Infoworks Data Transformation is used to transform data ingested by Infoworks DWA for various purposes like consumption by analytics tools, DF pipelines, Infoworks Cube builder, export to other systems, etc.
For details on creating a domain, see Domain Management.
Following are the steps to add a new pipeline to the domain:
Click the Domains menu and click the required domain from the list. You can also search for the required domain.
In the Summary page, click the Pipelines icon.
In the Pipelines page, click the New Pipeline button.
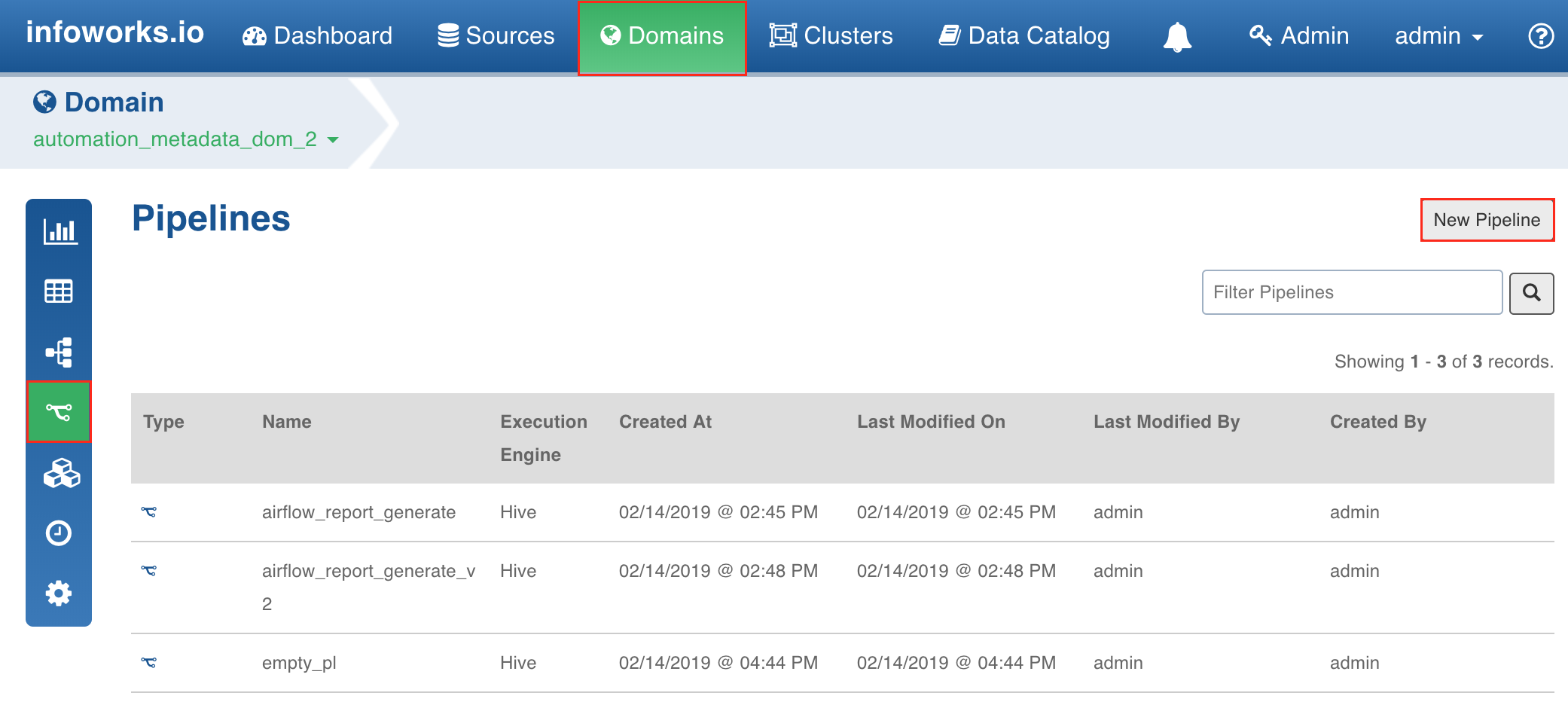
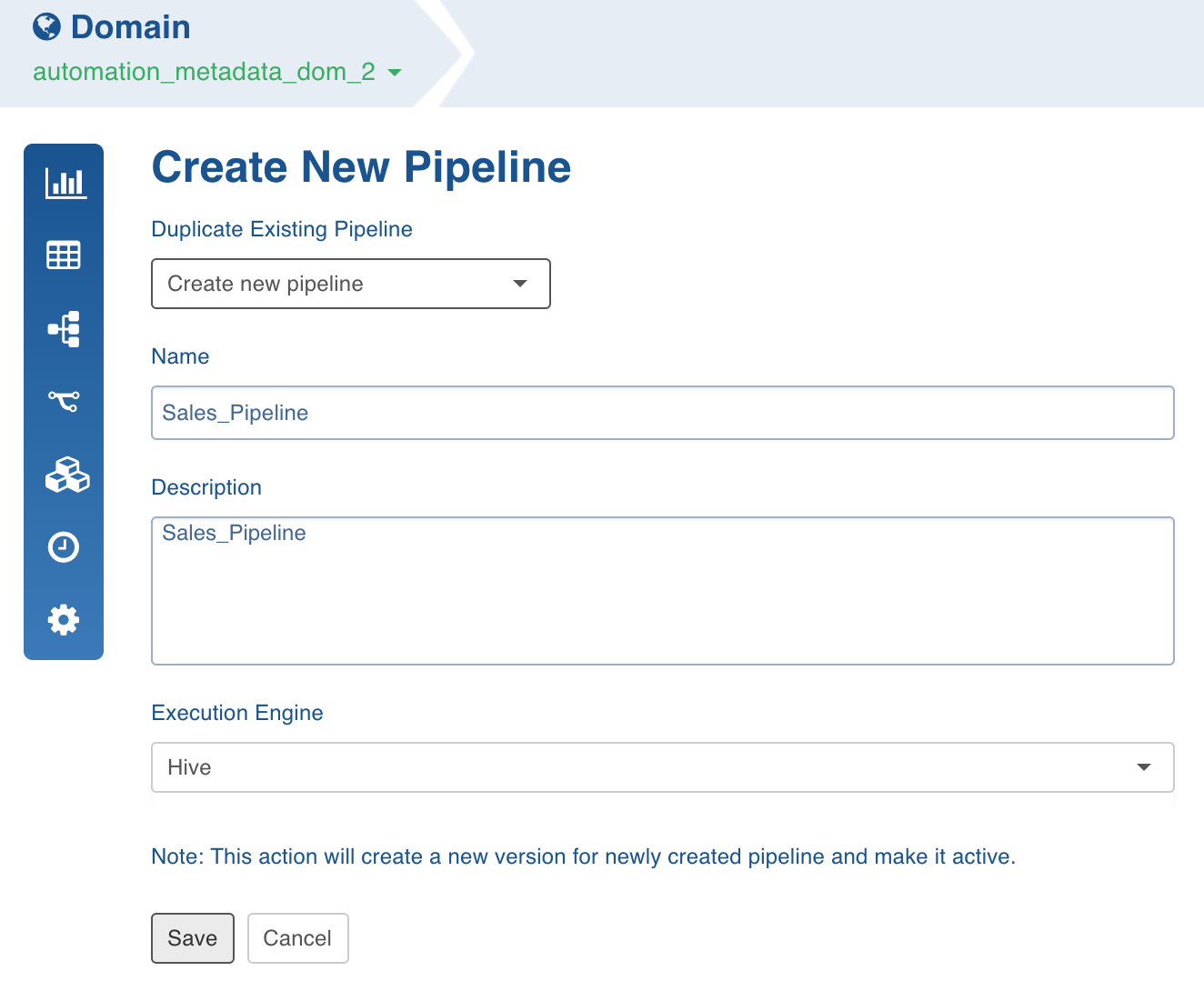
In the New Pipeline page, select Create new pipeline.
To duplicate an existing pipeline, select the pipeline from the Duplicate Existing Pipeline drop-down list and enable the checkbox to retain properties such as target table name, target schema name, target HDFS location, analytics model name, analytics model HDFS location, MapR-DB table path in import.
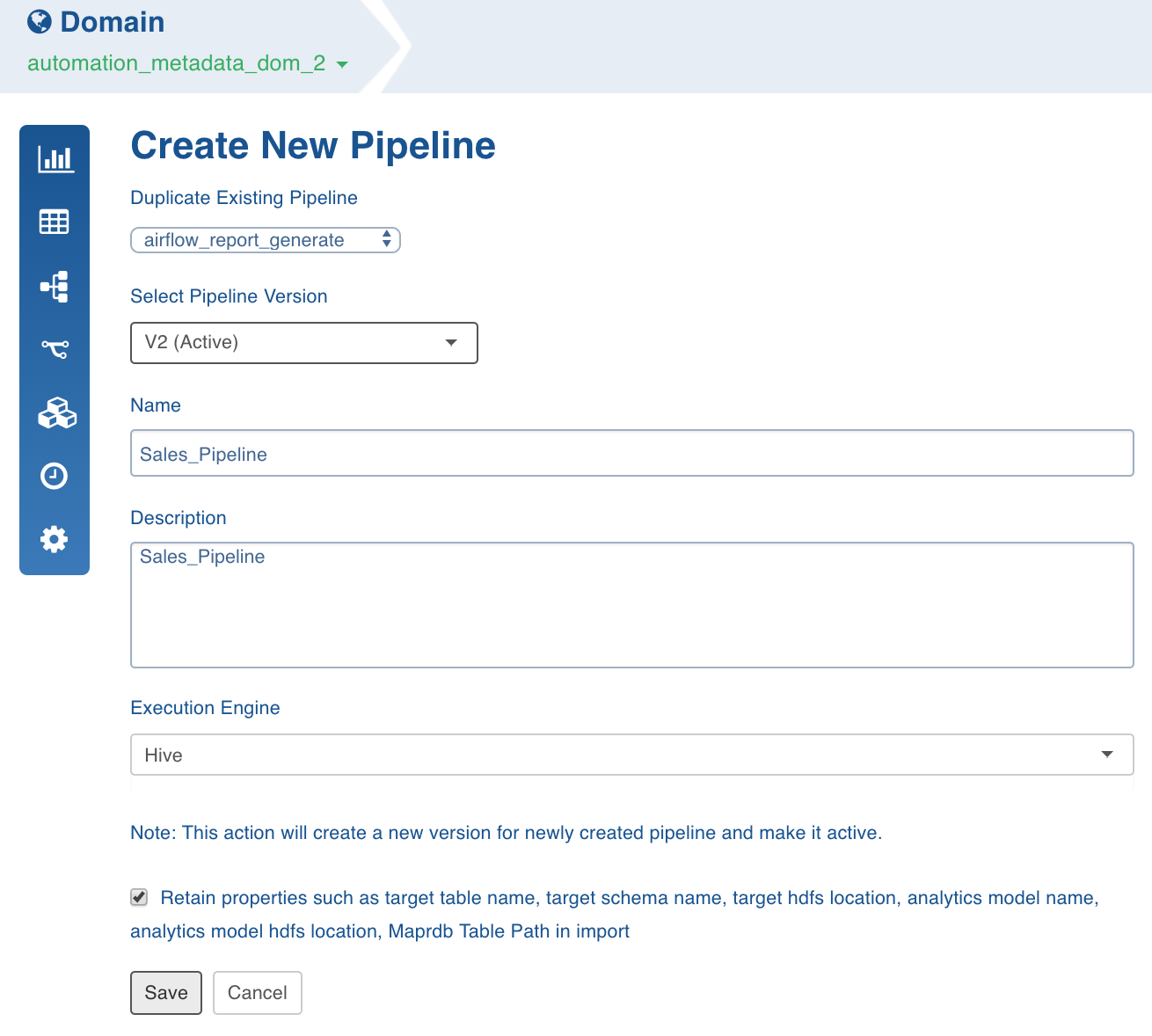
Enter the Name and Description.
Select the Execution Engine type. The Execution Engines supported are Hive, Spark and Impala.
Using Spark: Currently v2.0 and higher versions of Spark are supported. Spark as execution engine uses the Hive metastore to store metadata of tables. All the nodes supported by Hive and Impala are supported by spark engine.
Known Limitations of Spark
Parquet has issues with decimal type. This will affect pipeline targets that include decimal type. Recommend to cast any decimal type to double when using in a pipeline target
The number of tasks for reduce phase can be tuned by using sql.shuffle.partitions setting. This setting controls the number of files and can be tuned per pipeline with df_batch_sparkapp_settings in UI.
Column names with spaces are not supported in Spark v2.2 but supported in v2.0. For example, column name as ID Number is not supported in spark v2.2.
Using Impala: Impala as execution engine is supported on CDH. To Enable Impala as execution engine in Pipelines, set the cdh_impala_support configuration to true in Admin page.
Click Save. The new pipeline will be added to the list of pipelines in the Pipelines page.
Best Practices
For best practices, see General Guidelines on Data Pipelines.