mapper, -1 will do full table crawl without any limit. | 0 |
| END_DATE_STRING | Represents expiration date for each record on Hive. This is an IW audit column. | 9999-09-09 |
| END_TIMESTAMP_STRING | Represents expiration timestamp for each record on Hive. This is an IW audit column. | 9999-09-09 09:09:09 |
| disable_row_count | If true, metadata crawl will not fetch row count for source tables. | false |
| iw_job_timeout_secs | Job timeout in milliseconds for Infoworks MR jobs. | |
| iw_jobs_default_mr_map_mem_mb | Default map memory for Infoworks jobs. | |
| iw_jobs_default_mr_red_mem_mb | Default reducer memory for Infoworks jobs. | |
| fetch_size | In RDBMS ingestion using JDBC, this parameter can be added as a constant at the table level. This takes an integer (default size: 5000). This parameter is used to fetch at once, the number of rows using JDBC, which improves the performance for large table ingestions. | 5000 |
| cube_star_schema_job_map_mem_mb | Cube starschema job mapper memory. | |
| cube_star_schema_job_red_mem_mb | Cube starschema job reducer memory. | |
| max_number_of_chunks | Maximum number of chunks allowed while chunking a table. | 2000 |
| SKIP_RELOADED_CHUNKS | If true, already loaded chunks will be skipped during chunk loading. | true |
| enable_schema_synchronization | If true, table schema synchronization will be triggered before data synchronization. | false |
| db_time_zone | Database server time zone. | MST |
| NUM_PARALLEL_MERGE_TASKS | Number of parallel merge tasks while merging a table. | 1 |
| MERGE_CACHE_MB | Cache size for merging delta files. | 0 |
| source_crawl_cdc_mapmerge_mr_map_mem_mb | ||
| check_number_of_partitions | If false, checking available number of partitions during full load of a table will be disabled. | false |
| NUM_PARALLEL_MERGE_INMEM_LOADS | Number of parallel merge jobs that will be loaded in memory. | 1 |
| USE_COMBINE_INPUT_FORMAT | true | |
| source_crawl_cdc_mapmerge_mr_red_mem_mb | ||
| parallel_table_merge | Number of different tables merge that can happen in parallel. | 5 |
| num_parallel_jobs_per_entity | Number of jobs that can run in parallel per entity (source crawl, data warehouse build, cube build). | 2 |
| disable_row_count_for_hive | false | |
| recrawl_table_schema_on_table_truncate | If set to true, on table truncate, table schema will be re-crawled to get latest schema from source. | true |
| validate_chunks | If set to true, after every chunk load, data validation at chunk level will be triggered. | true |
| enable_job_logs_to_mongo | If set to true, job logs will go to file and mongo. | false |
| hive_conn_string_delimiter | Delimiter to use while forming Hive JDBC connection string. | ? |
| df_workspace_schema | Schema where Data Transformation stores all intermediate tables. | iw_df_workspace |
| df_workspace_base_path | HDFS path where Data Transformation stores data for all intermediate data. | /iw/df/workspace |
| df_shared_connection_enabled | Whether to reuse the connection for interactive mode. Typically true for Hive+Tez and false for Hive+MR. | true |
| df_shared_connection_timeout_ms | After how long should an idle shared connection be closed. Shared connection should be enabled. | 180000 |
| df_interactive_exec_pool_size | Thread pool size for executing tasks per request in the interactive mode. | 10 |
| df_interactive_table_maximum_size | Maximum size of any of the intermediate tables in interactive mode. | 10000 |
| df_batch_exec_pool_size | Thread pool size for executing tasks per request in the batch mode. | 5 |
| df_sampling_num_threads | Number of sampling tasks to run in parallel. | 5 |
| df_interactive_hive_settings | Semi-colon separated list of Entity level Hive configurations which includes the Hive configuration parameters that can be modified. | key1=value1 key2=value2 key3=value3 |
| df_batch_hive_settings | If the builds are slow, use this key to set or change Hive parameters at a pipeline level. These are semi-colon separated list of Entity level Hive configurations. | key1=value1 key2=value2 key3=value3 |
| df_compute_stats_enabled | When enabled, table-statistics are computated for merge or overwrite targets at the end of pipeline build job. | true |
| PIPELINE_SOURCES_AUTO_SYNC_CHECK_DISABLED | If set to true, it disables the error icon on the pipeline editor page indicating source schema mismatch. If set to false, the error icon displays on the pipeline editor page. | |
| random_sampling_enabled | Determines whether sample generation, for source or pipeline target, needs to be random. To be disabled when sampling is taking too long to complete or is failing. | true |
| CUBE_DIMENSIONS_ENABLE_DICTIONARY | If dimension tables need to be stored in memory. | true |
| sqoop_job_map_mem_mb | Mapper mem setting for sqoop. Might need to increase for tables with huge rows. | |
| sqoop_job_red_mem_mb | Reducer mem setting for sqoop. | |
| append_date_to_logfile | Append current date to IW job log file name. | true |
| LOGMINER_TABLESPACE_NAME | Table space name. | |
| use_new_tablespace | If we want to start logminer in different tablespace. | false |
| use_temp_table_for_log_based_cdc | To use temp table approach for log based cdc. | true |
| TEMP_DATABASE_NAME | Temp database name if we want to use temp database for log based cdc. | |
| build_dictionary_before_cdc | If we want to build database dictionary before every cdc for log-based cdc. | false |
| oracle_logminer_dictionary_file_name | Oracle dictionary file name. | dictionary.ora |
| oracle_logminer_dictionary_file_path | Path on oracle server to dictionary file. | |
| SOURCE_TIME_FORMAT | Time format of data for log-based cdc. | |
| SOURCE_DATE_FORMAT | Date format of data for log-based cdc. | |
| sqoop_export_job_map_mem_mb | Mapper mem setting for sqoop. Might need to increase for tables with huge rows. | |
| sqoop_export_job_red_mem_mb | Present export jobs have no reducer, so not necessary now. This configuration will be useful in future. | |
| export_multiplication_factor | Multiplication factor arrays for creation of target table. | 2.0,1.5,1.0 |
| shorten_td_export_destination_column_name | Specifies if the column names should be shortened while creating the destination table. | false |
| shorten_td_export_destination_table_name | Specifies if the table names should be shortened while creating the destination table. | false |
| td_table_and_column_name_limit | The limit for table name. | 128 |
| netezza_export_escape_char | The escape char for stging file in NZ export, only applicable for external tables. | / |
| netezza_export_enclose_char | The enclose char for stging file in NZ export, only applicable for external tables. Possible options are single quote and double quote. | " |
| netezza_export_null_value | The null value for stging file in NZ export, only applicable for external tables. | "" |
| netezza_export_should_allow_control_characters_in_data | Should control characters ASCII (0-31) be part of data. | false |
| fail_job_on_post_hook_failure | If the job should fail when post hook fails. | true |
| notification_mail_authentication_enabled | For the SMTP server, specifies if authentication is enabled. | true |
| notification_mail_tls_enabled | For the SMTP server, specifies if TLS is enabled. | true |
| default_driver_xmx_mb | Default driver memory setting for any Job without the job configurations | 512 |
| iw_jobs_default_mr_java_opts_ratio | Default ratio of container xmx to container memory | 0.8 |
| iw_jobs_default_mr_map_mem_mb | default map memory for infoworks jobs | 2048 |
| iw_jobs_default_mr_red_mem_mb | default reducer memory for infoworks jobs | 2048 |
| iw_jobs_default_mr_io_sort_ratio | Default ratio of MR Job io.sort.mb to minimum of mapper and reducer memories | 0.3 |
| source_fetch_metadata_rdbms_driver_xmx_mb | Driver Xmx memory for RDBMS Metadata crawl | |
| source_fetch_metadata_sftp_driver_xmx_mb | Driver Xmx memory for SFTP Metadata crawl | |
| source_crawl_rdbms_driver_xmx_mb | Driver Xmx memory for RDBMS and DFI Crawl | |
| source_crawl_sftp_driver_xmx_mb | Driver Xmx memory for SFTP Crawl | |
| source_cdc_driver_xmx_mb | Driver Xmx memory for CDC | |
| source_merge_driver_xmx_mb | Driver Xmx memory for Merge | |
| source_export_driver_xmx_mb | Driver Xmx memory for Export | |
| default_driver_xmx_mb | Driver Xmx memory for Sample Data Generation | |
| pipeline_build_driver_xmx_mb | Driver Xmx memory for DF batch build driver xmx | |
| cube_build_driver_xmx_mb | Driver Xmx memory for Cube build | |
| default_driver_xmx_mb | Driver Xmx memory for Delete entity | |
| source_crawl_cdc_mapmerge_mr_map_mem_mb | Mapper memory CDC | |
| source_crawl_cdc_mapmerge_mr_red_mem_mb | Reducer memory CDC | |
| dfi_job_map_mem | Mapper memory DFI crawl | |
| dfi_job_red_mem | Reducer memory DFI crawl | |
| json_job_map_mem | Mapper memory JSON crawl | |
| json_job_red_mem | Reducer memory JSON crawl | |
| cube_star_schema_job_map_mem_mb | Mapper memory Cube build | |
| cube_star_schema_job_red_mem_mb | Reducer memory Cube build | |
| sqoop_export_job_map_mem_mb | Mapper memory Sqoop Export Data | |
| sqoop_export_job_red_mem_mb | Reducer memory Sqoop Export Data | |
| td_export_mr_map_mem_mb | Mapper memory Teradata Export Data | |
| td_export_mr_red_mem_mb | Reducer memory Teradata Export Data | |
| ADVANCED_ANALYTICS_DISABLED | To disable advanced analytics node, this should be true. | false |
| XML_ERROR_THRESHHOLD | If the number of error records increases this threshold, the mr job will fail. | 100 |
| XML_KEEP_FILES | If the host type is local before the mr job runs, the xml files are copied to the tableId/xml directory. If this config is true, then the files are not deleted after the crawl. | true |
| xml_job_map_mem | Mapper memory for the crawl map reduce. | Value of iw_jobs_default_mr_map_mem_mb in conf.properties |
| xml_job_red_mem | Reducer memory for the crawl map reduce. | Value of iw_jobs_default_mr_red_mem_mb in conf.properties |
| CSV_ERROR_THRESHHOLD | If the number of error records increases this threshold, the mr job will fail. | 100 |
| CSV_KEEP_FILES | If the host type is local before the mr job runs, the csv files are copied to the tableId/csv directory. If this config is true, the files are not deleted after the crawl. | true |
| CSV_TYPE_DETECTION_ROW_COUNT | Number of rows to be read for type detection/metacrawl. | 100 |
| CSV_PARSER_LIB | The parser to be used for csv crawl. | Default COMMONS, recommended UNIVOCITY. |
| CSV_SPLIT_SIZE_MB | Split size to be used for mr for every file. | 128 |
| dfi_job_map_mem | Mapper memory for the crawl map reduce. | Value of iw_jobs_default_mr_map_mem_mb in conf.properties |
| dfi_job_red_mem | Reducer memory for the crawl map reduce. | Value of iw_jobs_default_mr_red_mem_mb in conf.properties |
| calc_file_level_ing_metrics | If this is set to true, the file level ingestion metrics are calculated at the end of the job. | true |
| modified_time_as_cksum | If this is true, the modified time is used to determine if the file has been changed or not. If it is set to false, the actual checksum is calculated. | false |
| delete_table_query_enabled | By default, Delete Query feature is available at the table level. Set IW Constant delete_table_query_enabled to false from UI to hide Delete Query feature. | true |
| Ufi_max_failure_percentage_per_table | The percentage of files for which the file ingestion is failed before the job is shown as failed. | 0.0 |
| fetch_null_timestamped_records | Records having NULL values will be fetched for timestamp based incremental tables during full ingestion if the value is true. | false |
| MAP_ORACLE_DATE_TO_TIMESTAMP | In earlier versions of Oracle, date can hold timestamps also. If the user wants to depict this into target as well, this constant must be set to true | false |
| DFI_DELETE_ORIGINAL_FILE_AFTER_DECOMPRESSION | After the file ingestion, the original file will be deleted if this constant is set to true. | False |
| MIN_ROWS_FOR_MERGEMR | Minimum number of rows in the current data in a secondary partition for the merge. If a secondary partition has number of rows less than this value, the merge jobs will be combined until they reach this threshold. | 1000000 |
| pipeline_interactivity_mode | This is a pipeline validation configuration, which when set to 'manual', removes automatic data type validation while saving node properties and enable a Validate option in the node properties page. If this value is set to 'auto', it automatically validates the node data. | |
| cdh_impala_support | Set to true if Impala support is required | |
| fail_ingestion_on_impala_cache_refresh_failure | Set to true if the ingestion job is to be failed in case Impala cache metadata is not refreshed. | |
| iw_hive_ssl_enabled | To Enable or Disable SSL on Hive | false |
| iw_hive_ssl_truststore_path | Path to Hive Trust Store File Location | |
| iw_hive_ssl_truststore_passwd | Encrypted Password for Trust Store | |
| bcp_crawl_separator | The field separator for bcp import/export | |
| bcp_row_delimiter | The row separator for bcp export | |
| filesystem_scheme | The hdfs path will be pre-populated with the value set in this configuration. The values can be: s3, s3a, s3n, adls, wasb, gs. | - |
| df_batch_sparkapp_settings | This configuration is set to overwrite spark configurations like executor memory, driver memory, etc during pipeline batch build. | |
| df_disable_sample_job | This configurations is set to disable sample jobs after pipeline build. | False |
| df_disable_cache_job | This configurations is set to disable cache jobs after pipeline build. | False |
| CREATE_DROP_TARGET_SCHEMA | Used to allow Infoworks to run create database and drop database commands. If this value is set to false, the create database and drop database commands will not be executed. | True |
| target_schema_permission | Used to enable or disable creation of database in pipelines. If this value is set to false, creation of database in pipelines will be disabled. | True |
| df_dynamic_hive_udf_enabled | Used to enable or disable UDFs on Hive for pipelines. If this value is set to false, UDFs on Hive for pipelines will be disabled. | True |
| number_of_parallel_jobs_per_entity | The number of jobs that can run in parallel for each entity. Entity refers to either of the following: Source, Datamodel, Cube. For example, if this value is set to 3, then a maximum of 3 source crawls or 3 data model builds or 3 cube builds can occur in parallel. | NA |
| max_number_of_connections | The maximum number of connections allowed between each table and the source, for example, RDBMS. | NA |
| df_auto_exclusion_enabled | Used to set pipeline target column projection optimization on all nodes. | True |
| df_merge_exec_pool_size | Number of concurrent tasks to run while performing merge on pipeline targets. | 5 |
| df_fail_on_null_or_empty_partition_value | Used to fail the pipeline jobs when partition values are Null or Empty. | False |
| iw_udfs_dir | Indicates the UDFs directory. | NA |
| iw_hdfs_prefix | Default HDFS access protocol prefix. | hdfs:// |
| df_hive_analyze_works | Used to enable analyze tables for Hive targets. | True |
| df_label_auto_cast_enabled | Used to enable Auto Cast mode for Advanced Analytics Model Label Column. | True |
| df_label_cast_type | Used to indicate the default value for Advanced Analytics Model Label Column. | Double |
| df_spark_master | Indicates the Spark master mode. | local |
| df_hive_logging_freq_ms | Used to poll for Hive logs and update on job logs. | 60000 |
| df_target_hdfs_cleanup | To retain data on HDFS when the pipeline is removed, set this false. | True |
| df_batch_spark_settings | Semi-colon separated list of Entity level Hive configurations. Applicable for batch mode pipeline build and to generate sample data in source. | key1=value1;key2=value2;key3=value3 |
| df_scd2_granularity | SCD2 record change granularity on timestamp can be Second,Minute,Hour,Day,Month,Year. This can be set using advance configuration to overwrite configuration for all targets at once. | second |
| df_custom_udfs_force_copy | Custom UDFs in pipelines are only copied to HDFS when changes are detected. This configuration is used to overwrite changes to custom UDFs. | False |
| df_disable_sample_job | Used to disable sample job for pipeline targets after pipeline build. | False |
| df_disable_cache_job | Used to disable cache job for pipeline targets after pipeline build . | False |
| df_spark_configfile | Spark configuration file path for Interactive mode Spark pipelines. | /etc/spark2/conf/spark-defaults.conf |
| df_spark_configfile_batch | Spark configuration file path for Batch mode Spark pipelines. | /etc/spark2/conf/spark-defaults.conf |
| df_batch_spark_coalesce_partitions | Spark coalesce configuration to create lesser files while writing to disk. | NA |
| df_disable_current_loader | Custom Transformations cannot be loaded from current class loader. To load Custom Transformation from current classloader, set this configuration to False. | True |
| df_overwrite_log_level | Log Level overwrite at pipeline level. For example, rootLogger=ERROR;io.infoworks=TRACE;infoworks=DEBUG;org.apache.spark=ERROR. | NA |
| df_dynamic_hive_udf_enabled | Used to disable Hive UDF from loading for every job or request when add jar permissions are disabled. Set this configuration to false when permissions are disabled. | True |
| df_validation_progress_percent | Used to set the validation process percent in pipeline batch jobs. | 10 |
| df_schemasync_progress_percent | Used to set the Schema Sync progress percent in pipeline batch jobs. | 10 |
| df_spark_merge_file_num | Spark configuration to merge files using Coalesce option on dataframe during merge process. | 1 |
| iw_df_ext_prefix | Pipeline extension prefix. | hdfs:// |
| storage_format | Used to set the default storage format value for pipeline target. | ORC |
| user_extensions_base_path | Pipeline extension base path. | NA |
| source_crawl_schema_merge_mr_map_mem_mb | Mapper memory for schema merge jobs. | NA |
| source_crawl_schema_merge_mr_red_mem_mb | Reducer memory for schema merge jobs. | NA |
| source_crawl_schema_mapmerge_mr_map_mem_mb | Mapper memory for map-only schema merge jobs. | NA |
| SUPPORT_RESERVED_KEYWORDS | Used to enable or disable support for reserved keywords. To enables Hive connection on HDP 3.1, this value must be set to false. | True |
| df_cutpoint_optimization_enabled | Enables caching when the value is set to true. | False |
| CSV_NULL_STRING | Used to set the NULL string. This configuration is available on table, source and global level. | NULL |
| logpath | Path to logfile for mongo | $IW_HOME/logs/mongod.log |
| logappend | - | true |
| fork | If set to true, fork and run in background | true |
| port | Mongo port | 27017 |
| dbpath | - | $IW_HOME/resources/mongodb/data |
| pidfilepath | Location of pidfile | $IW_HOME/resources/mongodb/mongod |
| bind_ip | If set to loopback address, local interface only. If not specified, listen on all interfaces | 0.0.0.0 |
| auth | Enable authentication for mongo when set | true |
| noauth | Disable authentication for mongo when set | true |
| wiredTigerCacheSizeGB | - | 4 |
| replSet | In replicated mongo databases, specify the replica set name | rs0 |
| oplogSize | Maximum size in megabytes for replication operation log | 128 |
| keyFile | Path to a key file storing authentication info for connections between replica set members | $IW_HOME/resources/mongodb/mongodb/ |
| NETEZZA_EXPORT_DELIMITER | The record delimiter in the temporary file while transferring (Only applicable for external tables mode). | |
| df_impala_incremental_stats_enabled | - | |
| max_connections | Determines the maximum number of concurrent connections to the database server. | 100 |
| listen_addresses | Specifies the TCP/IP address(es) on which the server is to listen for connections from application. It can be a comma-separated list of addresses(host names and/or numeric IP addresses). Use * to specify all available IP interfaces; 0.0.0.0 to specify all IPv4 addresses; localhost to specify only local TCP/IP “loopback” connections to be made; empty to specify that server does not listen on any IP interface | localhost |
| shared_buffers | Sets the amount of memory the database server uses for shared memory buffers. Min 128kB | 128MB |
| dynamic_shared_memory_type | Specifies the dynamic shared memory implementation that the server should use. First option supported by OS (posix, sysv, windows, mmap). Use none to disable dynamic shared memory. | |
| log_timezone | Sets the time zone used for timestamps written in the server log | UTC |
| datestyle | Sets the display format for date and time values, as well as the rules for interpreting ambiguous date input values. It contains two independent components- the output format specification (ISO, Postgres, SQL, or German) and the input/output specification for year/month/day ordering (DMY, MDY, or YMD) | 'iso, mdy' |
| timezone | Sets the time zone for displaying and interpreting time stamps | UTC |
| lc_messages | Sets the language in which messages are displayed. | en_US |
| lc_monetary | Sets the locale to use for formatting monetary amounts | en_US |
| lc_numeric | Sets the locale to use for formatting numbers | en_US |
| lc_time | Sets the locale to use for formatting dates and times | en_US |
| default_text_search_config | Default configuration for text search | pg_catalog.english |
| wal_level | Determines how much information is written to the WAL | minimal |
| archive_mode | Enables archiving. When archive_mode is enabled, completed WAL segments are sent to archive storage by setting archive command | off |
| archive_command | Command to use to archive a logfile segment. Placeholders: %p = path of file to archive. %f = file name only. (e.g. 'test ! -f /mnt/server/archivedir/%f cp %p /mnt/server/archivedir/%f') | |
| max_wal_senders | Specifies the maximum number of concurrent connections from standby servers or streaming base backup clients. Set this on the master and on any standby that will send replication data. Must be less than max_connections | 0 |
| data_directory | This config allows use of data in another directory | ConfigDir |
| hba_file | This config specifies the file location for the host-based authentication configuration | ConfigDir/pg_hba.conf |
| ident_file | - | ConfigDir/pg_ident.conf |
| external_pid_file | This config specifies the file location extra PID file. If external_pid file is not explicitly set, no extra PID file is written | |
| minConnections | This config controls number of connections on postgres. If less number of workflows are executing at the same time increase its value | 100 |
| superuser_reserved_connections | - | 3 |
| unix_socket_directories | Comma separated list of directories | /tmp |
| unix_socket_group | Restart postgres and orchestrator services | |
| unix_socket_permissions | Begin with 0 to use octal notation | 0777 |
| bonjour | Set this configuration to 'on' to advertise server via Bonjour | off |
| bonjour_name | - | computer_name |
| authentication_timeout | - | 1min |
| ssl | - | off |
| ssl_ciphers | Allowed SSL ciphers | HIGH:MEDIUM:+3DES:!aNULL |
| ssl_prefer_server_ciphers | - | on |
| ssl_ecdh_curve | - | prime256v1 |
| ssl_cert_file | - | server.crt |
| ssl_key_file | - | server.key |
| ssl_ca_file | - | |
| ssl_crl_file | - | |
| password_encryption | - | on |
| db_user_namespace | - | off |
| row_security | - | on |
| krb_server_keyfile | - | off |
| krb_caseins_users | - | off |
| tcp_keepalives_idle | TCP_KEEPIDLE (in seconds) - The time the connection needs to remain idle before TCP starts sending keepalive probes. 0 selects the system default | 0 |
| tcp_keepalives_interval | TCP_KEEPINTVL (in seconds) - The time between individual keepalive probes. 0 selects the system default | 0 |
| tcp_keepalives_count | TCP_KEEPCNT (in seconds) - The maximum number of keepalive probes TCP should send before dropping the connection. 0 selects the system default | 0 |
| shared_buffers | Min 128kB | 128MB |
| huge_pages | - | try |
| temp_buffers | Min 800kB | 8MB |
| SQOOPLIMIT | - | |
| FETCHSIZE | - | |
| ORACLE_LOGMINER_DICTIONARY_FILE_PATH | - | |
| ORACLE_ARCHIVE_LOG_PATH | The absolute path to directory where archive logs are stored. | |
| ORACLE_LOGMINER_DICTIONARY_FILE_NAME | - | |
| BUILD_DICTIONARY_BEFOR_CDC | Setting the value to true builds a dictionary before every CDC. | false |
| INCLUDE_CURRENT_LOG | - | |
| DATABASE_OBJECT_TYPES | - | |
| TEMP_LOG_TABLE_NAME | - | |
| LOGMINER_TEMP_TABLE_TABLESPACE_NAME | - | |
| CREATE_TEMP_TABLE_PARALLELISM | - | |
| TEMP_DATABASE_NAME | - | |
| TEMP_TABLE_INDEX_NAME | - | |
| CREATE_INDEX_ON_TEMP_TABLE | - | |
| USE_NEW_TABLESPACE_FOR_LOGMINER | - | |
| USE_REDO_LOG_DICTIONARY | Setting the value to true uses redo log dictionary to read archive logs with DDL tracking. The value must be set to true in case of schema synchronization. | False |
| FETCH_NULL_TIMESTAMPED_RECORDS | - | |
| ORACLE_ARCHIVE_LOG_INFO_OBJECT_NAME | - | |
| ENABLE_DDL_TRACKING | - | |
| IS_STAGING_ORACLE_SERVER | - | |
| DROP_HIVE_SCHEMA | - | |
| DISABLECATEGORICAL | - | |
| DISABLEADDITIONALTABLEINFO | - | |
| DISABLEROWCOUNT | - | |
| TPT_SCRIPT_PATH | - | |
| TPT_CHECKPOINTS_PATH | - | |
| TPT_LOG_PATH | - | |
| TPT_CHARACTERSET | - | |
| SOURCE_DATE_FORMAT | - | |
| SOURCE_TIME_FORMAT | - | |
| SFTP_BUFFER_SIZE | - | |
| GZIP_FILE_EXTENSION | - | |
| ENCODE_PRIMARY_PARTITION | - | |
| UFI_INGEST_HIDDEN_FILES | - | |
| UFI_MAX_FAILURE_PERCENTAGE_PER_TABLE | - | |
| XML_INPUT_FILE_ENCODING | - | |
| FIXED_WIDTH_INPUT_FILE_ENCODING | - | |
| FIXED_WIDTH_RECORD_SEPARATOR | - | |
| FIXED_WIDTH_PADDING_CHARACTER | - | |
| FIXED_WIDTH_PARSER_LIB | - | |
| MAX_FIXED_WIDTH_RECORD_SIZE | - | |
| FIXED_WIDTH_ERROR_THRESHHOLD | If the number of error records increases this threshold, the MR job fails. | 100 |
| FIXED_WIDTH_KEEP_FILES | If the host type is local before the MR job runs, the csv files are copied to the tableId/CSV directory. If this config is true, then the files are not deleted after the crawl. | True |
| FIXED_WIDTH_COMMENT_START_CHARACTER | - | |
| FIXED_WIDTH_SKIP_CHARACTERS_UNTIL_NEW_LINE | - | |
| FIXED_WIDTH_ROW_ENDS_WITH_NEW_LINE | - | |
| FIXED_WIDTH_TYPE_DETECTION_ROW_COUNT | - | |
| CDC_START_TIMESTAMP | - | |
| CDC_END_TIMESTAMP | - | |
| LOG_BASED_CDC_SPLIT_BY_COLUMN | - | |
| IS_WIDE_TABLE | - | |
| VALIDATECHUNKS | - | |
| FAILCHUNKWHENCOUNTDOESNTMATCH | - | |
| CSV_INPUT_FILE_ENCODING | - | |
| JSON_INPUT_FILE_ENCODING | - | |
| JSON_ERROR_THRESHHOLD | If the number of error records increases this threshold, the MR job fails. | 100 |
| JSON_KEEP_FILES | If the host type is local before the MR job runs, the CSV files are copied to the tableId/CSV directory. If this value is true, the files are not deleted after the crawl. | True |
| JSON_TYPE_DETECTION_ROW_COUNT | Number of rows to be read for type detection/metacrawl. | 100 |
| CONTROL_FILE_READER | - | |
| VALIDATE_AFTER_SFTP_TO_LOCAL | - | |
| VALIDATE_AFTER_LOCAL_TO_HDFS | - | |
| SEC_PARTITION_MERGE_RED | - | |
| VALIDATE_AFTER_HDFS_TO_HIVE | - | |
| CSV_MULTILINE_MODE | - | |
| TPT_DELIMITER | - | |
| TPT_FILE_ESCAPE_CHAR | - | |
| TPT_FILE_QUOTE_ESCAPE_CHAR | - | |
| TPT_FILE_ENCLOSE_CHAR | - | |
| TPT_EXPORT_SPOOL_MODE | - | |
| TPT_JOB_RESTART_LIMIT | - | |
| TPT_CHECKPOINT_INTERVAL_IN_SECONDS | - | |
| TPT_EXPORT_BLOCK_SIZE | - | |
| TPT_EXPORT_TENACITY_HOURS | - | |
| TPT_EXPORT_RETRY_INTERVAL_MINS | - | |
| TPT_IO_BUFFER_SIZE | - | |
| TPT_HADOOP_BLOCK_SIZE | - | |
| TPT_EXPORT_MAX_SESSIONS | - | |
| TPT_EXPORT_MIN_SESSIONS | - | |
| TPT_EXPORT_OPERATOR_MAX_DECIMALDIGITS | - | |
| TPT_EXPORT_READER_INSTANCES | - | |
| TPT_EXPORT_WRITER_INSTANCES | - | |
| TPT_UNICODE_MULTIPLICATION_FACTOR | - | |
| TPT_ASCII_MULTIPLICATION_FACTOR | - | |
| TPT_UTF8_MULTIPLICATION_FACTOR | - | |
| TPT_UTF16_MULTIPLICATION_FACTOR | - | |
| USE_TPT_SELECTOR_OPERATOR | - | |
| USE_TPT_GENERATED_SCHEMA | - | |
| ENABLE_TPT_TRACE_LEVEL | - | |
| USE_TPT_DESTINATION_AS_HDFS | - | |
| USE_TPT_TDCH_INTERFACE | - | |
| TPT_FILE_FORMAT | - | |
| SFTP_STAGING_BASE_PATH | - |
Admin Configurations Moved from Global to Entity Levels
The following table lists the admin configurations that are moved from global to entity levels:
| IWConstant | Current Level | Moved to |
|---|---|---|
| UFI_INGEST_HIDDEN_FILES | Global | Table |
| UFI_MAX_FAILURE_PERCENTAGE_PER_TABLE | Global | Table |
| EXPORT_PARALLELIZATION_FACTOR | Global | Global |
| XML_INPUT_FILE_ENCODING | Global | Table |
| XML_ERROR_THRESHHOLD | Global | Table |
| XML_KEEP_FILES | Global | Table |
| FIXED_WIDTH_INPUT_FILE_ENCODING | Global | Table |
| FIXED_WIDTH_RECORD_SEPARATOR | Global | Table |
| FIXED_WIDTH_PADDING_CHARACTER | Global | Table |
| FIXED_WIDTH_PARSER_LIB | Global | Table |
| MAX_FIXED_WIDTH_RECORD_SIZE | Global | Table |
| FIXED_WIDTH_THRESHHOLD | Global | Table |
| FIXED_WIDTH_KEEP_FILES | Global | Table |
| FIXED_WIDTH_COMMENT_START_CHARACTER | Global | Table |
| FIXED_WIDTH_SKIP_CHARACTERS_UNTIL_NEW_LINE | Global | Table |
| FIXED_WIDTH_ROW_ENDS_WITH_NEW_LINE | Global | Table |
| FIXED_WIDTH_TYPE_DETECTION_ROW_COUNT | Global | Table |
| sqoopLimit | Source | |
| fetchSize | Source | |
| CDC_START_TIMESTAMP | Table | |
| CDC_END_TIMESTAMP | Table | |
| LOG_BASED_CDC_SPLIT_BY_COLUMN | Table | |
| ORACLE_LOGMINER_DICTIONARY_FILE_PATH | Source | |
| ORACLE_ARCHIVE_LOG_PATH | Source | |
| ORACLE_LOGMINER_DICTIONARY_FILE_NAME | Source | |
| BUILD_DICTIONARY_BEFOR_CDC | Source | |
| TABLE_SCHEMA_FULL_REFRESH | Global | |
| ORACLE_DATE_FUNCTIONS | Global | Global |
| INCLUDE_CURRENT_LOG | Global | Source |
| DATABASE_OBJECT_TYPES | Global | Source |
| TEMP_LOG_TABLE_NAME | Source | Source |
| LOGMINER_TABLESPACE_NAME | Source | |
| LOGMINER_TEMP_TABLE_TABLESPACE_NAME | Source | |
| CREATE_TEMP_TABLE_PARALLELISM | Source | |
| TEMP_DATABASE_NAME | Source | Source |
| TEMP_TABLE_INDEX_NAME | Source | |
| CREATE_INDEX_ON_TEMP_TABLE | Source | |
| USE_TEMP_TABLE_FOR_LOG_BASED_CDC | Source | Source |
| USE_NEW_TABLESPACE_FOR_LOGMINER | Source | |
| IS_WIDE_TABLE | Global | Table |
| USE_REDO_LOG_DICTIONARY | Source | Source |
| MAP_ORACLE_DATE_TO_TIMESTAMP | Source | Source |
| FETCH_NULL_TIMESTAMPED_RECORDS | Source | |
| ORACLE_ARCHIVE_LOG_INFO_OBJECT_NAME | Source | Source |
| ENABLE_DDL_TRACKING | Source | |
| IS_STAGING_ORACLE_SERVER | Source | Source |
| DROP_HIVE_SCHEMA | Global | Source |
| disableCategorical | Global | Source |
| disableAdditionalTableInfo | Global | Source |
| disableRowCount | Global | Source |
| SKIP_RELOADED_CHUNKS | Table | Table |
| enable_schema_synchronization | Table | Table |
| validateChunks | Admin | Table |
| failChunkWhenCountDoesntMatch | Table | Table |
| CSV_PARSER_LIB | Admin | Table |
| CSV_SPLIT_SIZE_MB | Admin | Table |
| CSV_INPUT_FILE_ENCODING | Admin | Table |
| JSON_INPUT_FILE_ENCODING | Admin | Table |
| CSV_ERROR_THRESHHOLD | Admin | Table |
| JSON_ERROR_THRESHHOLD | Admin | Table |
| CSV_KEEP_FILES | Admin | Table |
| JSON_KEEP_FILES | Admin | table |
| CSV_TYPE_DETECTION_ROW_COUNT | Admin | Table |
| JSON_TYPE_DETECTION_ROW_COUNT | Admin | Table |
| CONTROL_FILE_READER | Admin | Table |
| VALIDATE_AFTER_SFTP_TO_LOCAL | Table | Table |
| VALIDATE_AFTER_LOCAL_TO_HDFS | Admin | Table |
| SEC_PARTITION_MERGE_RED | Admin | Table |
| VALIDATE_AFTER_HDFS_TO_HIVE | Admin | Table |
| CSV_MULTILINE_MODE | Admin | Table |
| TPT_DEFAULT_CHARSET | Global | |
| TPT_DELIMITER | Table | |
| TPT_FILE_ESCAPE_CHAR | Table | |
| TPT_FILE_QUOTE_ESCAPE_CHAR | Table | |
| TPT_FILE_ENCLOSE_CHAR | Table | |
| TPT_SCRIPT_PATH | Source | |
| TPT_EXPORT_SPOOL_MODE | Table | |
| TPT_CHECKPOINTS_PATH | Source | |
| TPT_LOG_PATH | Source | |
| TPT_CHARACTERSET | Source | |
| TPT_JOB_RESTART_LIMIT | Table | |
| TPT_CHECKPOINT_INTERVAL_IN_SECONDS | Table | |
| TPT_EXPORT_BLOCK_SIZE | Table | |
| TPT_EXPORT_TENACITY_HOURS | Table | |
| TPT_EXPORT_RETRY_INTERVAL_MINS | Table | |
| TPT_IO_BUFFER_SIZE | Table | |
| TPT_HADOOP_BLOCK_SIZE | Table | |
| TPT_EXPORT_MAX_SESSIONS | Table | |
| TPT_EXPORT_MIN_SESSIONS | Table | |
| TPT_EXPORT_OPERATOR_MAX_DECIMALDIGITS | Table | |
| TPT_EXPORT_READER_INSTANCES | Table | |
| TPT_EXPORT_WRITER_INSTANCES | Table | |
| TPT_UNICODE_MULTIPLICATION_FACTOR | Table | |
| TPT_ASCII_MULTIPLICATION_FACTOR | Table | |
| TPT_UTF8_MULTIPLICATION_FACTOR | Table | |
| TPT_UTF16_MULTIPLICATION_FACTOR | Table | |
| USE_TPT_SELECTOR_OPERATOR | Table | |
| IS_TIME_FORAMT_NEEDED | Global | |
| USE_TPT_GENERATED_SCHEMA | Table | |
| ENABLE_TPT_TRACE_LEVEL | Table | |
| USE_TPT_DESTINATION_AS_HDFS | Table | |
| USE_TPT_TDCH_INTERFACE | Table | |
| TPT_FILE_FORMAT | Table | |
| SOURCE_DATE_FORMAT | Source | |
| SOURCE_TIME_FORMAT | Source | |
| SFTP_STAGING_BASE_PATH | Table | |
| SFTP_BUFFER_SIZE | Source | |
| GZIP_FILE_EXTENSION | Source | |
| ENCODE_PRIMARY_PARTITION | Source | |
| DFI_DELETE_ORIGINAL_FILE_AFTER_DECOMPRESSION | Source | |
| export_multiplication_factor | Table/ Pipeline | |
| netezza_export_escape_char | Table/ Pipeline | |
| netezza_export_enclose_char | Table/ Pipeline | |
| netezza_export_null_value | Table/ Pipeline | |
| netezza_export_delimiter | Table/ Pipeline | |
| bcp_crawl_separator | Table/ Pipeline | |
| bcp_row_delimiter | Table/ Pipeline | |
| DF_SNOWFLAKE_VALIDATE_ROW_COUNT | Pipeline |
Updating Password for MongoDB and HIVE
Perform the following to encrypt and update password for MongoDB or Hive in the Infoworks DataFoundry system:
- Execute the following interactive bash script:
$IW_HOME/apricot-meteor/infoworks_python/infoworks/bin/infoworks_security.sh -encrypt -p - Enter the new plain text password when prompted.
- Copy the encrypted password displayed in the result and update in the Infoworks conf.properties file located in the $IW_HOME/conf folder.
Backup
This feature allows administrators to take a backup of the current metadata stored in MongoDB.
- In the System Configuration page, click Backup.
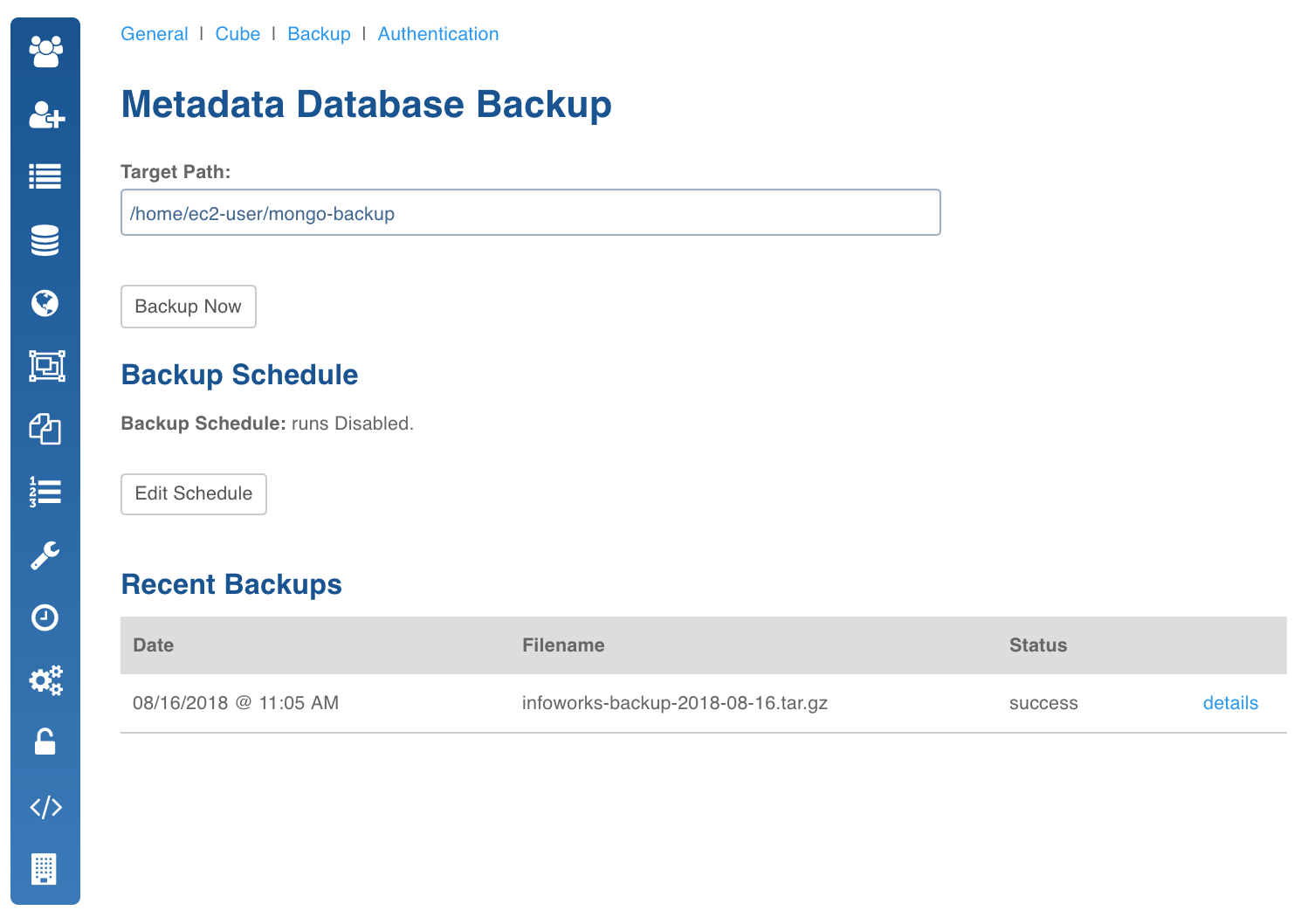
The Metadata Database Backup page includes two sections: Backup Schedule, Recent Backups
Backup Schedule
The backup can be taken immediately or it can be scheduled to run whenever required.
- The Backup Now button takes an immediate backup of the metadata and is disabled by default until the target path to store the backup is specified.
- To specify the target path click Edit Schedule, add absolute target path of local file system, configure any schedule if needed by selecting Enabled in Status dropdown.
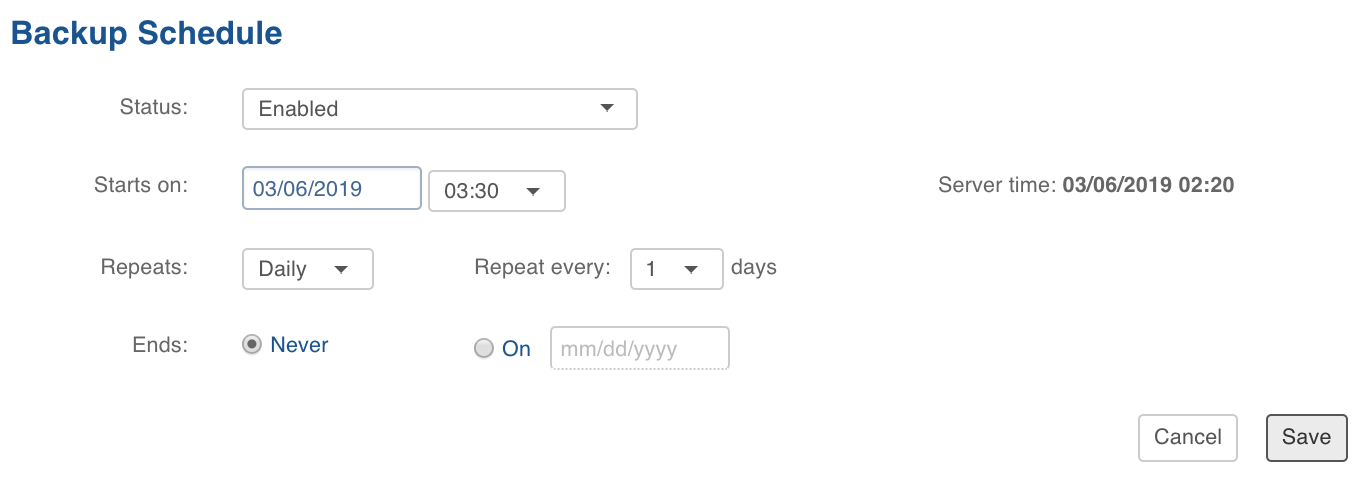
- Click Save to save the configuration.
- Click Backup Now to run the backup metadata job in the background. After successful completion of backup, an entry will be added in the Recent Backup view.
Recent Backup
The recent backup view displays the list of all previous backup of the Infoworks DataFoundry metadata.
- Date: Timestamp on which the backup was taken.
- Filename: Path of the file where the backup was taken.
- Status: Whether the backup was successful or not.
Notification
The Notification feature allows the admin to configure emails of success or failure of various jobs, and any issues with Infoworks DataFoundry installation.
NOTE: Email notifications require an SMTP server and an email account to send emails from.
This section describes the steps to configure the notifications.
- Open the platform-config.json file from the $IW_HOME/ platform/conf folder.
- Set the following configurations in the messaging-service section as required.
- Edit the
smtpUsernameandsmtpHostparameters with required values. If the email address provided in the smtpUsername parameter is of a Gmail account, do not make any change to the smtpHost value. - Provide the AES encrypted email password for the specified email address as the smtpPassword. If no password is setup for the specified email ID, provide the AES encrypted empty string.
- To encrypt the password, run the following command :
$IW_HOME/apricot-meteor/infoworks_python/infoworks/bin/infoworks_security.sh -encrypt -p <yourpassword> - Restart services using the following commands:
$IW_HOME/bin/stop.sh platform
$IW_HOME/bin/start.sh platform