This feature exports pipelines and sources to HDFS or cloud storage in CSV format with UTF-8 encoding.
After navigating to the required source, configure the existing tables by clicking the Configure button present to the right of the respective table name. On clicking Export, the Export tab appears which allows configuration of the delimited file export settings.
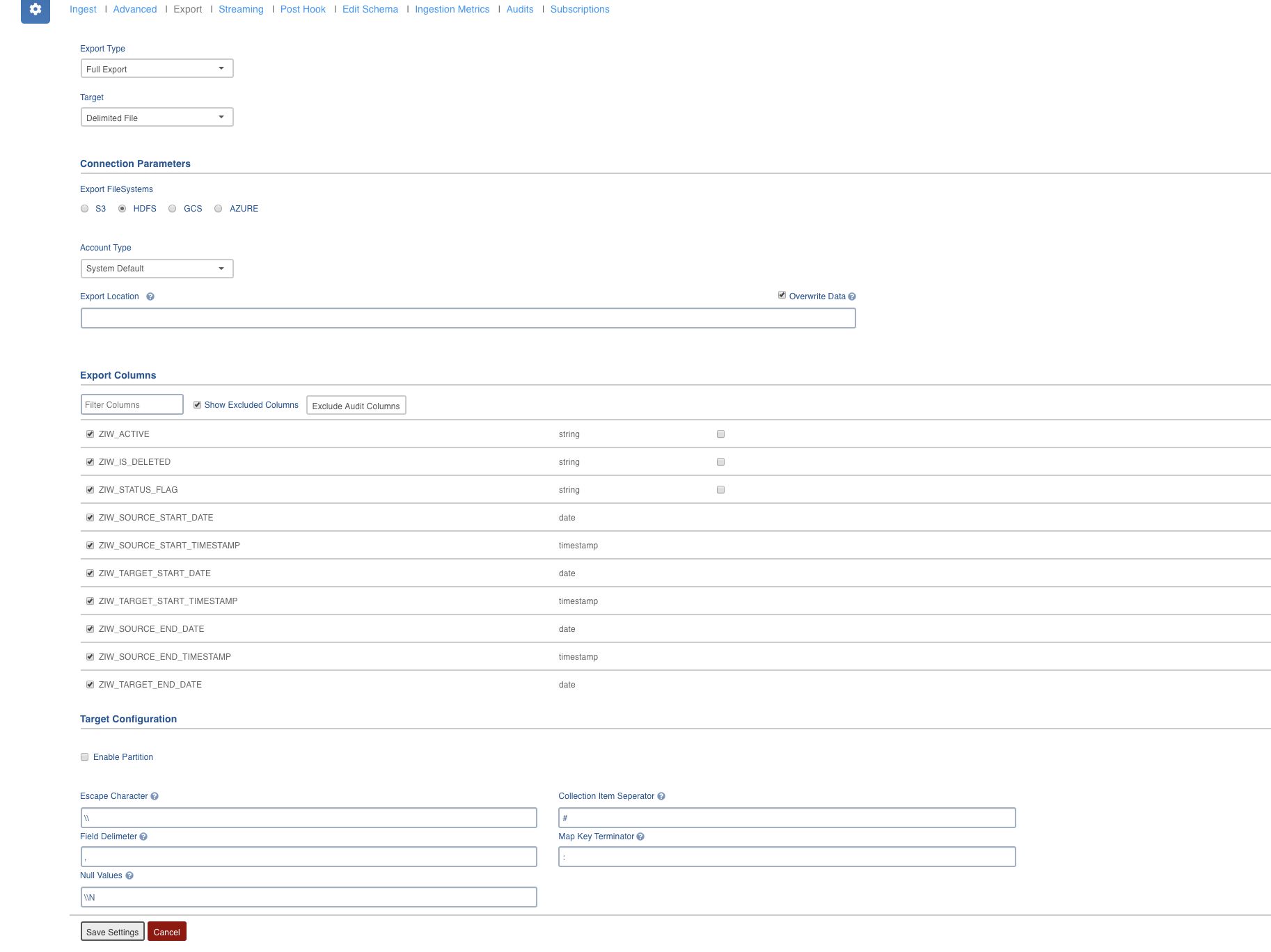
Field Description
| Field | Description |
|---|---|
| Export Type | Select Full Export/Incremental Export. |
| Target | Select the database type to be exported as Delimited File. |
| Export FileSystems | Select the storage system to export data. The options include S3, HDFS, GCS and Azure. For details on each export filesystem, see Export FileSystems. |
| Account Type | Authentication mechanism based on the storage system. |
| Export Location | Absolute URI of the location where data will be exported. In the Export Location field, ensure that all tables must have different export locations at a single point of time. |
| Overwrite Data | You must select the Overwrite Data checkbox to forcefully overwrite the existing target path. This must be set at table level. The default value is false. |
The final path of export will be a sub directory under the specified path based on the export type. For full export, the final path will be s3://bucket/path/to/export/full/csv. For incremental export, the final path will be s3://bucket/path/to/export/cdc/csv/, where timestamp refers to export job time.
NOTE: Full export overwrites existing full export data in the same path, while incremental data always writes to a new path using the timestamp in the path.
| Field | Description |
|---|---|
| Export Columns | List of columns to be exported. |
| Enable Partition | Option to enable partitioning. |
| Select Partition Column | Option to select partition column when partitioning is enabled. |
| Field Delimiter | Single character input for field delimiter. The default value is , |
| Escape Character | Single character input to escape other control characters in column values. The default value is \ |
| Collection Item Separator | Field separator for struct, array and map complex data types. The default value is # |
| Map Key Terminator | Key value separator for map data type. The default value is : |
| Null Values | Substitution for null column values. The default value is \N |
Limitations
- Partition Key: Only one partition key can be used per export job. The data type of the partition key column must be primitive and not complex (like map, array). Number of partitions supported depends on the Hive settings. For more details, see the hive.exec.max.dynamic.partitions.pernode configuration.
- Default Partition Name: All data with null partition values will be moved to a directory with default partition name. Special characters must be avoided - semicolons will be removed. The default value is HIVE_DEFAULT_PARTITION.
- Delimited file parameters: The parameters like field separator, escape character, etc must be a single UTF-8 character; multiple characters are not supported. Back slash in these options must be escaped. Quote characters are not supported, but quotes can still be added as part of the pipeline.
Troubleshooting
IW Constants and Configurations
- export_fs_data_overwrite: When set to true, this configuration forcefully overwrites the existing target path. The default value is false.
NOTE: When trying to export tables with the same export location, the job might fail or succeed based on the overwrite parameter.
WARNING: All existing data will be deleted.
Export FileSystems
S3
For S3 export filesystem, provide the following details:
- Account Type: Authentication mechanism based on the storage system. The System Default option uses the credentials globally available in the system or available to the Infoworks user. Before selecting the System Default option, you must set up the access key as
fs.s3.awsAccessKeyIdand secret key asfs.s3.awsSecretAccessKe,for EMR in the hdfs-site.xml file of the Hadoop configuration, with the corresponding values for the bucket to which the data must be exported. For all other Hadoop distributions, set access key asfs.s3a.access.key, and secret key as:fs.s3a.secret.key. If AWS Key Based is selected, provide the Access Key and Secret Key. The keys must have write access to the given bucket. For details on the keys, see Managing Access Keys for IAM Users. - Export Location: Absolute URI of the location where data will be exported. This path must contain the file scheme, bucket name (if applicable) and absolute path to the export directory. For example, s3a://bucket/path/to/export
HDFS
For HDFS export filesystem, provide the following details:
- Account Type: Authentication mechanism based on the storage system. The System Default option uses the credentials globally available in the system or available to the Infoworks user.
- Export Location: Absolute URI of the location where data will be exported. This path must contain the absolute path to the export directory. For example, hdfs://namenode-ip.fqdn/path/to/export
GCS
NOTE: You must have a GCS storage account created to begin this process. To create a new GCS account, see Creating and Managing Projects.
For GCS export filesystem, provide the following details:
- Account Type: Authentication mechanism based on the storage system. The System Default option uses the credentials globally available in the system or available to the Infoworks user. If GCS Service Account Credential is selected, provide the path of the Service Account Credential File. For example, /iw_home/infoworks/path/to/file
- Project Id: The project ID of the GCS account. For details on obtaining project ID, see Identifying projects.
- Export Location: Absolute URI of the location where data will be exported. This path must contain the bucket name (if applicable) and absolute path to the export directory. For example, gs://bucket/path/to/export
NOTE: Ensure to provide storage permissions for Dataproc and target bucket for given credentials and user.
Azure
For Azure export filesystem, provide the following details:
- Account Type: Authentication mechanism based on the storage system. The System Default option uses the credentials globally available in the system or available to the Infoworks user.
If WASB is selected, provide the following:
NOTE: You must have an Azure WASB storage account created to begin this process. To create a new WASB account, see Create Storage Account.
- Account Name: Account name for the desired storage account.
- Access Key: Access key with write access for the storage account. Navigate to the desired storage account. In the left panel, go to Access Keys. Copy value from either Key1 or Key 2 fields. For more details, see Managing Storage Account.
- Container Name: Name of the desired container in the storage account. For more details, see Creating a Container.
- Export Location: Absolute URI of the location where data will be exported. This path must contain the container name and absolute path to the export directory. For example, wasb[s]://@.blob.core.windows.net/path/to /export,
If ADLS Gen1 is selected, provide the following:
NOTE: The ADLS account name must be adls gen 1.
- Authentication End Point: Provide the authentication end point as OAuth 2.0 token endpoint. For details, see Getting OAuth 2.0 token endpoint.
- Application Id: Application ID of the desired directory.
- Client Secret: Client secret to authenticate the application.
For details on obtaining Client Secret and Application ID, see Creating Azure Active Directory Application.
- Export Location: Absolute URI of the location where data will be exported. This path must contain the absolute path to the export directory. Following are some examples, adl://gen1_accountname.azuredatalakestore.net/path/to/folder/.